On high-level SAP has re-engineered the platform in S/4 HANA to maximize the in-memory capabilities of HANA database. Although there has been some drastic change, still S/4 HANA does not need Greenfield Implementation. Do not be scared of the term Greenfield. Greenfield means barren, clean lands where you can do anything you want i.e fresh SAP S/4 Implementation.
S/4 HANA is being promoted by SAP as Simple SAP. They say S/4 HANA Business Suite would revolutionize the way we did business. It would make everything Simple. S/4 HANA brings in transactional simplicity, advanced analytics, innovation, and enhancement of the functionality as compared to traditional SAP ERP.
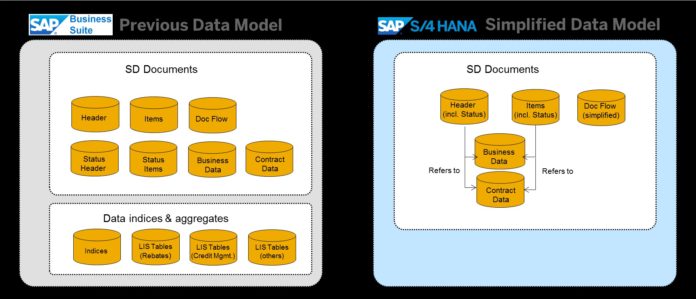
S/4 HANA provides a new data model by removing old tables, aggregate tables, and index tables to create fewer columnar-based tables and deliver a real single version of the truth. Tables MATDOC and ACDOCA are two examples of this simplicity. SAP S/4HANA is designed with an SAP Fiori integrated user experience that provides users with instant insight and works on any mobile device. It offers real-time operational analytics on the SAP ERP platform thus reducing the dependency on SAP Business Warehouse (SAP BW) reporting.
Getting rid of aggregate and index tables allow for the reduction of data footprint because calculations for transactions are performed on the database layer instead of the traditional application layer on an ad hoc basis.
So, as per our understanding, S/4 HANA brings forth changes in the Data Model, which in turn provides the Simplification.
YOU MIGHT ASK, GIVE ME ONE EXAMPLE OF SIMPLIFICATION WHICH S/4 HANA BRINGS FOR ABAPERS?
The best one which we can say is: The Status Tables VBUK and VBUP are no more needed. The status is included in the respective document tables. The status for Sales Order Header and Items are in table VBAK and VBAP itself.
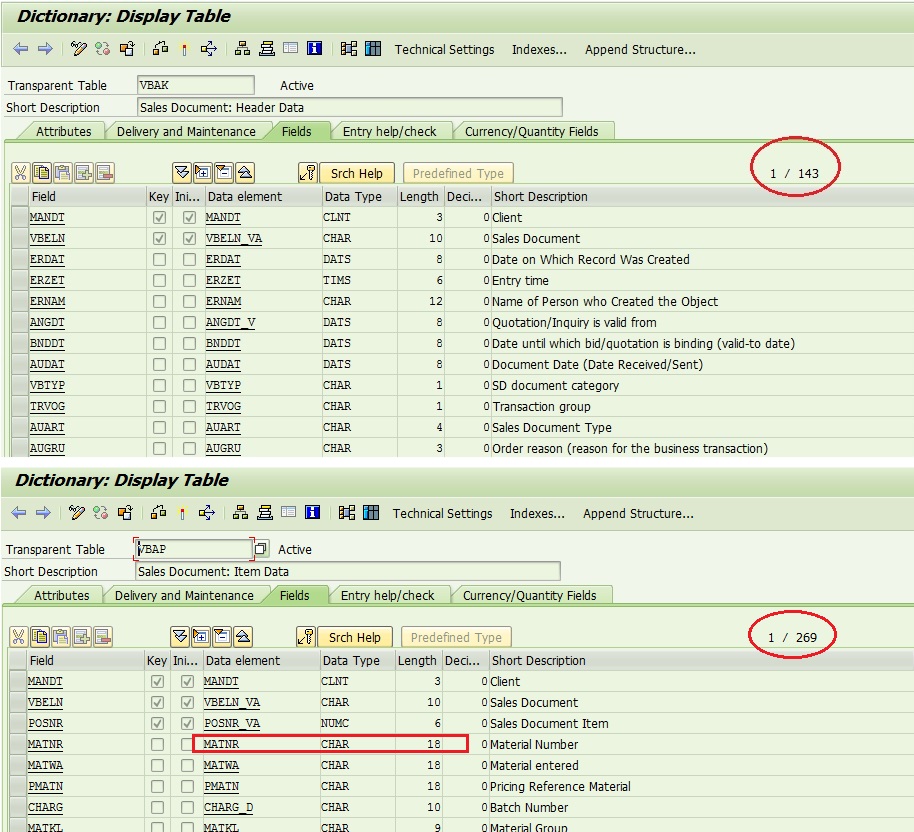
Sales Order Table in ECC
Check the below image. Is it not Simple now? Instead of joining two tables to figure out the status, ABAPers need to read just one table. Select data from VBAK to get Sales Order header information along with Status.
