Hypothetical Objective: Requirement is whenever a Job Requisition is created for a Replacement, the Minimum and Maximum Salary should be autopopulated with the desired amount.
Solution: Using the DellBoomi AtomSphere one can quickly and painlessly integrate data between all of your key HR functions but it can also be used as a powerful tool to query/update data within SuccessFactors .
In this case, Job requisitions for “Replacement” cases are identified using a field in the job requisition whose value will be read and compared with the desired value to populate the Minimum / Maximum salary field.
This approach can be utilized to fulfill other requirements in various other modules like EC, PM/GM, Recruitment.
This process created in DellBoomi can then scheduled to trigger depending on the desired frequency.
Integration with DellBoomi is achieved in 3 simple steps here:
- Build
- Deploy
- Manage
Building the connection
(1) Before we get going with Boomi, we need to make sure the following settings have been enabled in provisioning:

(2) Create an API user in BizX with the following permisisions and assign “SFAPI User Login” permission (General User Permission) and “Employee Data” (View and Edit permission).![]()
(3) Grant “Manage Integration Tools” permission to Admin.
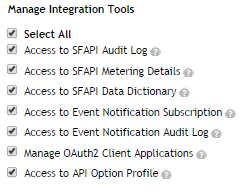
(4) In Admin Tools, search for SFAPI data dictionary to get a list of entities that are available through the SFAPI and analyze the possible operations that can be applied on each field of an entity.
(5) Log into https://platform.boomi.com/.
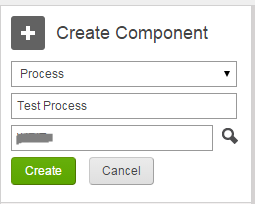
(6) The first step is to get started and build an integration process. Give your process a name and click the “Create” button :
(7) As our objective is to get the details of the Job Requisition first, we will be fetching the values of our Job Requisitions for the required Job Requisition Template to identify a replacement case. Next screen will prompt you to enter the details:
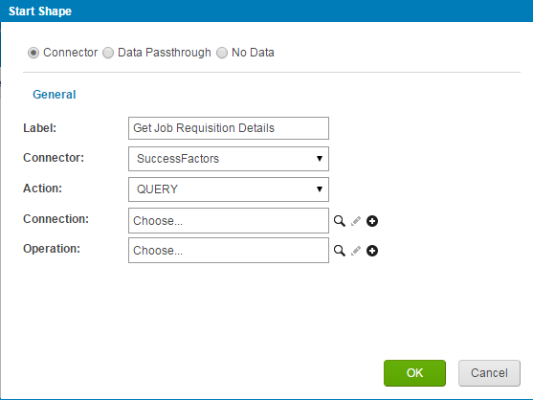
- Give a label to the start step.
- Choose “SuccessFactors” in the dropdown available for connector.
- “Query” will be chosen in the Action dropdown.
- The Connection is where we specify the data center, company id and credentials for executing SFAPI transactions. Connecting to an existing company id requires both the endpoint URL to the data center and the company Id specifying a specific instance in the data center.
- From the above example click + the symbol in front of the connection and enter the details as below:
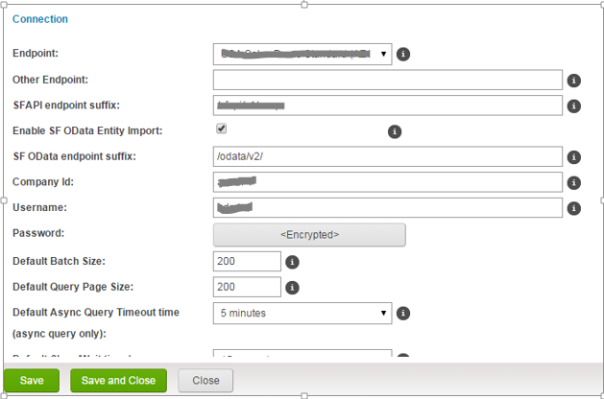
- Enable SF OData Entity Import if you wish to access the SF OData API in addition to the SFAPI.
(8) Now specify the operation.The Operation specifies the action that will be performed and the object type on which that action will be performed.The supported actions are:
- Query (OData and SFAPI) – Read a set of objects optionally sorted and limited to those records that meet a specified search criteria(filter).
