SAP HANA (In fact Any DB which implies with SAP), SAP’s in-memory database system is extremely rich in features and has the capacity to process several terabytes of data without a sweat. As data volumes and size is growing exponentially, customers/corporate ITs are now in various stages of considering migrating to SAP on HANA.
While building the business case for such migration, we need to most definitely consider implementing some proven best practices to bring down the overall cost of such migration. One such best practice is the archiving of SAP data before the migration. With the larger size of structured and unstructured data, the need to archive SAP data is very critical but not often discussed best practice.
There are several reasons why this is a best practice to implement now:
SAP Charges on HANA based on volume: The more data you’ve got to process, the more expensive it’s going to be.
Data supposed to grow will be a certain intrinsic value. Any data that is seldom used should be archived to have a good performance for SAP HANA. Therefore, one needs to create a plan to archive old, not often used data that is not critical to on-going real-time operations. A spare system always brings down costs at the time of SAP migration.
SAP HANA stores data on a persistence layer (data and logs). When you start your database the data is loaded into the physical memory. Not all the data is loaded into the memory at this moment. Only those tables that have the PRELOAD flag enabled will be loaded into the memory. It is also possible to enable the PRELOAD flag just for some columns of the table.
The SAP HANA database will load tables and columns into memory when those are required. This could happen because of explicit access, explicit load, index load/recreation after optimizing compression, etc. For example, if I execute a SELECT * FROM TABLE and I have enough memory that table will be fully loaded into memory in case it wasn’t. If it is a huge table (like tens or hundreds of GB) then OOM situations could appear.
On the contrary, HANA unloads tables from memory in certain situations. For example, when the SAP HANA database runs low on memory, on MERGE/SHRINK situations or when the UNLOAD of the table was explicit. A high number of loads/unloads could affect the performance of the system since the database have to bring the table/columns before the process using it can access it. You can read a lot about LOAD/UNLOAD operations in SAP HANA in the SAP Note 2127458 – FAQ: SAP HANA Loads and Unloads.
Remember, in SAP HANA the size of a table usually means a memory requirement so the database can load the table in memory. If the table doubles its size on the persistent layer that will mean that if we want to load that table in the physical memory we will need a double amount of memory. This is not 100% accurate but it helps to describe my idea:
Size of a table = Space on the persistent layer = Physical memory = Money
If we don’t archive or delete data from our database sooner or later we will run out of memory. When HANA runs of memory when OOM situations start to appear and people scream because the process is being canceled. Also, if we run Calculation Views on the SAP HANA database (for example from a BW Load Chain) the number of rows managed by the calculations views will increase. This means that the calculation view will take more memory to be processed, more time to finish, etc.
An enormous amount of data growth in SAP Systems causes degradation of system performance and user productivity. high costs due to larger storage volumes with high redundancy as well as administration costs due to long backup and maintenance windows. Nevertheless or furthermore being said, larger databases cause longer system downtimes during upgrades and restorations.
Benefits of DATA Archiving
- Reduces cost of infrastructure (storage, memory, and computing)
- Reduces administration costs
- Ensures cost-efficient system upgrades and migrations
- Improved SAP Application performance.
Data Archiving, in general means moving huge volumes of the data that is no longer required in the database to some file system or any third-party storage system. It is functionality provided within SAP applications for the consistent removal of data objects from database tables of the SAP database, where all table entries that characterize a data object are written to an archive file outside the database.
Data Archiving only “frees up” space in the database during the archive delete job
To actually, reduce the database size:
- Index Reorganization
- Tablespace Reorganization
“Archiving” refers to the process associated with copying data and supporting documents from an active system (SAP) to an external source (Open Text) for the purpose of deletion and/or storage for later retrieval.