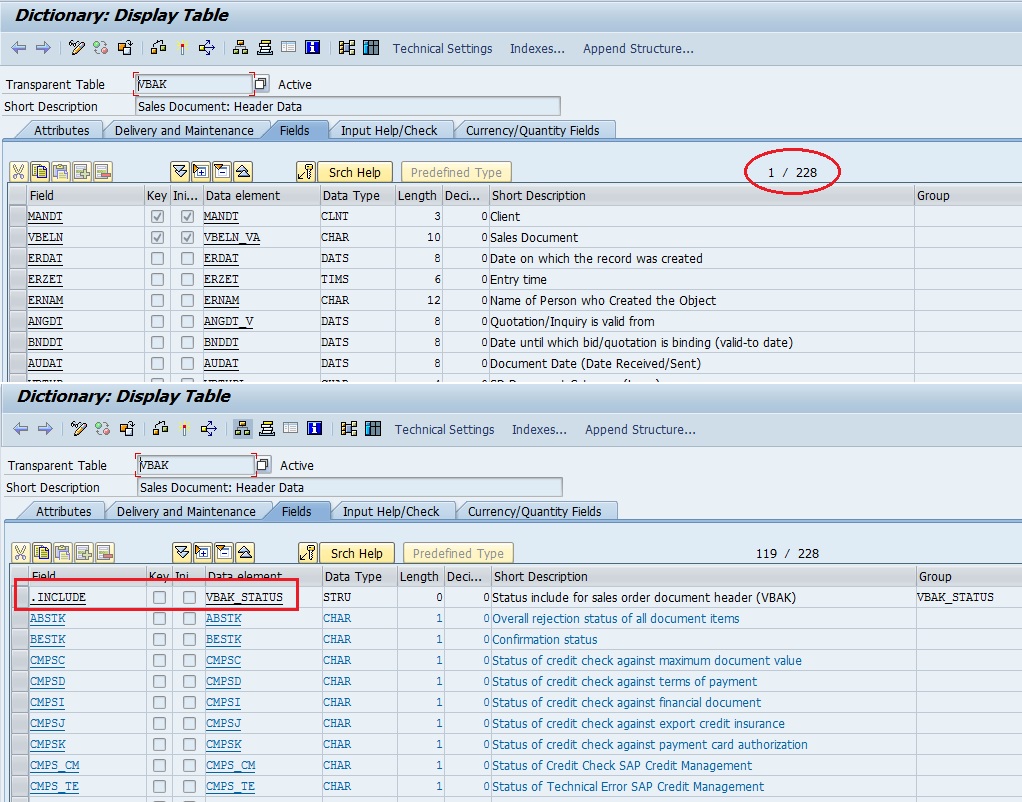
Sales Order table with Status in S/4 HANA
Check the number of fields has grown from 143 to 228 in VBAK table. Similarly, the number of fields have been increased to 337 from 269 in VBAP. This has been done to incorporate data from other fields, which is quite understandable. Also, as mentioned in Part I, the MATNR data element length has been increased to 40 characters from 18 characters.