- Create (SFAPI only) – Insert a new record. This operation returns the new ID of the inserted object.
- Update (SFAPI only) – Update the specified field values of an existing record. The ID specifies the record to update.
- Delete (SFAPI only) – Remove the record. The ID specifies the record to delete.
- Upsert (SFAPI only) Write a record specified by a unique External ID. If a record with that external ID exists, the record will be updated. Else a new record will be created.
In this step we are going to perform a query operation and use the “Import” feature. Click the Import button.
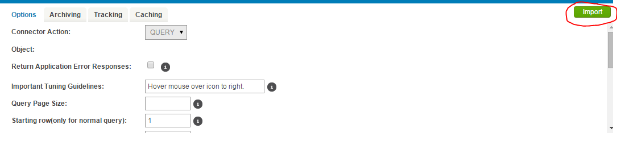
Enter the details as following:
- Specify the connection we created above
- Choose the module, for which you wish to get the details of. You could also
- choose to enter the entity name.
Click Next.
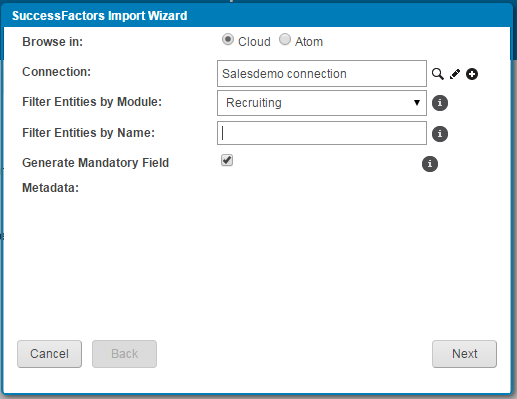
It will now ask you to select the object type. “Object Type” is synonymous with “entity”. Boomi’s preferred term is “object” while the SuccessFactors SFAPI materials refer to “entities”. You will now select the Job requisition template or Entity and click the Next button.
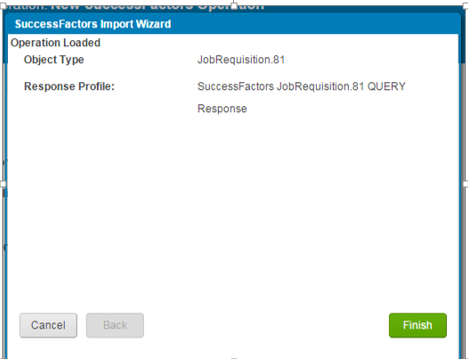
You will get the below message . Click the finish button.
(9) Next step is to build the decision shape. Choose the decision shape from the left panel and drag and drop to the process area.
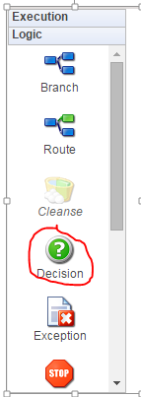
As per our requirement we will now have to separate out the requisition based on values for field – newrepl (Addition or Replacement).
Our condition is, If the “newrepl” value = “Replacement”, do this else do that and the properties will be:
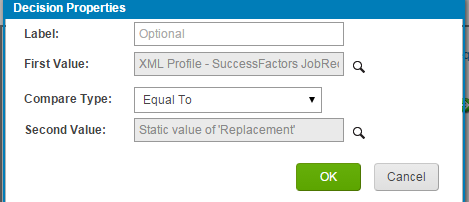
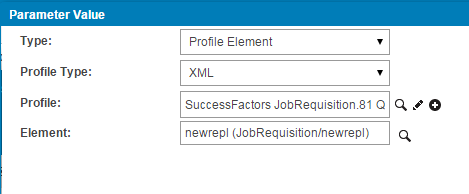
In order to define the first value , follow the below steps:
- Choose the Type as Profile Element.
- Profile Type will be xml.
- Profile will let you choose the entity along with the operation.
- Element will be the field of the entity.
