Intro
Any SAP customer deciding to build Cloud Applications has many options these days; many are quite challenging to explain. SAP provides a development environment based on which applications are built. The SAP solution covers the entire lifecycle, from the development, CI/CD, and scalability using Hyperscalers or SAP’s data centers.
For the same reason, many customers decide to build applications on a public cloud provider, and then the decision is on which cloud provider they will develop their applications. Sometimes in more than one cloud provider.
So, cloud adoption boomed some time ago, and SAP (Financial and Operational data) application started to move to the cloud, where the rest of the data is generated.
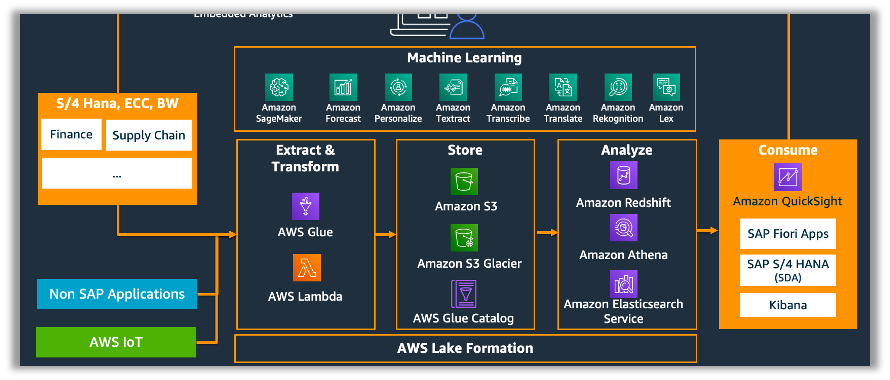
Irrespective of the customer decides to migrate an SAP system to AWS or leave it on-prem, many customers deploy AWS applications. They want the option of creating analytics from SAP or SAP HANA and build an Amazon S3-based data lake while still using SAP as their primary source of transactional or analytical data.
Amazon Simple Storage Service (Amazon S3) offers SAP customers a compelling reason to use this service as a storage layer for a data lake on AWS with its durability and cost-effectiveness.
There can be many scenarios for federating queries from SAP HANA to a data lake on AWS. Here are some specific examples
- Utilities industry: Store electricity-relevant data consumption in a data lake on AWS and federate SAP HANA queries to predict future energy consumption.
- Retail: Store social media activity in a data lake on AWS, match the action with customer tickets in SAP CRM for analysis, and improve customer satisfaction.
- The retail industry, analyzing data from an e-commerce website and crosses it with inventory/stock from the SAP system using ML algorithms and patterns.
There are several documented ways to consume AWS services from the SAP platforms, products, and services. Depending on the options we have in our hands, the ways to extract SAP data fall under one of the following categories.
- Data Extraction from DB level (HANA)

Using AWS Glue and AWS Lambda brings a direct license benefit among third-party adapters, usually complex, expensive, and requiring extra infrastructure. There is an additional custom development effort in any case since the context of what data is being copied (SAP data model is complicated to understand) requires expertise.
- Data Extraction from S4/HANA, BW/4HANA, SAP Business Suite. The application level.

We hold much more context using application-level extraction than DB extraction since the table relationships or customizations are kept. SAP usage of IDocs is widely documented and still in use, and the level of Function modules, BAPIs, and APIs is continuously increasing. An additional development effort is needed in any case (including Data Services) and a licensing requirement.
It can be a complicated decision to choose a tool, product, or service. The different options between Data Intelligence tools and Data Intelligence platforms available in the market are quite big.
- Data Intelligence tools can be SAP SLT, SAP Data Services, SAP SDI, or SAP CPI, to name a few.
- Data Intelligence platforms are SAP Data Intelligence (aka SAP Data Hub), Azure Data Factory, Informatica, IBM DataStage, SSIS, Talend, or Mulesoft, to name a few.
The official SAP path these days (it changes frequently) allows us to use HANA (the DB), SAP Business Technology Platform (AKA SAP Cloud Platform, the PaaS), or SaaS like SAP Analytics Cloud to Amazon, using any modeling tool of choice.
