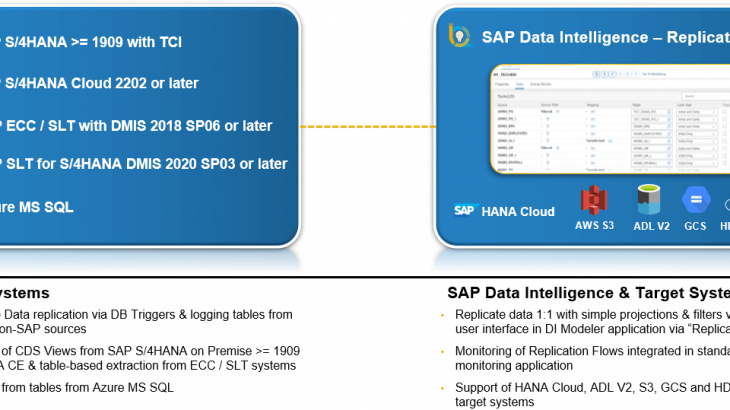
SAP Data Intelligence, cloud edition DI:2022/05 will soon be available.
Within this blog post, you will find updates on the latest enhancements in DI:2022/05. We want to share and describe the new functions and features of SAP Data Intelligence for the Q2 2022 release.
Overview
This section will give you a quick preview about the main developments in each topic area. All details will be described in the following sections for each individual topic area.
SAP Data Intelligence 2022/05
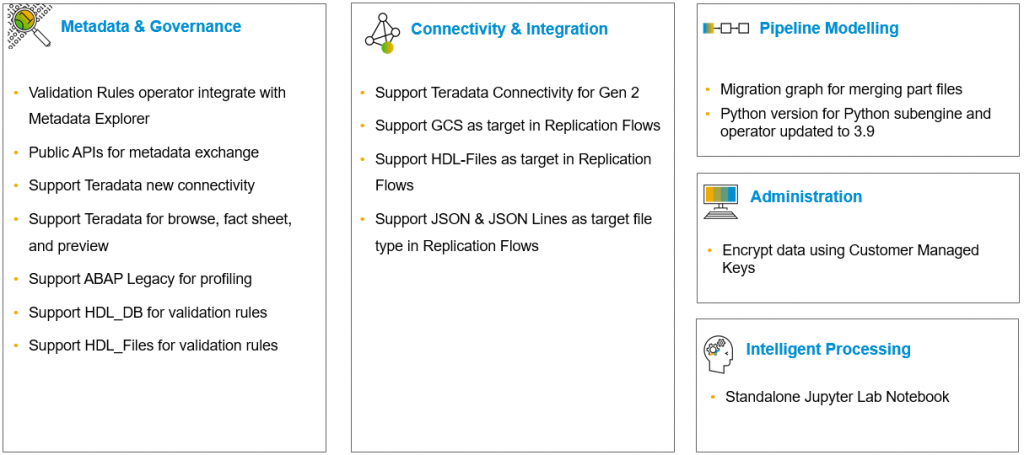
Metadata & Governance
In this topic area you will find all features dealing with discovering metadata, working with it and also data preparation functionalities. Sometimes you will find similar information about newly supported systems. The reason is that people only having a look into one area, do not miss information as well as there could also be some more information related to the topic area.
