1. Preface
This Blog is meant as an extension or completion of my former Blog on Tricentis:
SAP Application Testing Solutions by Tricentis – Overview
As SAP Enterprise Data Integrity Testing (EDIT) has been added to the SAP Solex-Product list of Tricentis in the end of 2021, this blog completes the product overview.
2. Product overview SAP Tricentis
The Testing Solutions from Tricentis on SAP’s Solex-Partner Pricelist now include all test automation tools from Change Impact Analysis to functional and performance test automation and data integrity testing:

A detailed description of Change Impact Analysis, Enterprise Continuous Testing (ECT) and Enterprise Performance Testing (EPT) can be found in the blog mentioned above. We now want to focus on Enterprise Data Integrity Testing (EDIT).
3. Enterprise data integrity testing – what it is and what it is not
In SAP’s broad product portfolio you can already find a lot of dedicated solutions dealing with data quality so you might wonder why yet another one? We already have tools like
- MDG – Master Data Governance
- ILM – Information Lifecyle Management
- Information Steward
- Data Services
- ETL-Tools
- Migration Cockpit
- ADM – Advanced Data Migration (Syniti)
just to name the most common ones – all dealing with data quality assurance.

SAP Enterprise Data Integrity Testing by Tricentis (EDIT) is not a tool to maintain overall data quality or to improve data quality in a certain aspect. It will not change any data and is by no means a data migration tool.
EDIT is designed as an add-on to Enterprise Continuous Testing (ECT) for the purpose of continuous testing on data integrity for (big) data warehouses. With EDIT you can read and analyze the data from several data sources and data streams flowing through your enterprise and possibly being transformed on their journey to your data warehouse or data lake for a central reporting.
4. Key Business Drivers and challanges
In your business there are all kinds of valuable information sources and many of them flow to a data warehouse or data lake for a central business reporting. Data quality, integrity and actuality is key for a reliable reporting and decision making. There are many forces and influences working on the data continuously possibly diminishing the data quality and integrity:

The movement and flow of data from different sources to a central Data Warehouse or Data Lake/Data Hub can be quite complex and many transformations may be applied on the data during their journey. According to the complexity of data flows and transformations the process is error prone and hard to control or verify. Business rules and data models can change over time and also the application landscape and data sources can change.
Whereas the typical data quality solutions like MDG oder Syniti ADM are more ‘Point-Solutions’, meaning they are applied at certain data in certain data sources at a specific point in time, EDIT is meant as a continuous surveillance tool for data integrity across all business applications and data sources. This means you can control your data flow at any point or stage throughout the entire data stream in the enterprise, be it at certain data sources or on the way the data takes from the sources to the central DW system or data lake. You just take care of the overall rules and conditions that should be checked on the data and EDIT does the automation testing on the fly during the data flow or when new data enters the central DW.

You finally want to make sure that any data that enters your DW and is used for business-critical reporting and decision making is accurate, integer and according to all your business rules. If not, errors resulting from bad or corrupted data can be very expensive if they lead to wrong decisions in your critical business areas.

It not only has a bad impact on the resulting reports but lead to poor decision making, operational issues across business processes and can even result in costly compliance issues. Lastly it also has a very bad impact on ML/AI-driven initiatives as it leads to suboptimal results for the detecting algorithms und thus lead go generally untrustworthy reports.
5. Solution overview

EDIT is a data testing solution that is
- End-to-end (testing data processes from beginning to end)
- automated (runs automated in the background)
- continuous (assures data quality in a continuous process)
so, you can
- catch more data issues upfront (before the data enters the DW/data lake e.g.)
- Test at scale and speed of the data flow
- Get higher data quality and higher reporting quality for optimal business decisions
The data sources EDIT can inspect are not restricted to SAP or any operative ERP-System but can include all kind of data sources on any database or even flat files. It can also read data streams from sources where data is constantly generated by different sorts of sensors, like on powerplants for electricity networks or gas pipelines or even water or other medium. In this way EDIT can be used e.g. to compare data streams and to detect leakage or other malfunction before it gets worse or even noticeable by the customer.
EDIT’s key functionalities include:
- Comprehensive data testing across SAP and 3rd-party technologies
- Actionable reporting
- Customizable risk thresholds
- Low code/no code automation
- Integration with DataOps and DevOps tools
In this way EDIT can be used all over your IT business landscape, on SAP and non-SAP systems, all kinds of data sources and help assure consistent and accurate data on all stages of your business processes. Actionable reporting is key to handle huge amounts of data so you can easily identify the error source and access and correct the defective data entries or any data transforming interface causing the error.
The Customizable risk thresholds are an interesting feature when it comes to any kind of fuzzy logic or fuzzy data e.g. unstructured data like photos or text from social media or also discrete data where the exact value doesn’t matter so much. Then you can set boundaries, upper and lower values e.g. to specify the expected value range.
The Low code/no code automation paradigm is inherited from the ECT/Tosca and in the case of data access to any DB or data source means a reduction of necessary SQL-statements to a minimum by providing several data access standard methods for all kind of data sources.
Also the Integration with DataOps and DevOps tools is inherited from the capability of ECT/Tosca, so it means it can easily be integrated into application livecycle management tools like SAP Solution Manager or Cloud ALM or into DevOps and CI tools like Jenkins or Azure DevOps.
EDIT’s predefined test types for each step of your data’s journey
EDIT delivers several predefined test types for each step and stage of the data journey to the central DW to help speed up the data quality assurance process:

On the picture above you see the different stages of data travelling from data sources (left) to a central data store/DW, possible data modification or adaption processes to the final reporting area on the righthand side. For each stage of the journey EDIT provides predefined test types:
Pre-Screening
These test types live in the area of data sources and are meant for some essential structural data testing like Metadata checks, Format checks and content checks on the level of typically data files. These can be csv-files, JSON- or XML-files for example. With these test types the overall data formatting can be tested, the data types and even some content information can be tested. Examples are numerical tests, value ranges, valid calendar dates or currency values.
Vital Checks and Field Tests
are meant for any kind of database or data warehouse/data hub and typically compare data between two objects. This can be a source- or target layer in the sense of ETL processing or it can also be different versions of the environment in the sense of regression testing. This data is than compared to a higher level or aggregation stage to make sure no data is lost – completeness test. The vital checks also include metadata checks, uniqueness, non-nullness (not empty) and referential integrity (relationships between data).
With the field tests you can also check aggregation and row count, min. /max. values or average and value ranges from source to target destination.
These tests can normally be generated from the source data automatically and can be performed rather quickly as they mostly run on an aggregate level and compare just a few values. These tests are not meant as an exact row by row test but more as an overall plausibility test.
Reconciliation Tests
For more thorough and in-depth testing you can choose the reconciliation test or a row-by-row and column-by-column test. This will take much longer but can assure that each value is exactly transferred to the next stage. This comparison can be done cross-technology, thus including different databases or single files.
Report- and App-Testing
These tests are run on the Analytics/BI- and application area and thus on the reporting itself. The data access is – like with ECT – on the UI-level or on the API-level. It extracts the data from the UI- or API-level and compares it to the data in the DW/data mart etc. via reconciliation tests. Test in this area include UI automation, visual checks, content and security checks.
Illustrating Example from Sales Analytics Dashboard
The testing process and results can be better understood by a typical example from an analytics dashboard:

From left to right data is ingested into the DW and then into a sales data mart for reporting in the sales area. In the lower blue part the data testing is performed via EDIT and problems are reported. This is a typical real-world example: there is data just lost because some extraction process did not work as expected. So this data is missing in the DW. Or some extraction load process was performed twice and is not properly managed so there is duplicate data. On the reporting level user roles are not applied correctly and sensitive data is shown to the wrong user role.
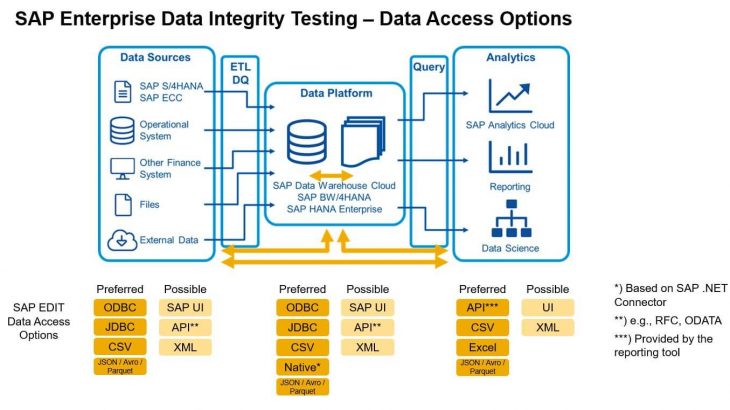
EDIT – data access options
Depending on the data sources EDIT provides several data access options that can be used to access the data:

For the data sources on the left-hand side the preferred access option is always via ODBC or JDBC. This is always the easiest and most convenient way. If this is not possible you can retrieve data via SAP UI (GUI) or API (for example RFC-connection or ODATA).
This is also true for the central DW or data platform – preferred access option is ODBC or JDBC.
For the reporting stage data can be accessed via Excel (analysis for Office for instance) or API-layer provided by the reporting tool, alternatively via UI or XML.
6. Integration into ECT/Tosca
EDIT comes as an extension to ECT/Tosca and uses the test automation capabilities of ECT to perform the automated data integrity testing. The license of EDIT includes technically the use of ECT for EDIT, so it is not necessary to license the ECT for the purpose of using EDIT. If the add-on for EDIT is activated you will see additional Tabs in the Tosca-Commander used for data integrity testing:

Here you can also see the predefined modules for the different test types EDIT provides. These modules can be adjusted or completed if there is need but will give you a solid starting point with less effort.
EDIT also comes with a lot of predefined testcase templates to make your journey to productive testing even simpler:

These testcase templates are grouped into Pre-Screening, Vital Checks, Field Test and Generic / Custom templates and can be used for fast testcase generation. The tests are mostly defined be a resp. SQL statement that can be used as a repository. They can be expanded and enhanced centrally and made available to other testers with no code/low code experience.
EDIT also comes with a testcase creation wizard for the different test types which makes testing even more convenient:

In the dynamic ribbon area on the top of the image you can see the available test type wizards that will guide you to the design process of the according test type.
Let’s have a look at a simple prescreening wizard as an example:

Here we look at the content of a geo-file for example and want to define some vital checks for data integrity and consistency. We can choose from the list of predefined tests on the right and select which tests should be applied to which column of the data in the file.