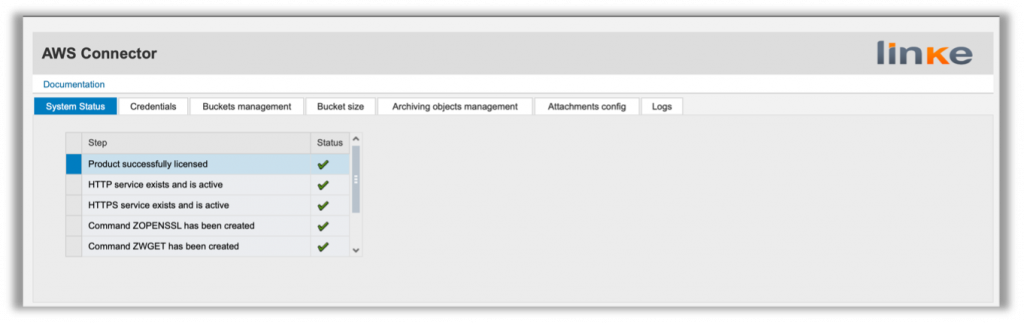
Introducing the AWS Connector for SAP
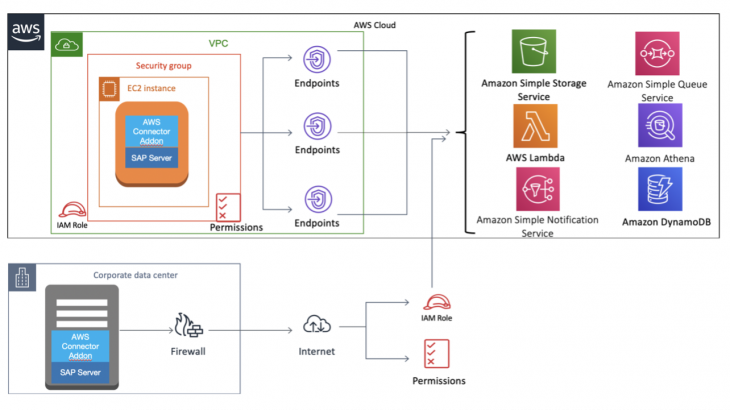
But there is also an add-on that connects SAP Netweaver and S4HANA to AWS services.
The tool, called AWS Connector for SAP, enables businesses to integrate on-premises or cloud-based SAP systems with Amazon services Amazon S3 through an ABAP add-on. It’s basically the ABAP SDK for Amazon.
What is ABAP SDK for Amazon?
Many large enterprise customers use SAP to run their business. There is a growing need to integrate SAP applications into the cloud. With AWS gaining popularity with enterprise customers, integrating SAP to AWS natively looks like a basic requirement and customer demand.
Developing Z code programs SAP installations require in-depth knowledge of security and Integration patterns of the respective Amazon services, making it complex for enterprises to integrate SAP with Amazon services. To overcome this challenge, the ABAP SDK for Amazon simplifies the SAP integration with Amazon and is the only certified add-on available that connects SAP to Hyperscalers.
This SDK is built using SAP’s proprietary language ABAP and its supporting configuration tools. The framework enables the programmer to integrate with Amazon services by abstracting the complexity like authentication, shared access tokens, or security.

Not only allowing businesses to simplify their SAP architecture, but it also helps reducing infrastructure costs, keeps pace with rapid data growth, and at the same time improve agility and flexibility.
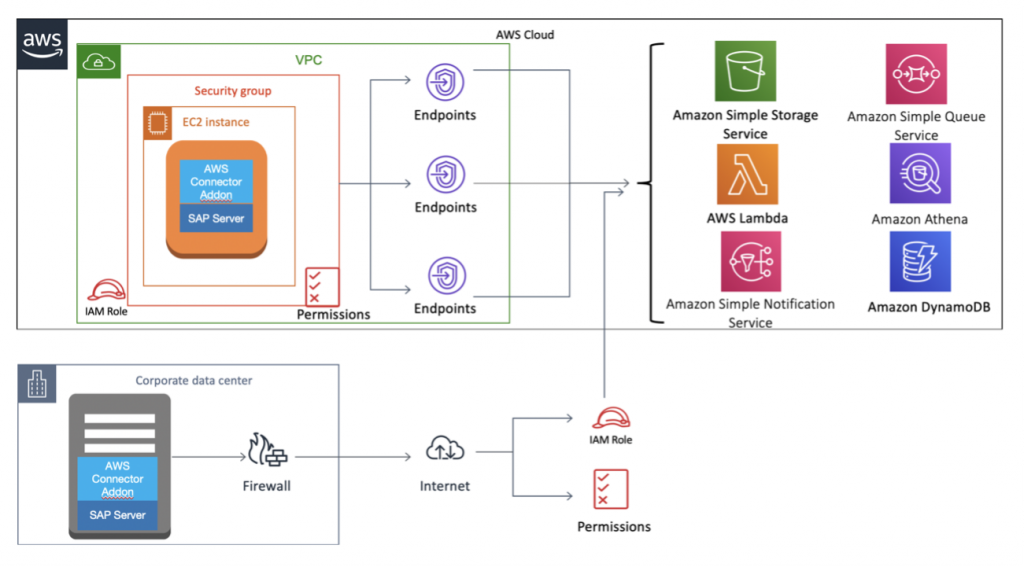
The AWS Connector for SAP is officially certified by SAP and listed on Amazon Web Services marketplace and SAP Store. It has been developed prioritizing security, implementing the existing tools and best practices for communication encryption (TLS v1.2), authorization management (AWS IAM), and data encryption using proprietary keys stored in the SAP system (STRUST) or stored in external services (AWS KMS).
The program /LNKAWS/AWS_STRUST will take care of it and run periodically to update the required certificates once they are modified.