There are basically 2 approaches suggested by SAP to archive data:
- SAP Classical Archiving
- ILM (Information Lifecycle Management)
Here in my blog post will be covering only ‘Classical Data Archiving’ at present scenario:
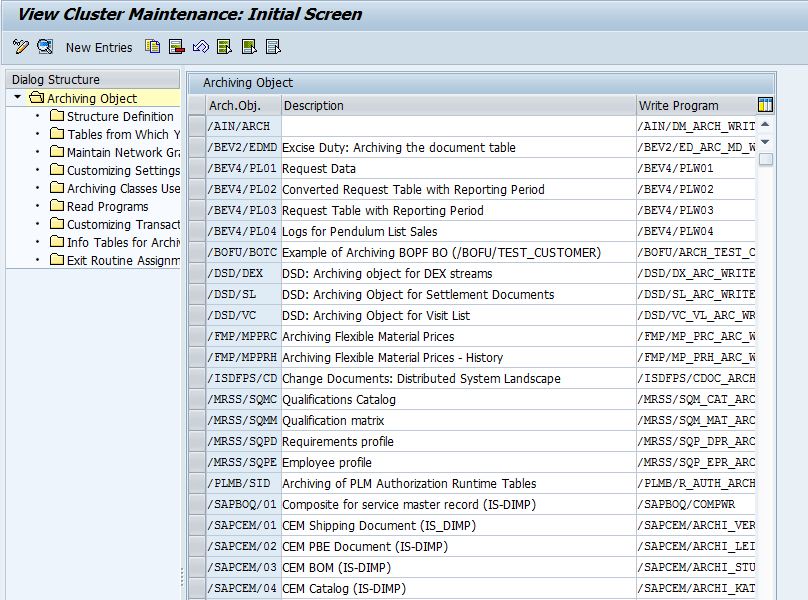
What is an Archiving Object?
Archiving objects is a central component of SAP Data Archiving. Archiving Object specifies which data to be archived and how. The archiving object directs the SAP Archiving system to get the correct tables to be associated with the specific business object. The archive object can be 10 characters long in length.
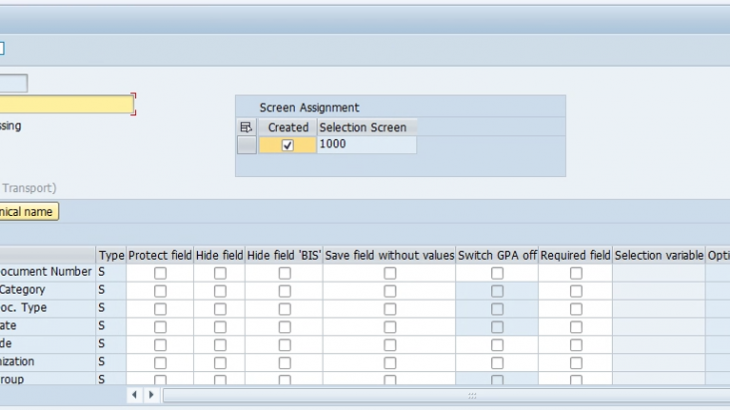
Archiving objects are defined using Archive Object Details (AOBJ):
We set the following parameters for each of the Archiving objects –
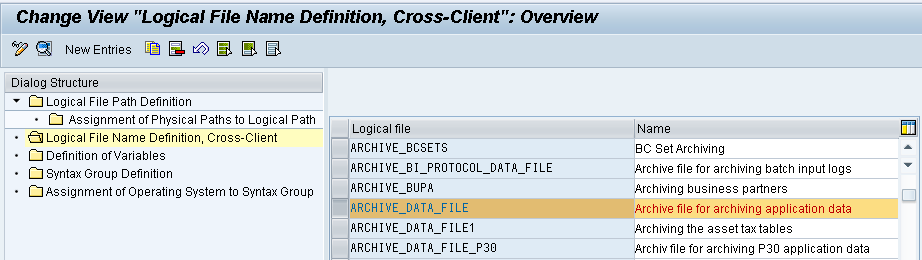
Logical File Name
Logical file name for the archive file in which the data is stored, platform-independently.
Note: The logical file name must already have been maintained with the transaction FILE (Definition of logical file paths).
Archive File Size
If one of the following parameters is exceeded when writing the archive file, the system closes it and automatically creates a new one:
- Maximum Size in MB
- Maximum number of data objects
Note: The maximum size of an archive file is 2048 MB.
Settings for the Delete Program
– Commit Counter
Number of data objects after which the delete program performs a COMMIT WORK
– Test Mode Variant
Test Mode Delete Program Variant
– Production Mode Variant
Production Mode Delete Program Variant
Delete Jobs
– Do Not Schedule
The delete jobs are not started automatically.
– Start Automatically
The delete jobs are started immediately after the write program has created an archive file. The delete and save phase sequence can be:
– After event
The delete jobs are started by an event. The field Event must contain the name of the event which is linked to the delete job. If the event requires a parameter, it must be in the field Parameter.
– Create Index
Determines whether the data objects to be archived are put in the ADK Index.