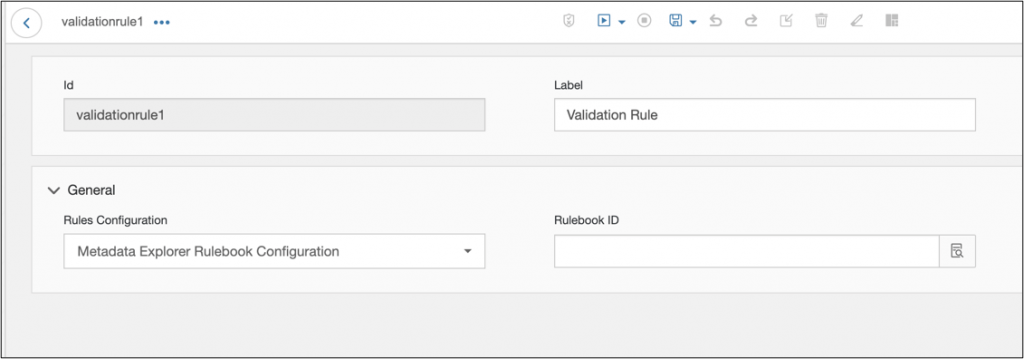
Validation Rules operator integrate with Metadata Explorer
USE CASE DESCRIPTION:
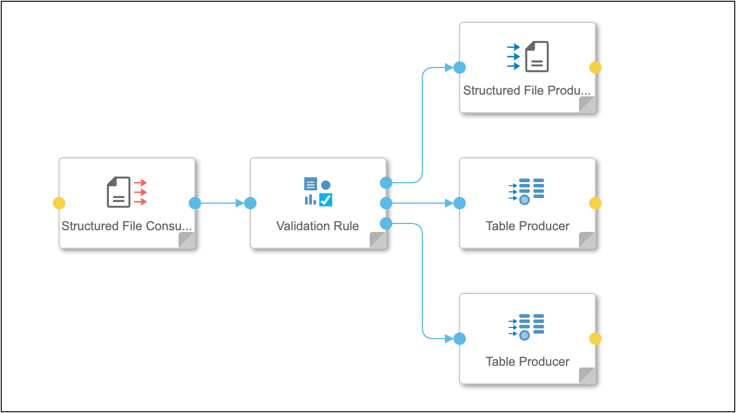
- Ability for a Modeler to build a pipeline graph that reuses trusted Metadata Explorer’s validation and quality rules
- Execution of rule validation from pipeline and reuse rules within rule operator
BUSINESS VALUE – BENEFITS:
- Validation and quality rules created and defined by a subject matter expert in Metadata Explorer’s rulebooks can be reused by a Modeler in pipeline
- Ability to run rulebooks in a pipeline and send pass and failed records to respective targets
- Allow subject matter expert to ‘fix’ failed records to improve quality of the data
- Allow subject matter expert to ‘fix’ failed records to improve quality of the data
- Collaboration between data stewards / subject matter experts and modeler / developers
- Quickly be able to use rules in a pipeline without having to create the rules from scratch
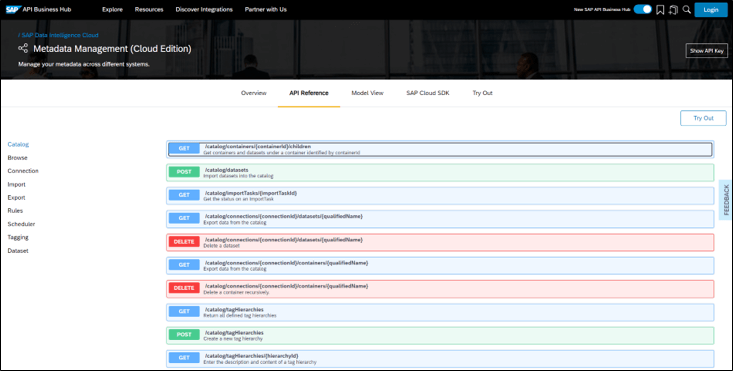
Public APIs for metadata exchange
USE CASE DESCRIPTION:
- Ability to export out Metadata Explorer’s including:
- Lineage information of datasets, including relations with other datasets
- Used transformations and computations
- Schema information
- Profiling data
- User descriptions
- Lineage information of datasets, including relations with other datasets
BUSINESS VALUE – BENEFITS:
- Ability to consume and use exported information in reporting tools for:
- Analysis
- Creating plot graphs to visualize lineage information based on organizational needs and requirements
- Reuse descriptions and annotations
- Analysis
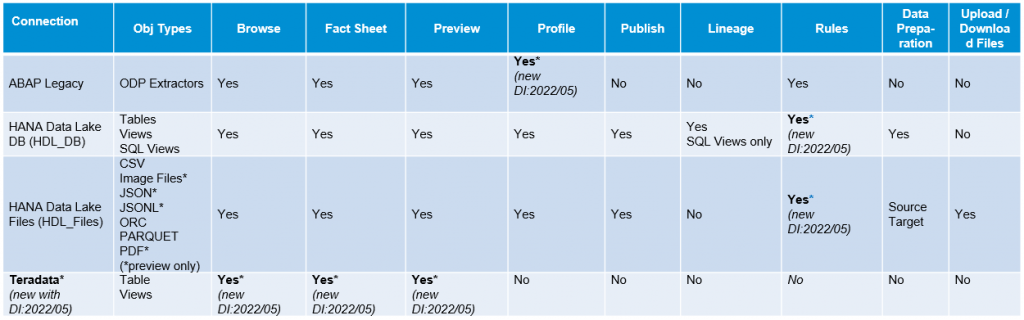
Add Rules – Add Publishing – Add Connectivity within Metadata Explorer
BUSINESS VALUE – BENEFITS:
- Expanded functionality support for sources * * New with DI:2022/05
Connectivity & Integration
This topic area focuses mainly on all kinds of connection and integration capabilities which are used across the product – for example: in the Metadata Explorer or on operator level in the Pipeline Modeler.