The add-on is SAP Archivelink Compatible and provides built-in WebDynpro and Fiori apps for customizing and management. Before describing the possible use cases, let’s go through the Amazon services.
It’s managed through transaction /LNKAWS/S4MANAGER and allows actions like;
– Create, edit and delete users.
– Create, edit and delete buckets.
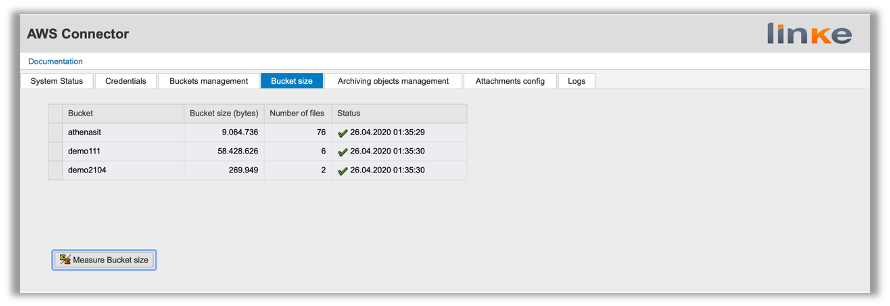
– Measure bucket sizes.
– Link archiving objects to buckets.
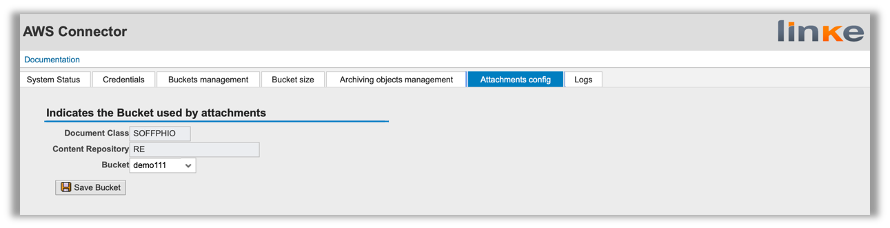
– Assign attachments to a bucket.
Amazon S3

Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. For an SAP customer, S3 might be the most essential service to connect to. Why?
For many organizations, SAP systems represent some of their most critical, deeply integrated workloads. As such, these organizations must ensure that the IT resources supporting their SAP systems are available, performant, secure, and reliable. Meeting these requirements about storage commonly necessitates businesses provisioning an SAP-certified and setup storage infrastructure with high performance and availability.
Leveraging these types of storage resources at choice can create a costly and complex architecture for IT teams to run and manage, plus the ever-growing quantities of business data extrapolate this challenge. On top of cost and complexity, businesses risk bottlenecking operations if their data outgrows their storage resources. Because SAP workloads are typically central to numerous departments, roles, and key processes — poor performance can have a devastating impact on a large portion of the business. To overcome these challenges, organizations need storage resources that fulfill the demands of their critical SAP workloads while also infusing greater agility, flexibility, and cost-effectiveness.
To help businesses solve the challenges detailed above, many are looking to cloud storage from Amazon S3.
Amazon S3 is an object storage service that allows companies to securely collect, store, and analyze their data at a massive scale. By leveraging Amazon S3, businesses can right-size their storage footprint and scale elastically while paying only for the resources they use. This eliminates the need to over-provision storage capacity and thus, creates a cost-efficient environment while also providing the scalability to support large SAP systems data infusion.
Technically, the solution also helps organizations improve the reliability of their storage implementations, as Amazon S3 is designed to deliver 99.999999999% durability.
As of 2021, the AWS global footprint spans 77 Availability Zones (AZs) within 21 geographic Regions around the world. This widespread presence makes it easier for customers leveraging Amazon S3 to store data in a geographically redundant, highly-available, and disaster-tolerant manner. When storing data in Amazon S3, objects are automatically distributed across a minimum of three AZs that are typically miles apart within a Region.
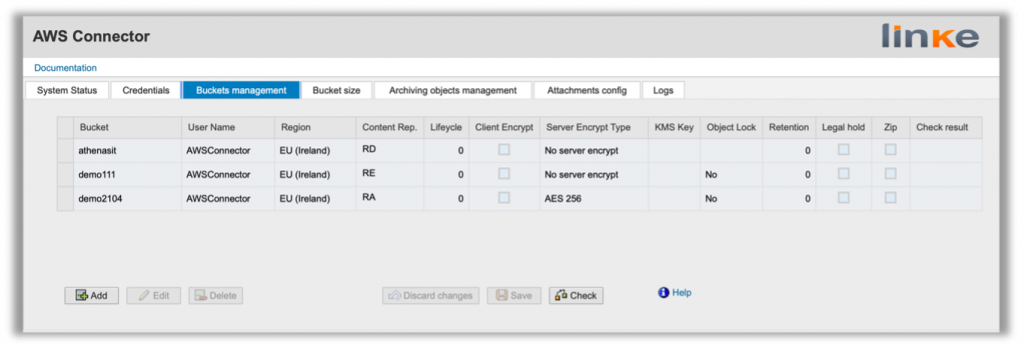
The AWS Connector allows to perform the following actions with the AWS S3 service:
- Create, Modify and Delete Buckets.