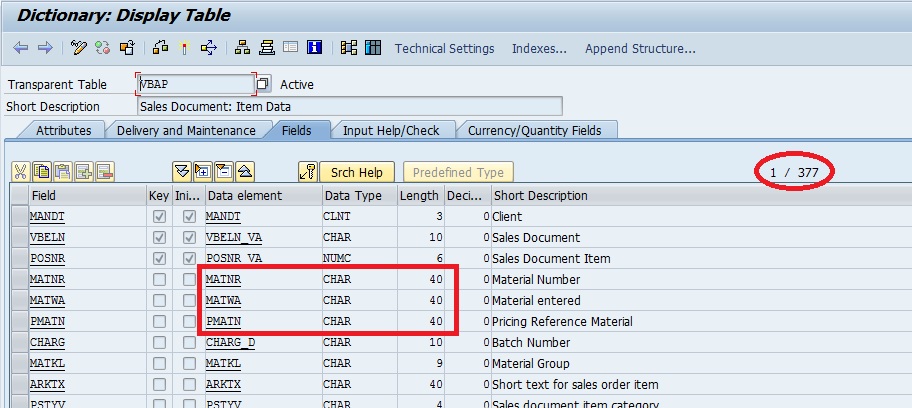
Similarly, explicit Status tables of LIKP/LIPS (Delivery) and VBRK/VBRP (Billing) has been removed from VBUK and VBUP. Now the delivery and billing tables would have the status incorporated.
That is Simple. Isn’t it?
OK, THE NUMBER OF TABLES CONTAINING MASTER DATA HAS BEEN DRASTICALLY MINIMIZED IN S/4 HANA. BUT HOW DOES IT HELP?
Simple – It speeds up overall performance and also reduces the memory footprint on the database exponentially.
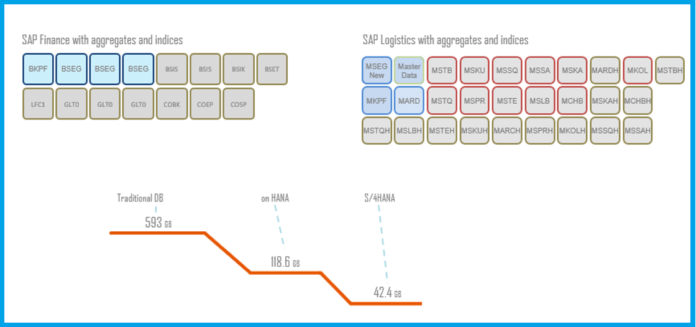
The in-memory database (read HANA) has the superpower to calculate on the fly. So the previous index tables like BSAS, BSAD, BSIS, BSIK, BSAK, BSIM, FAGLBSAS, FAGLBSIS which helped us with performance are no longer needed in HANA. Similarly, aggregate tables like GLT0, GLT3, KNC1, LFC1, KNC3, LFC3, COSP, COSS, and FAGLFLEXT are also made obsolete.
The scary thoughts which every ABAPer has when they hear, HANA has made the index tables and aggregate table obsolete and redundant.
WHAT WOULD HAPPEN TO THE OLD ABAP CODES WHICH QUERIED THESE TABLES TO SHOW SOME REPORT?
Does that mean all those Custom Programs are junks now?
Thankfully, SAP did not waste your effort. All those programs would still continue to function as designed?
But how?
SAP has created Compatible Views for those tables with the same name. So, your report would recalculate the same values as the tables would have done (since the view name is same as the table) and your report would work in the new S/4 HANA world too.