Connectivity to Teradata
Creating a new connection of type “TERADATA” in the connection management that can be used in Metadata Explorer as well as data source for extraction use cases in pipelines.
- Supported version: 17.x
- Support via SAP Cloud Connector
Supported qualities:
- Metadata Explorer
- browsing
- show metadata
- data preview (tables)
- browsing
- Data Extraction via Generation 2 Pipelines
- Table Consumer
- SQL Consumer
- SQL Executor
- Table Consumer
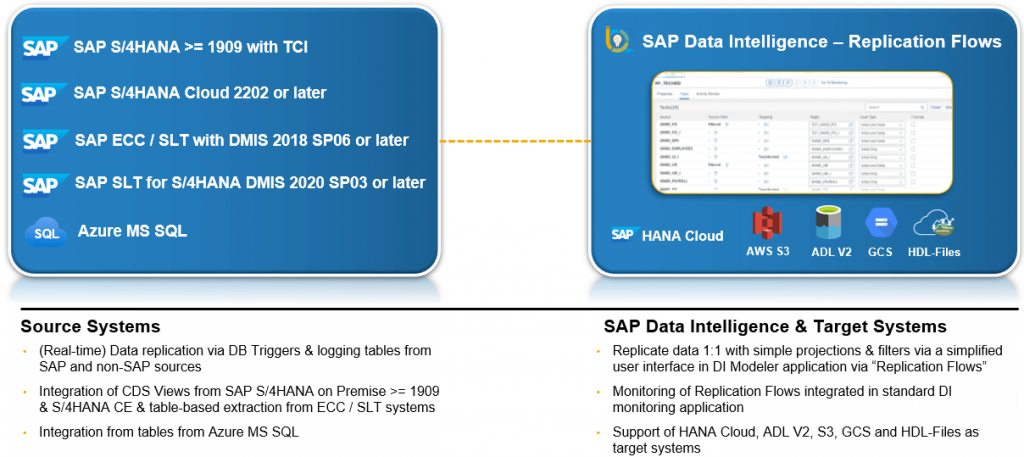
Support of Google Cloud Storage (GCS) as target in Replication Flows
Creating a Replication Flow now allows to write data in form of files to GCS as a target using the following properties
- Container (Target file root path)
- Group Delta By (none, date, hour)
- File Type (csv, parquet, json, json lines)
- File compression (only for parquet)
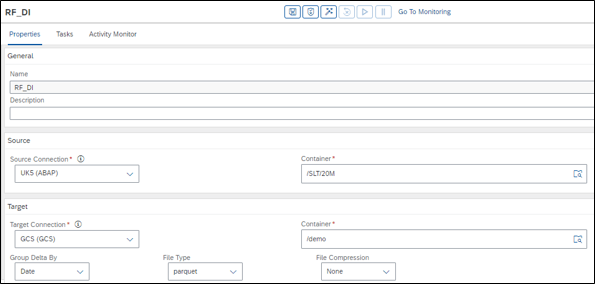
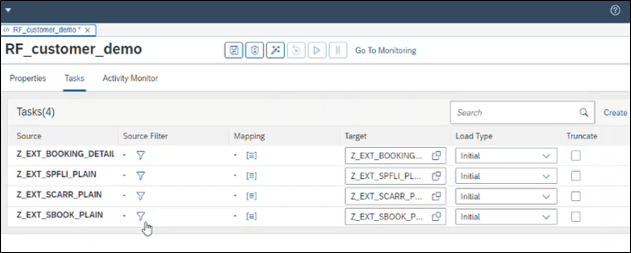
For each replication flow, you can add one or several tasks to load the data in to GCS and:
- Perform filtering (optional)
- Change column mapping (optional)
- Set or change target name
- Select load type on data set level
Support of HANA Data Lake (HDL) Files as target in Replication Flows
Creating a Replication Flow now allows to write data in form of files to HDL-Files as a target using the following properties:
- Container (Target file root path)
- Group Delta By (none, date, hour)
- File Type (csv, parquet, json, json lines)
- File compression (only for parquet)
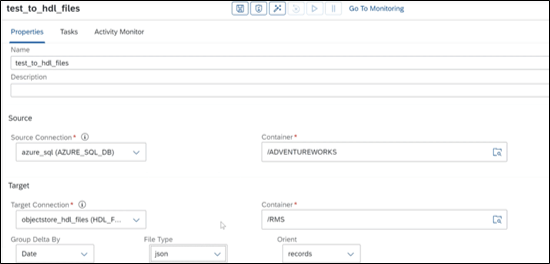