- Storage Documents.
- Display Documents.
- Get the size of the buckets.
AWS Lambda

AWS Lambda allows running code without provisioning or managing servers. Pay only for the consumed compute time – there is no charge when the code is not running.
The AWS Connector allows performing the following actions with the AWS Lambda service:
- List Functions.
- Add Tags in the functions.
- Invoke Functions.
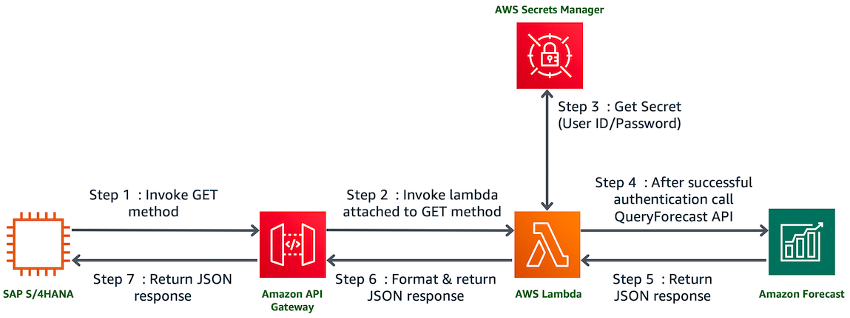
Amazon Forecast is a fully managed service that uses machine learning to deliver highly accurate forecasts. Today, companies use simple spreadsheets to complex financial planning software to forecast future business outcomes such as product demand, resource needs, or financial performance. These tools build forecasts by looking at a historical data series, which is called time-series data.
Amazon Forecast uses machine learning to combine time series data with additional variables to build forecasts. Amazon Forecast requires no machine learning experience to get started. By providing historical SAP data, plus any additional data that may impact the forecasts, Amazon Forecast will automatically examine it, identify what is meaningful, and produce a forecasting model capable of making predictions that are up to 50% more accurate than looking at time series data alone.
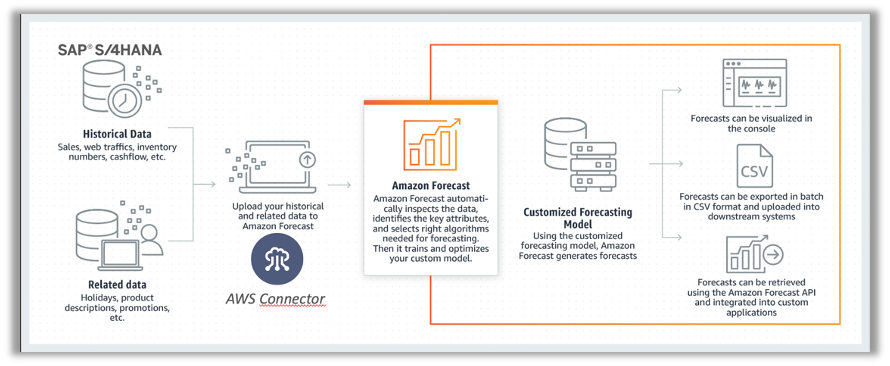
Product Demand Planning
Amazon Forecast to forecast the appropriate inventory levels for various store locations. By providing Forecast information like historical sales (SD01, VA05N), pricing (KONV, KONP), store promotions, store locations, and catalog data from SAP into Amazon S3 storage, combine that with associated data like website traffic logs, weather, and shipping schedules. Amazon Forecast will use that information to produce a model that can accurately forecast customer demand for products at the individual store level.
Financial planning
Amazon Forecast can forecast key financial metrics such as revenue, expenses, and cash flow across multiple periods and monetary units. Uploading SAP historical financial time series (BKPF, BSEG) data to Amazon S3 storage and then import it to Amazon Forecast. After producing a model, Amazon Forecast will provide the expected accuracy of the forecast so that we can determine if more data is required before using the model in production. The service can also visualize predictions with graphs in the Amazon Forecast Console to help us make informed decisions.
Amazon SNS and SQS

Amazon Simple Notification Service (SNS) is a highly available, durable, secure, fully managed pub/sub messaging service.
Amazon Simple Queue Service (SQS) is a fully managed message queuing service.
Both SNS and SQS decouple and scales microservices, distributed systems, and serverless applications.
Using SQS, we can send, store, and receive messages between SAP and AWS at any volume, without losing messages or requiring other services to be available.
SQS offers FIFO or Standard message queues.
The AWS Connector allows to perform the following actions with the Amazon SNS service:
- Create and Delete Topic.
- Subscribe and Unsubscribe Topic.
- List topic.
- List queue
- Tag Queue
- Send Message
Amazon DynamoDB

Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale.
The AWS Connector allows to perform the following actions with the AWS DynamoDB service:
- Create and Delete Table.