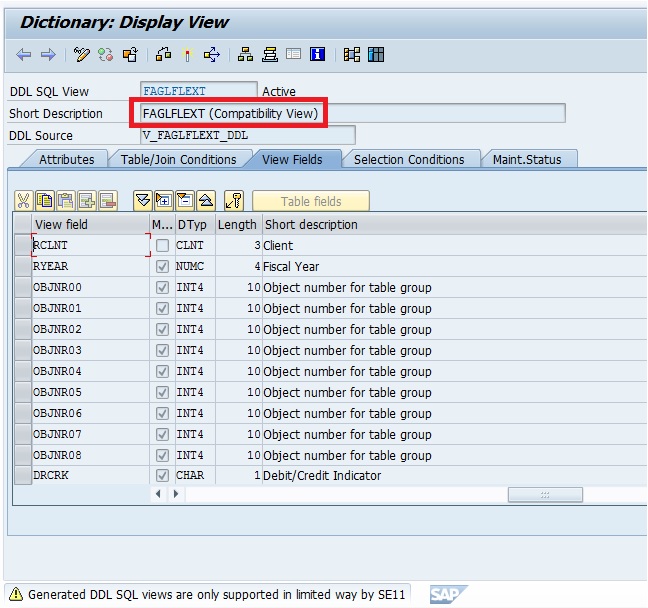
Having said that the old Reports would continue working, we might no longer need some custom reports as that functionality might be available in S/4 HANA as standard. Or we might also need to re-write the old Report even though it is working to make use of the speed of HANA and/or use the new tables available which would improve the process and the performance.
On one hand, SAP claims to eliminate redundant Document Index Tables viz VAKPA, VAPMA, VLKPA, VLPMA, VRKPA, VRPMA etc.
BUT WHY DO THEY CONTINUE TO POPULATE THESE TABLES FOR NEW TRANSACTIONS?
Isn’t it still creating those extra footprints? We have no answer to it as of now. Maybe some expert would put the explanation in the comment section.
Similarly, MATDOC is supposed to be the single source of Truth, then why MKPF and MSEG table continue to be populated in S/4 HANA? They both are not CDS Views but still transparent tables.
We have no answer to this as well. If you know the answer, can you please put your thoughts in the comment section?
Now let us contradict the above theory that SAP has created Views with the same name as the tables which they have marked as Obsolete in S/4 HANA.
Most of the tables have the corresponding View so the reports using those tables still continue to work as the view namesake does the trick and redirect at database layer and pull the correct data from the database.
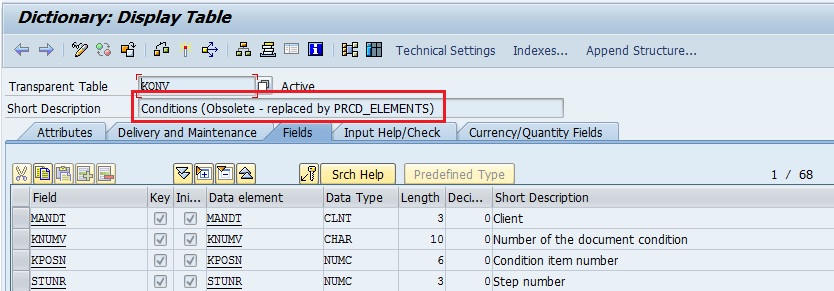
BUT WHY THE STEP CHILD ATTITUDE TO CONDITION TABLE KONV?
Table KONV has been made obsolete and they have not provided any corresponding VIEW for the transparent table with the same name.
New table PRCD_ELEMENTS is replacing the KONV table.
KONV is empty in S/4 HANA. Unlike MKPF, BKPF which are still populated for new transactions in S/4 HANA along with MATDOC and ACDOCA tables, KONV/KONP are not populated at all, neither for the old data nor for new transaction data. PRCD_ELEMENTS is the single source of truth for condition records.
SO, YOU MIGHT THINK, WHAT IS THE BIG DEAL?
KONV is frequently used in custom developments related to MM, SD, FI modules. One of our team members who is working in S/4 HANA migration project informed us that he needed to replace all the select queries on KONV/KONP tables to direct the query to the new table PRCD_ELEMENTS. It was for a small client with a relatively simple business process, but still, they had to replace around 600 select queries in some 150 odd custom objects.