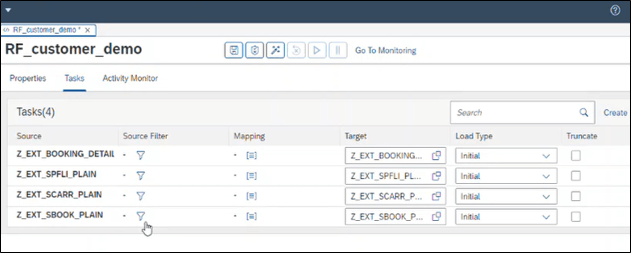
For each replication flow, you can add one or several tasks to load the data in to HDL-Files and:
- Perform filtering (optional)
- Change column mapping (optional)
- Set or change target name
- Select load type on data set level
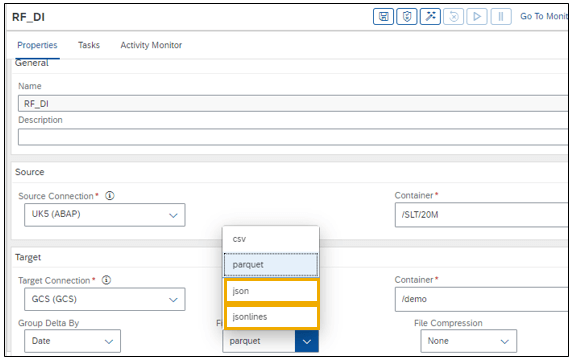
Support of JSON & JSON Lines as target file type in Replication Flows
When creating a Replication Flow selecting a cloud object store as target (AWS S3, ADL V2, HDL Files or GCS), you can now also select:
- JSON and
- JSON Lines
as file formats in addition to previously available csv and parquet file formats.
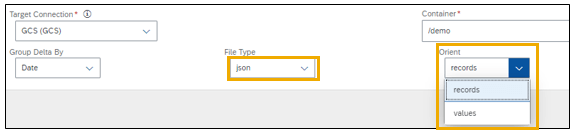
When choosing JSON as file format, you can select between two different json formats:
- Records
- Values
Mass Data Replication via Replication Flows
Pipeline Modelling
This topic area covers new operators or enhancements of existing operators. Improvements or new functionalities of the Pipeline Modeler and the development of pipelines.
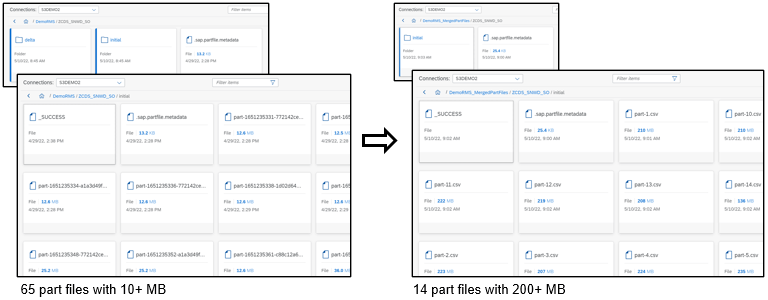
Migration graph for merging part files
USE CASE DESCRIPTION:
- merge small part files generated by replication flows, including both initial and delta loads
- Supported merge scenarios/file formats
- CSV to CSV
- Parquet to Parquet
- CSV to CSV
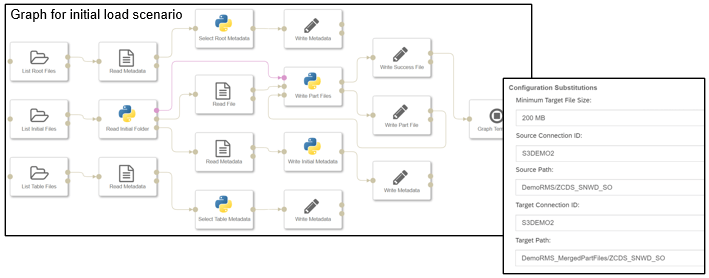
BUSINESS VALUE – BENEFITS:
- Achieve replication with configurable file size
Administration
This topic area includes all services that are provided by the system – like administration, user management or system management.