In order to define the second value, follow the below steps:
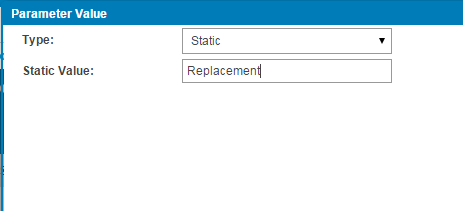
- Choose the Type as Static.
- Enter the desired value.
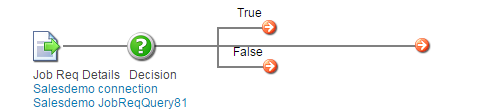
(10) Now that we have specified the decision properties, our process looks something like below:
(11) Next step is to add the mapping properties and update the requisition. Map functions allow transformation logic to be applied to individual field values as they are being mapped. For which we will drag and drop the map function to the true branch in the above process area:
![]()
(12) In order to map, source and target profiles should be created. For which we need to follow the below steps:
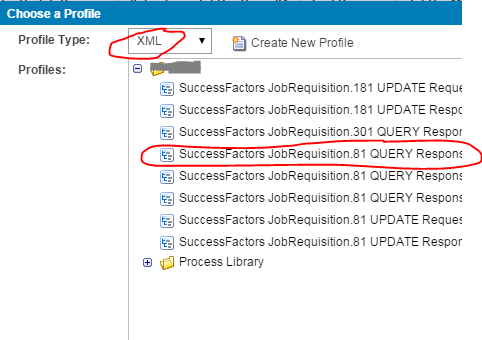
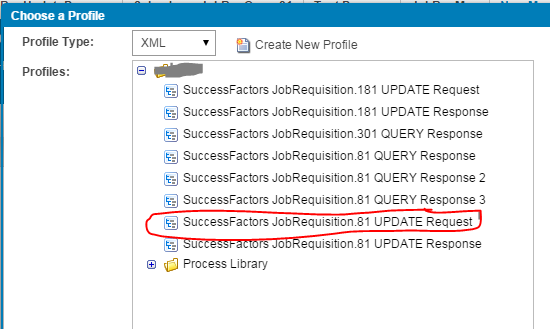
- Click the plus sign in the source profile section to create a source profile.
- Add “xml” in the “Profile Type” and then choose the appropriate query response profile.
(13) Our profiles are now ready to be mapped. The mapping will happen on the key fields, which in our case is the Job requisition ID. During the mapping process, we can create numerous function to transform the values of source profile to mirror the value as in the destination profile. For example in our case, Job requisition ID in source profile was in the format Template-Id which needed to be splitted at ‘-’ and only the ID needed to be mapped with the destination ID. This was accomplished using the “String Split” function:
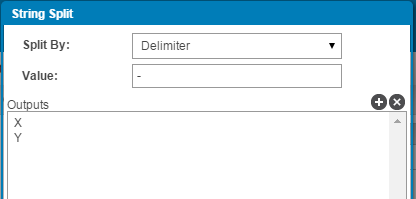
(14) Now we simply need to drag the field from our source profile and match with the field sitting in the destination profile.Our mapping now looks something like this:

- In order to set the default value of the fields – Salary Min. and Salary Max. , choose the blue arrow mark against the field and set the default value to be the desired value.
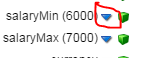
(15) Our last step is to add the connector to perform the “Update” Operation.Just like we created a connector for “Query” we are similarly going to create an Update connector like below:
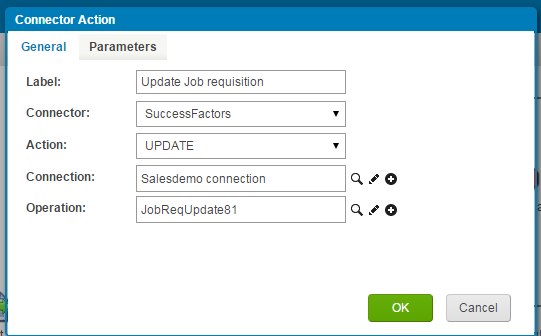
- Choose “Update” in the Action dropdown.
- Choose the previously created connection by clicking the search icon.
- Create an operation for update just like we created an operation for query by clicking the + icon.