- Insert Items.
- List Table.
- Query Table
Amazon DynamoDB is fully managed and multi-region. It can handle more than 10 trillion requests per day and support peaks of more than 20 million requests per second.
This is one of the most popular AWS services, with thousands of AWS customers choosing DynamoDB as their key-value and document database for mobile, web, gaming, ad tech, IoT, and other applications that need low-latency data access at any scale.
Amazon Athena

Amazon Athena is an interactive query service that makes it easy to analyze Amazon S3 data using standard SQL. Athena is serverless, so there is no infrastructure to manage, only paying the queries that run.
The AWS Connector allows to perform the following actions with the AWS Athena service:
- Create and Delete Database.
- Create and Delete Table.
- List Databases
- List Tables.
Athena is the go-to service to run federated queries to an Amazon S3–based data lake.
Common Use Cases
Each business uses SAP systems in unique ways to run their business, serve the customers, and build and maintain competitive advantages. As such, the Linke AWS Connector for SAP has been used to suit many different needs. In particular, three primary use cases have resonated most with customers. While these use cases are the most popular, there are countless other ways the Linke AWS Connector for SAP can improve SAP storage.
GOS/DMS

Using the S3 solution as a Content Repository defined in OAC0 that can be assigned to all document types available in OACT, this is not a CMS (Content Management Server). All interaction with attachments or documents is managed by the SAP application. For that reason, all activities related to records are configured as usual in SAP DMS available in all NetWeaver. That means, for example, SAP Data Retention Tool DART can benefit from the tool. The Data Retention Tool (DART) helps SAP users to meet the legal requirements concerning data retention and data transfer for tax auditing.
Commonly, SAP processes include and generate documents and attachments (PDFs, photos, etc.) to record or create outputs. Historically, these documents and attachments would be stored within the SAP database native to the server running the process, regardless of how critical they may be.
Customers running these processes commonly support their SAP workloads with costly storage implementations, especially on HANA, including high-performance disks and high availability setups. By storing documents and attachments that are not necessarily critical within these implementations, businesses inefficiently consume resources and drive-up costs. Furthermore, this can lead to a bottleneck in operations.
With the Linke AWS Connector for SAP, customers can offload document and attachment storage to Amazon S3. This allows the core processes to run inside their dedicated servers continually but removes document storage, increasing cost efficiency and operations speed. After the documents are moved to S3, customers can easily use AWS Textract. This relatively new AWS service was created as a purpose-built solution to the problem of OCR (optical character recognition) in images of documents and PDFs.
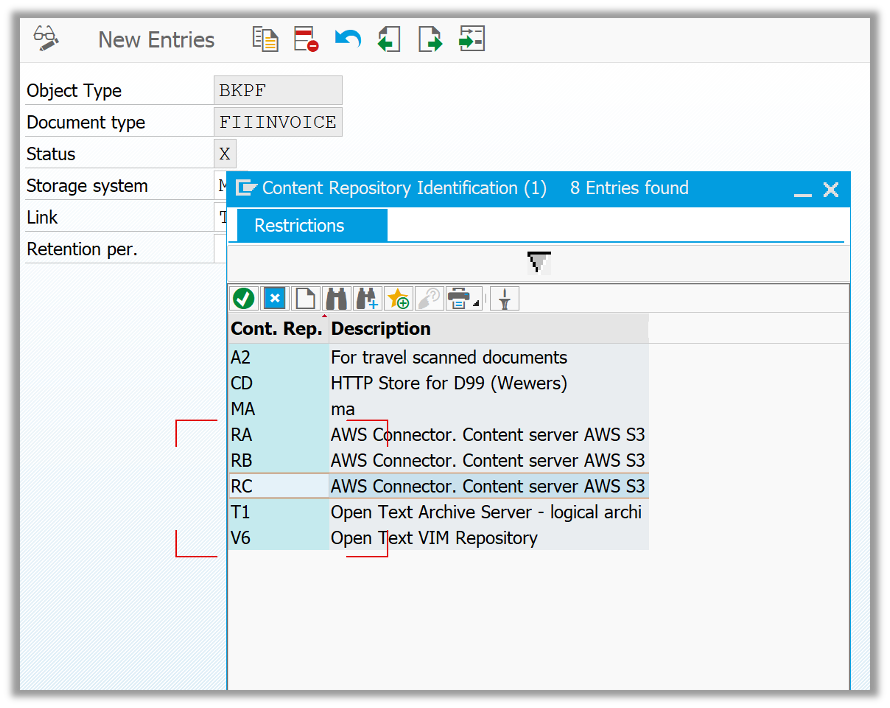
To use the AWS Connector for storing Business Documents, a Bucket or set of Buckets will be the destination for each Business Documents that need to be configured from the SAP end. Each Bucket has its content repository, R(x) (RA, RB, RC…).