Postprocessing Program Settings
If you have selected an archiving object which uses a post-processing program, you can maintain the following parameters here:> Production Mode Variant
Production Mode Post-Processing Program Variant> Start
Automatically determines whether the post-processing program is to be called automatically after deletion.
Saving File in Storage System
If your system has a storage system, and you want to save the files in it, you can make the required settings here:
– Content Repository
Content repository name
– Start Automatically
Determines whether an archive file is to be saved in the content repository automatically.
Sequence
This time saving in the content repository is determined by the sequence in which the archive files are processed after their creation:
- Delete Phase before Saving
The archive files are saved in the content repository after the delete program has processed the file in production mode. If the delete program is in test mode, there is no automatic save afterward.
- Save before Delete Phase
The archive files are saved in the content repository after the write program has created an archive file before the delete program starts. The delete program can only process the file after it has been saved. The Delete Program Reads from Storage System flag controls whether the delete program reads the data to be deleted from the archive file in the storage system, or in the file system.
Note: If Start Automatically is selected in the delete program settings, the delete program is called after saving the file. It makes no difference whether the delete program is in test or production mode. Analogously, the delete jobs are scheduled and started automatically after the event, if After Event is selected.
Save your entries and go back to the initial screen of the transaction AOBJ.
Important settings to set
- Max size in MB or the max objects
- Check the variants (some variants for production have still deliberately the test tick box as on: you have to change it)
- Best to leave the delete jobs to Not scheduled (large archiving runs can create many files and many deletion jobs to kick in at the same time): best to do this manually in a controlled way
- Start storage automatically or manually is a choice for you
- Best to store before deletion. This is the most conservative setting.
- Best to delete only from the storage system: if file is not stored properly in any way, deletion will not have. This is the most conservative setting.
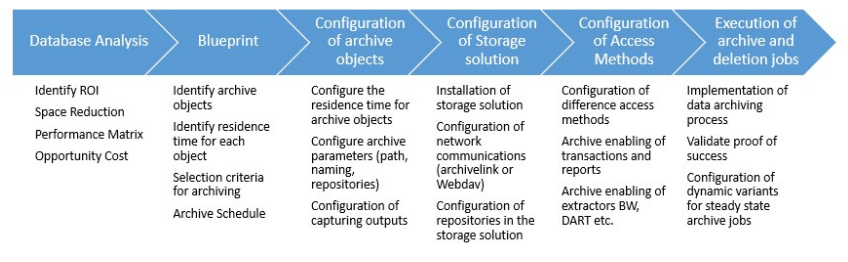
How to Identify Specific Objects to be Archived?
There are other ways to reduce the memory used by a SAP HANA database. I want to focus on archiving and deleting data since they are two of the easiest way to reduce the memory consumption. The next step is to know which tables we can reduce and how to do it. First, about knowing the tables we can use the following options:
- Perform a DVM (Data Volume Management) Analysis Report on a Solution Manager 7.2 for the SAP HANA Database and the SAP system using the database. Basically the Solution Manager will connect to the database, check the biggest tables and provide some recommendations that we can follow to reduce its size. The DVM configuration is super easy, just follow the wizard on the Solution Manager.
- Check the biggest tables in the SAP HANA Database and find notes and procedures to archive/delete data. We can do it in different ways:
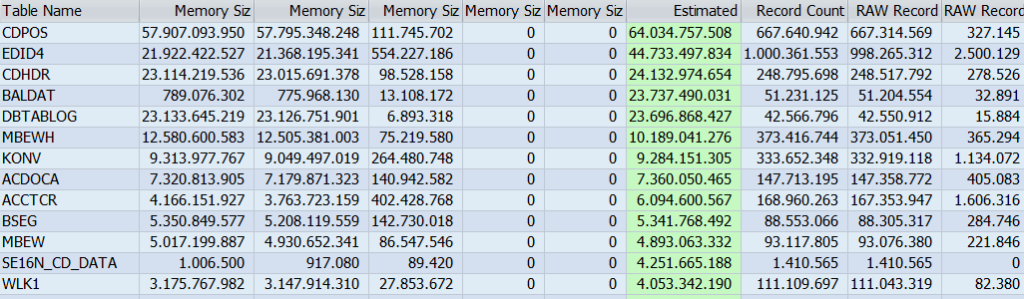
- Using transaction DB02 and the option System Information – Large Tables. Order by Estimated max Memory Size in Total and Top Space Consumers.