Imagine the pain if it was a large sized SAP client.
So if you are moving to S/4 HANA, one task is confirmed for you. You are bound to make changes to all custom codes where KONV/KONP is used for the Select query.
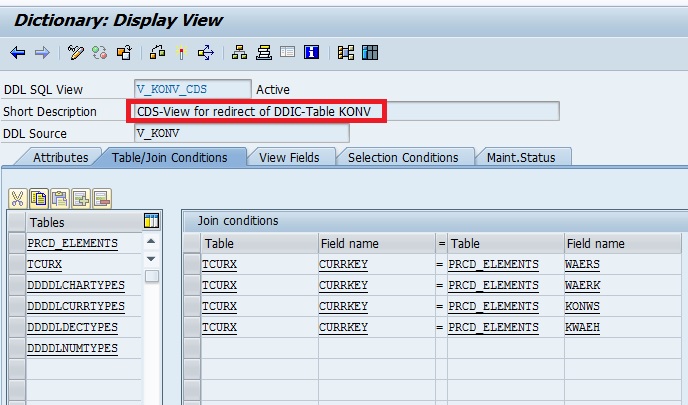
Later we found that SAP has created a CDS View for KONV. It is christened as V_KONV_CDS. But why have they NOT named the view same as the table name i.e KONV? That way, it would have saved the ABAPer from correcting all the Select Queries.
Do you know why KONV does not have Compatible View? If yes, please provide your explanation in the comment section.
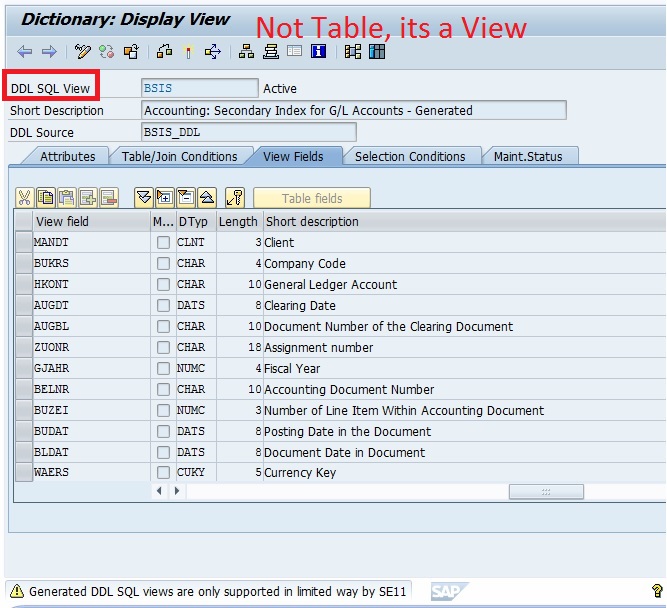
Look how they have created CDS View with the same name as the previous transparent table for BSIS.
Before we close today, let us talk about LSMW.
LIKE BDC, DID LSMW SURVIVE THE S/4 HANA MIGRATION?
LSMW is still active in S/4 HANA (on-premise). But it is not recommended to use LSMW in S/4 HANA as it has not been upgraded to use the new data structures and many functionalities are not available like recordings cannot be done for Fiori Transactions. Standard Batch Input programs might also not work as many transactions have changed the functionality or may have been removed completely.
In short, LSMW is not considered as the migration tool in S/4 HANA.
So, what are the alternatives?
SAP Rapid Data Migration with SAP Data Service and SAP S/4 HANA Migration Cockpit.
If R/2 to R/3 gave birth to LSMW then ECC to S/4 HANA gave birth to SAP Rapid Data Migration and S/4 HANA Migration Cockpit. Details of these tools would follow up in some other articles.
On a separate note, in case we are still in ECC and planning to move to S/4 HANA in near future, we can follow the below Prepare -> Plan -> Implement strategy for migration to S/4 HANA.