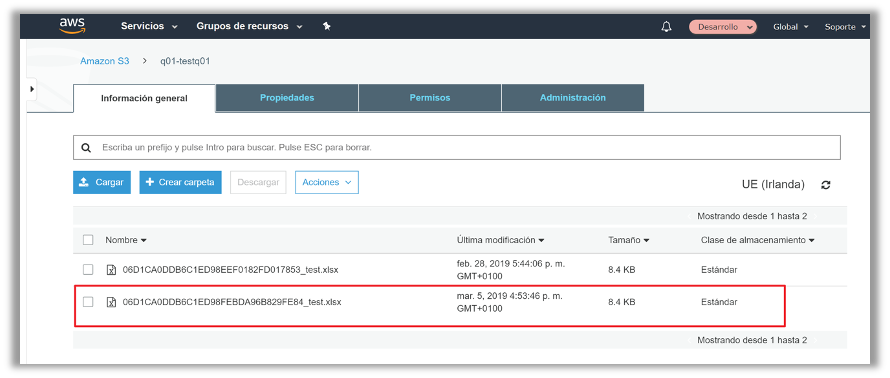
It’s possible to migrate already generated SAP attachments from SOFFCONT1 to S3 to a bucket; following SAP note 389366 – Relocation of documents, the /LNKAWS/RSIRPIRL_MIGRATION program is offered to perform this task. This report is based on the standard RSIRPIRL, but adding the possibility of keeping or deleting the source repository attachments.
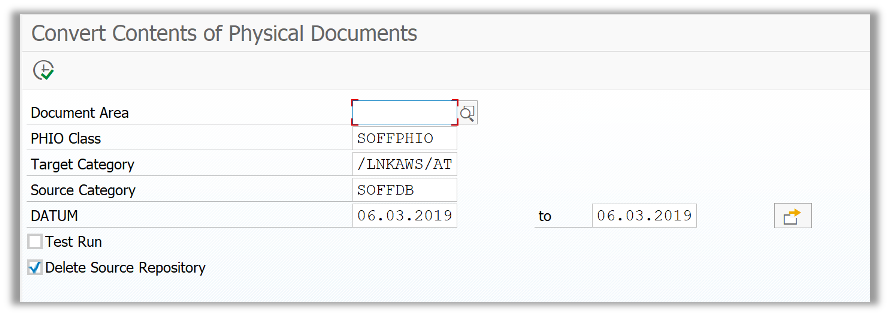
Also, the migration of Content Repositories for GOS documents, as referred by note 1043676 – Migration of ArchiveLink Documents, is a report ZMIGRATE_ARCHIVELINK_FILES provided for this task, where the old and new repositories can be specified.
Archiving SAP data on AWS

Whether as part of a standard backup process, complying with internal or regulatory requirements, or meeting storage service level agreements, many customers store old business data – such as transactional data or process outputs – on their SAP servers for an extended period (often 5 years). Although accessing this data is generally not critical to the day-to-day operations, many businesses must store it on SAP-certified disk storage, challenging to scale and expensive to maintain. Another option is archiving data using tape or optical storage, which requires the use of an off-site facility and can take a long time to recover and restore. Neither of these solutions is ideal.
Instead, businesses can use the AWS Connector for SAP to store this data on the cloud. Doing so enables efficient backups that simplify on-premises infrastructure, reduce management requirements, and eliminate the need to leverage an off-site facility. Customers can drive cost-efficiency further by leveraging Amazon Glacier, a long-term, secure, durable object storage for archiving.
Once SAP data is stored in Amazon S3, customers can set up a lifecycle rule that transitions objects to Amazon Glacier after a certain period of time (determined by the customer), allowing them to store data for as little as $0.004 per gigabyte per month.
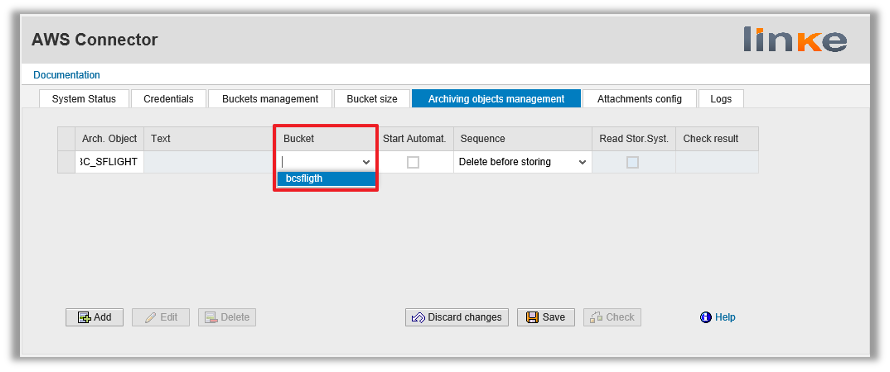
Consider SAP Data Archiving before SAP S/4 HANA migration. Customers running on SAP ECC6 supported until 2027 should start planning their move to the SAP S/4HANA platform. The ultimate key component and critical success factor for the SAP S/4HANA implementation is data. Data preparation is key to ensuring a successful data migration and SAP S/4HANA implementation.