- Using the SAP HANA Mini Checks in the SAP HANA Studio.
- Using Transaction TAANA (which stands for Table Analysis: Administration) helps identify the distribution of data within a table. TAANA can also identify the volume of archivable data and any archive file routing requirements.
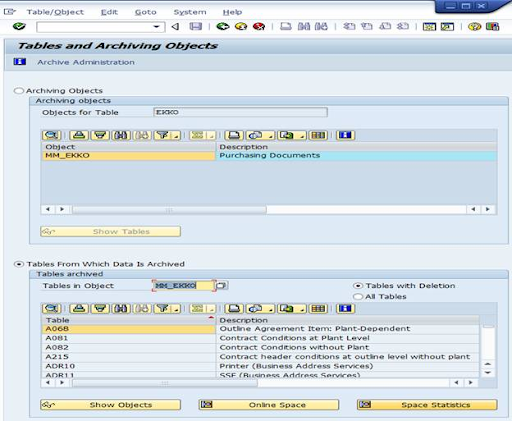
- Using Transaction DB15 is used to identify Archive Objects. If you know the database tables or if you know the archiving object it displays the list of associated database tables for that particular Archiving Object.
- Also, analyze performance with transaction ST03N for possible archiving objects. E.g., Material documents table MSEG can be a very large table, and archiving MM_MATBEL can improve runtime for MB51).
- Using transaction DB02 and the option System Information – Large Tables. Order by Estimated max Memory Size in Total and Top Space Consumers.
Tx. DB02:
Tx. DB15:
Configuration of Archive Objects
For creating custom Archive objects, go to Tx. AOBJ -> Click on ‘New Entries’.
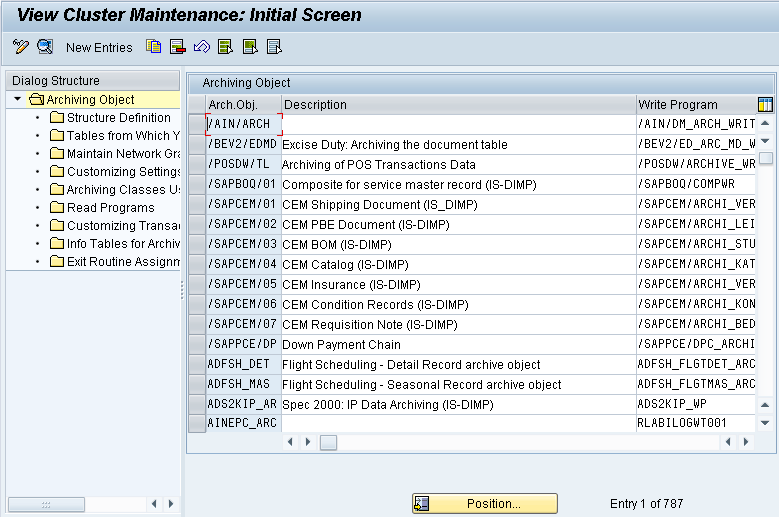
1. Structure Definition
The Structure definition contains the list of the database tables from which the data will be archived. This is pre-configured for the Standard SAP Archive Objects.
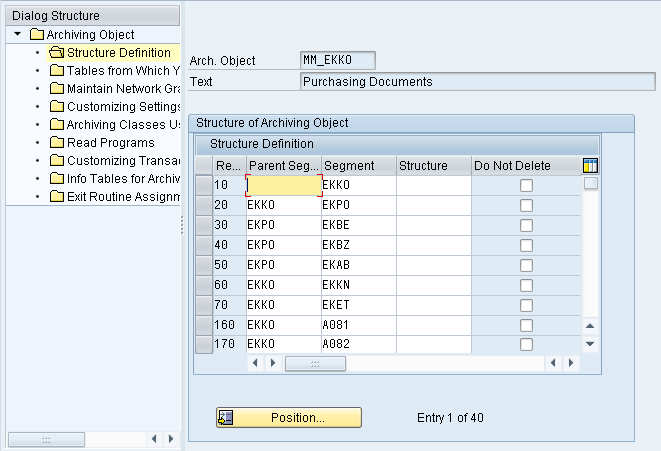
2. Tables from which you only Delete Entries
This contains the list of Database tables from which the data will be only deleted and not archived. This is pre-configured for the Standard SAP Archive Objects.