(16) The process should now be completed by adding a stop shape in the end. And our process now looks like this :
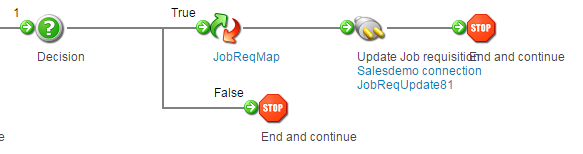
Note that per the above query multiple requisitions are retrieved and updations to multiple requisitions happen on an asynchronous basis.
(17) The process can include several complex components and include branching for multiple conditions like below :
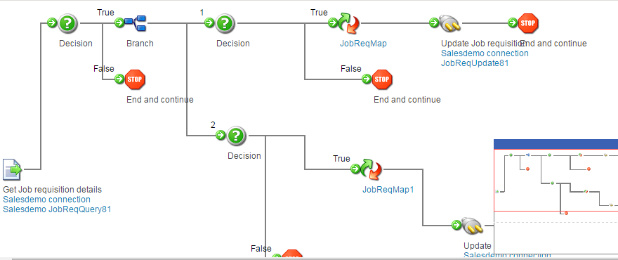
(18) Now it’s turn to test the connection . Choose the option on the top most right corner – “Run a Test”. It will prompt you to select the desired atom. Choose the atom and run the test. Atoms are the runtime engines that are required to deploy the integration process.
Successfully run process will look like this:
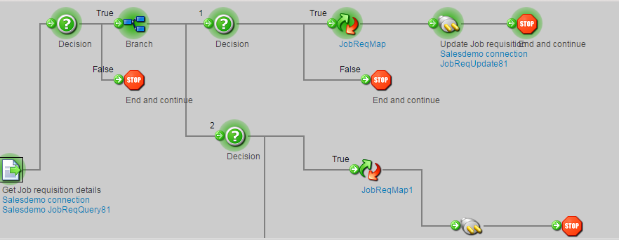
(19)The bottom section will give you the results of the test run with the logs and the associated documents:
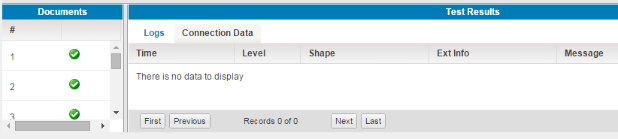
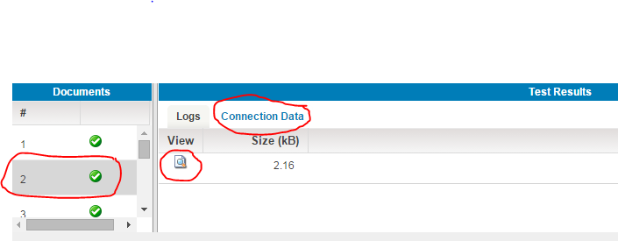
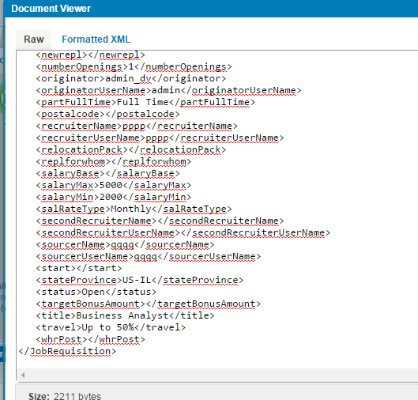
(20) We will now select the document, choose the “Connection Data” tab and click the search icon to display the results.
Deploy
The Deploy page allows you to attach Atom (s) to a specific process for strategic management and to deploy the latest revision of a process. A single process can be deployed to multiple Atoms and a single Atom can contain many deployed processes. If environments are enabled in your account, you can attach and deploy processes to a specific environment.
Manage
The Manage menu provides a consolidated view of all the integration activity within your account for deployed processes. This includes Atom and Cloud status and historical process execution results. You can view data that has been processed and troubleshoot errors. Each time a process runs, the results of that execution and detailed logs are collected by Dell Boomi AtomSphere and displayed here.
When you click the Manage menu you can select one of the following:
- Process Reporting
- Atom Management
- Cloud Management (if it is enabled for your account)
- Boomi Assure (if it is enabled for your account)
- Process Library (if it is enabled for your account)
- Integration Packs (if it is enabled for your account)