Data preparation activities entail:
- Scaling down IT landscape to ensure leaner systems.
- Removing unnecessary data.
- Removing identified data to a secure storage archive.
- Ensuring accessibility to archived data as required for audit and business requirements.
Hence, SAP Data Archiving is a crucial and effective strategy in managing ongoing data growth, increasing security, improving compliance, and controlling costs.
What does an effective SAP data management (Data Archiving) strategy look like?
- Assess data
The first step in any efficient data management strategy is to assess the current data. When moving over to SAP S/4HANA, we must identify what steps are needed to simplify the migration process.
- Ensure regulation compliance
With compliance regulations such as GDPR, POPI, or HIPAA, it’s imperative to ensure that any data in possession is compliant and follows the strict legal requirements for data retention and destruction.
- Data retention
An effective data retention strategy is a must to ensure optimizing the data volumes on an ongoing basis. Data will be archived and deleted based on retention policies set to ensure compliance and reduce business risk.
- Decommissioning
Legacy systems are not uncommon in many companies, and, unfortunately, these systems can’t easily be as they typically retain data required for legal and business reasons. The recommendation is to review the legacy system landscape and decommission systems in a structured way to retain the data while saving costs from retiring old systems.
- Data deletion
Once all the above steps have been completed, we can think of deleting any extra data that has no further use for the company without breaking compliance laws. There is also less risk of a security breach during migration if we have fewer data transferring at the same time.
Data lakes

We often see the concept that Data is the new Oil or Gold.
But Gold is Gold, and Data is Data. Although it is exponentially generated in the enterprise, the concept explains that we are not manipulating the data as much as we can.
In the past, for all kinds of reporting, there used to be strong SAP-based solutions. In the old days, this used to be ABAP query, LIS, and CO-PA, followed by the SAP Business Warehouse, which, of course, was a giant leap forward. Nowadays, a similar leap forward is happening in the integration of SAP data and data lakes.
Most SAP enterprise customers are looking for ways to manage multiple data types from a wide variety of sources. Faced with massive volumes and heterogeneous data types, organizations are finding that, to deliver insights in a timely manner, they need a data storage and analytics solution in the cloud that offers more agility and flexibility than traditional data management systems. An enterprise-wide data lake is a new and increasingly popular way to store and analyze data that addresses many data challenges. A data lake enables storing structured and unstructured data in one centralized repository in the cloud. Since data can be stored as-is, there is no need to convert it to a predefined schema and no longer needed to know what questions we want to ask our data beforehand.
Worldwide, SAP customers have invested in enterprise data warehouse/data mart using SAP HANA, Amazon Redshift, or Snowflake. HANA offers tremendous benefits with the in-memory capability of HANA and speed of agility; however, data volumes continue to grow exponentially in recent times due to the addition of data from steaming applications, artificial intelligence, and machine learning.
Unfortunately, data tiering is not always implemented in customer landscapes because of technical or scope reasons, so keeping everything in HANA is an expensive affair for S4HANA customers.
In an SAP environment, data is sometimes trapped in SAP, and many processes need to be created to get it out. The data structure may be fractured, resulting in differing views on reporting requirements across functional domains. Data warehouses have gone a long way toward solving the problem of fragmented data. Yet, data warehouses are primarily geared toward managing pre-defined, structured, relational data for existing analytics or common use cases—data that is processed and ready to be queried. Today, leading-edge data warehouses, which are leveraging public cloud services like Amazon Redshift, are being enhanced with the addition of a data lake leveraging other AWS services. A typical organization will require a data warehouse and a data lake closely connected to it because each serves different needs and use cases.
Remember, in a world of Microservices, and we shouldn’t relate Data Warehouse to a specific product, meaning that a Data Warehouse on AWS will probably involve the following services;
- Amazon Redshift
- Amazon ECS and Amazon Kinesis Data Streams for ingestion
- Amazon S3 for data lake
- AWS Data Pipeline to orchestrate Data Flows
- Amazon EMR for Big Data Processing
- Amazon Athena for data querying and analytics
- Amazon Kinesis for data movement (pipes)
- Amazon Quicksight for dashboards and visualizations
- … and others
Many customers invest a lot in cloud data lakes hosted on AWS, Azure, or Google Cloud using proprietary solutions, Snowflake or Hadoop data lakes even though 70 % of their data is coming from SAP (S/4HANA, BW/HANA), SAP also offers a solution hosted on SAP Business Technology platform, the HANA Data Lake(HDL).
For customers interested in creating a data lake on AWS from S/4HANA or BW/4HANA data, the AWS Connector allows writing to Amazon S3, providing sample programs for table extraction and ERP extractors. We recommend data extraction to Amazon S3 from SAP BW in complex extraction scenarios, exporting data from ODS/CDS or the InfoCubes themselves. At the same time, It is also possible to extract data using SAP SLT, integrating the AWS Connector with SAP SLT to enable data extraction to Amazon S3.