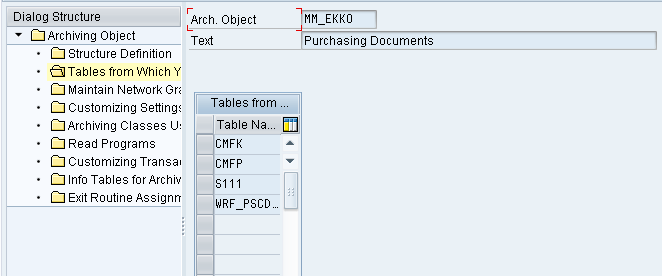
3. Maintain Network Graphic
This contains the list of pre-requisite Archived Objects that need to be archived before the actual archive objects. This is pre-configured for the Standard SAP
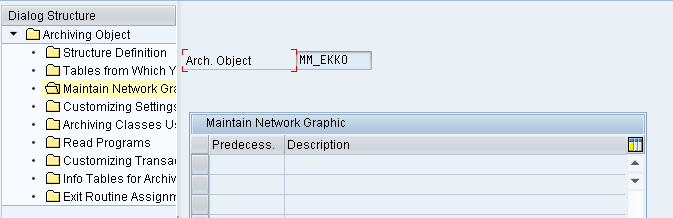
4. Customizing Settings
This should be configured as per business requirements. This contains details about Archive File Size, Setting for Delete programs like Test Mode Variants and Live Mode Variant (i.e., Production Mode Variant), Content Repositories, and the sequence of deletion If the radio button ‘Start Automatically’ for Delete Jobs is selected, automatically the delete program is executed after the write program. If not selected, execute the delete manually for the particular archiving object.
5. Archiving Classes Used
This contains the details about the Archiving classes used by the particular Archiving Object.
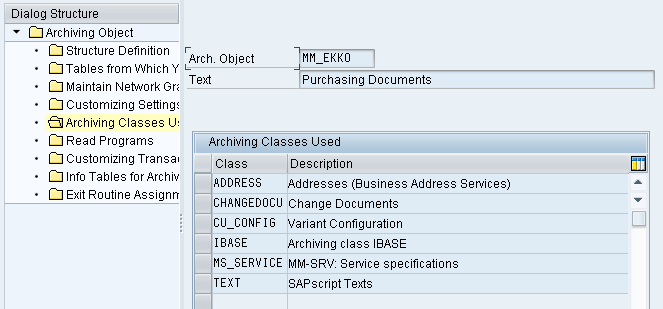
6. Read Programs
This contains the details about the read programs which is used by both the archiving objects and archiving class to read the data from the Archive Files.
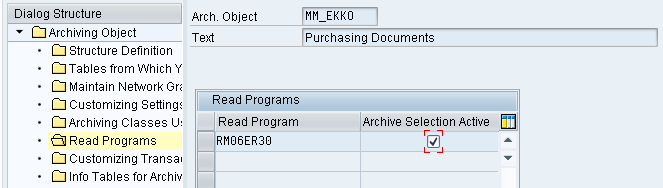
7. Customizing Transactions
This contains the transaction code for the application-specific customizing for the relevant archiving object. Once this code is entered, you can go directly from transaction SARA to the application-specific Customizing transaction, which is often used for entering residence times for an archiving object.
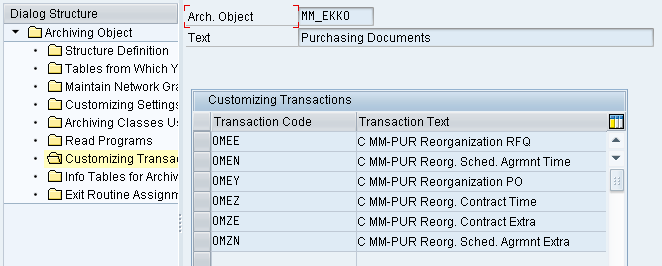
8. Info. tables for archive files
This contains the list of database tables that will give the archive file name, the criteria for archiving, and other related information.
9. Exit Routine Assignment Generation
This contains details about the customizing code (user exists / Business add-in) in the archive and delete programs.
Archive Programs
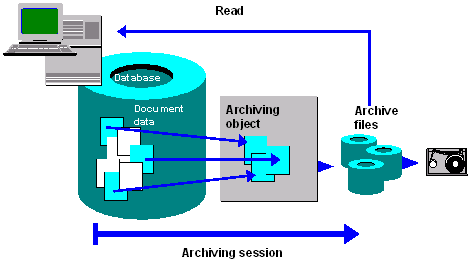
The mentioned programs in the SAP system should be assigned to the Archiving Objects.