Encrypt data using Customer Managed Keys
USE CASE DESCRIPTION:
- Integration of SAP Data Custodian Key Management Service and SAP Data Intelligence
- Supported for new DI Cloud instances created in AWS where a SAP Data Custodian Key Management service instance is available
- Feature can be enabled during the creation of a new DI instance
- Option to provide an existing Data Custodian Key reference to be used in the new DI instance
- Supported for new DI Cloud instances created in AWS where a SAP Data Custodian Key Management service instance is available
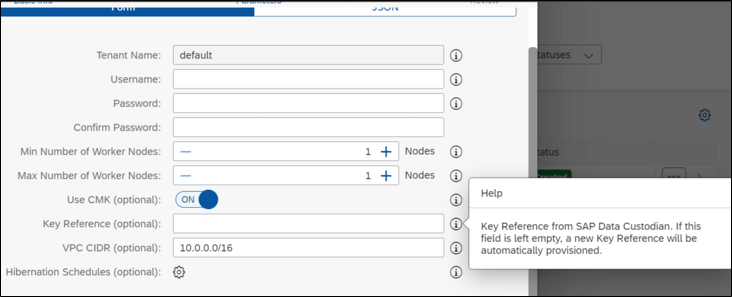
BUSINESS VALUE – BENEFITS:
- Increased flexibility to use own encryption keys
Intelligent Processing
This topic area includes all improvements, updates and way forward for Machine Learning in SAP Data Intelligence.
Standalone Jupyter Lab Notebook
USE CASE DESCRIPTION:
- Use Jupyter Lab for:
- EDA
- Data Preprocessing
- Data Manipulation
- EDA
without a hard dependency on ML Scenario Manager.
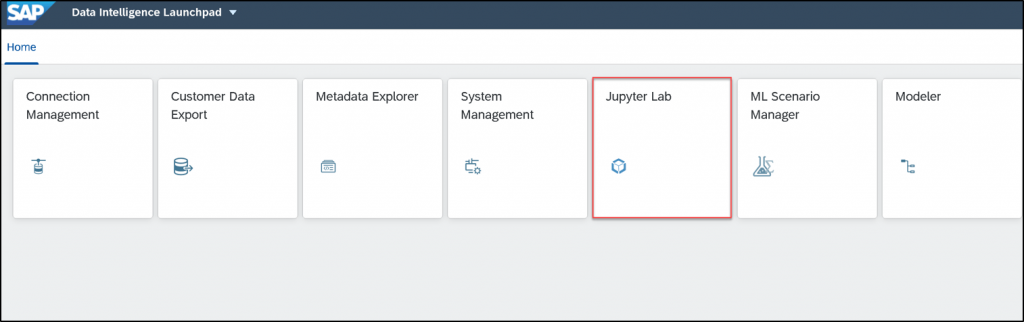
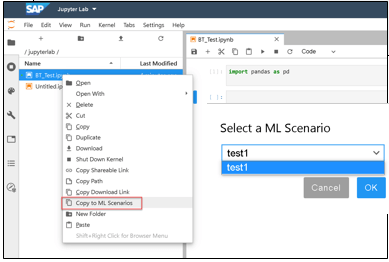
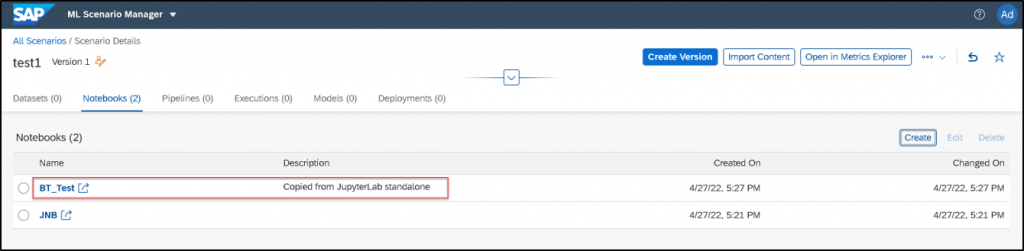
BUSINESS VALUE – BENEFITS:
- Jupyter Lab app has its own tile on the Launchpad
- Enabling of its usage independently of ML Scenario Manager, without necessarily affecting any of the existing scenarios in MLSM
- associate Jupyter Lab Notebooks to an existing ML Scenario
These are the new functions, features and enhancements in SAP Data Intelligence, cloud edition DI:2022/05 release.