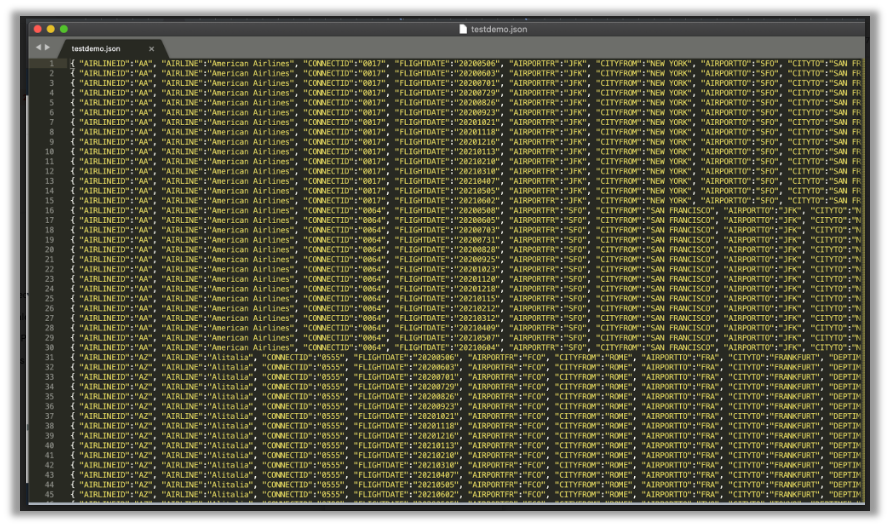
To extract from RSA3 to an S3 bucket, the program /LNKAWS/RSA3_TO_S3 can be used. The program includes a DataSource extractor to obtain the required data.
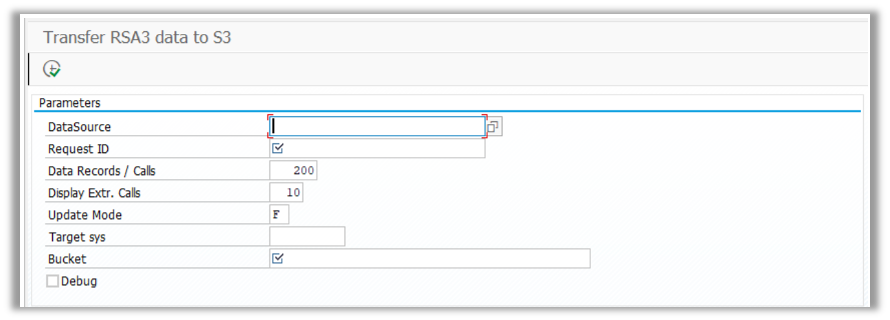
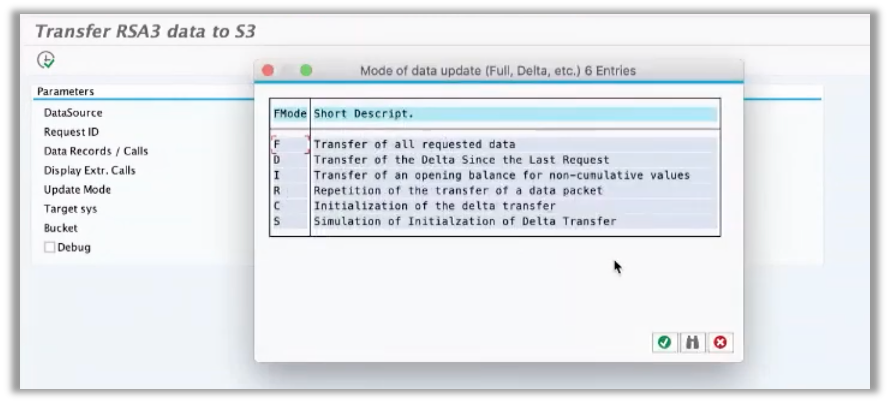
Data is stored in JSON format or Athena structured format. The ability to use RSA3 allows us to select Full extraction (Delta is still not supported by default from the add-on) and use it in Dialog or Batch processing.
Another possibility is to extract directly from the table to S3.
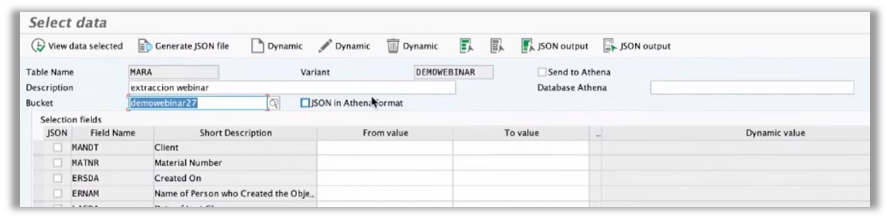
If we select “Send to Athena,” the AWS connector will create a DB structure from SAP and Athena’s possibility to read the S3 data in a structured way.
If the data is not structured and we select JSON as the format, we will have the raw data ready to process.