1. Preprocessing (Optional)
This program prepares the data for archiving making the data setting for deletion indicator to X, but it does not delete any data from database. It just operates with database.
2. Write
It creates new archive file and writes the data in them. At this point, no data is been deleted from the database. The write programs can be executed in two processing modes.
- Test mode
- Production mode
In Test mode, no archive files will be created whereas in Production mode, Archive files will be created.
3. Delete
This program reads the data from the archived files and deletes the data from the database. The delete programs can be executed in processing modes:
- Test Mode
- Production Mode
In the Test Mode, the log after the execution shows the entries of the data to be deleted from the database, whereas in the Production Mode it shows the statistics of the deleted data from the database.
4. Post Processing (Optional)
It also operates on the Database and does not require any Archive files. This is final program can be executed asynchronously with the delete program.
5. Reload Programs (Optional)
This program is used to reload the archived data from the external storage system back into the respective SAP Database tables. It is not available for all the archiving objects.
Note: For audit purpose , we revert the data to database.
6. Index Programs (Optional)
This program builds or deletes an index that allows individual access. Infostructure created for archive objects (via SARI) acts as index to the archived data.
Check Archivability
Checking the Archivability of the Business objects precedes the actual archiving process. This should ensure that the data is not archived if some other application still needs it. The business objects are considered to be archivable if it:
1. Is completed (Cross-Archiving object Check Program or Archiving object-specific check/preprocessing program). If a business object meets Archivability criteria, it is set to status “Archivable” and can be written to the archive.
2. Has reached the desired residence time
3. Does not serve as the basis for business objects for later updating in database.
Residence Time: Amount of data which will be available in online before it meets Archivability criteria.
Retention Time: It is the entire time where data spends in Archive format before it gets deleted from the actual database.
Setting up connection between the ERP System and the External Storage System
1. Maintain the Content Repository (OAC0)
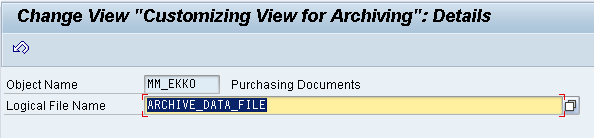
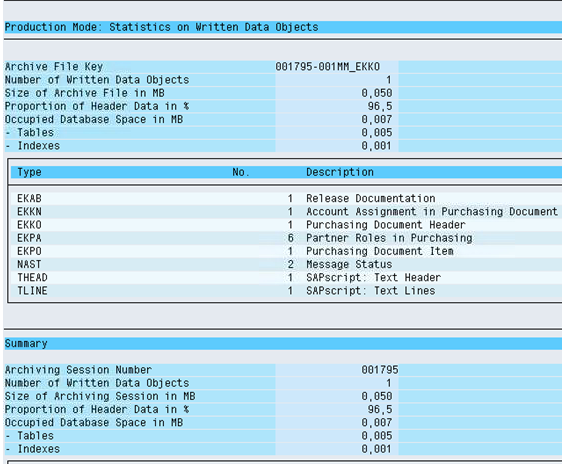
The contain repository is maintained for every archiving object. Below is the content repository maintained for MM_EKKO.
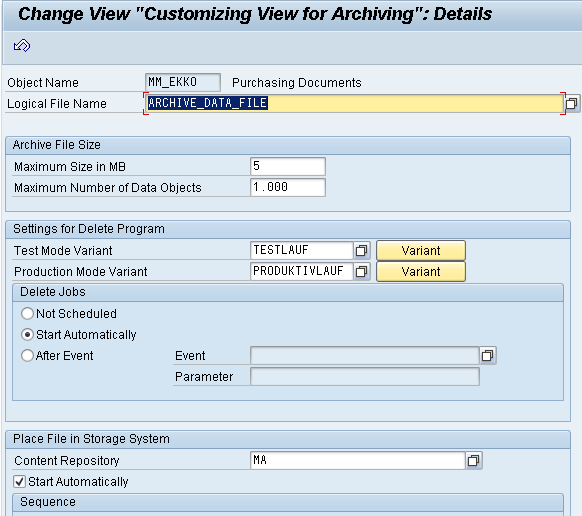

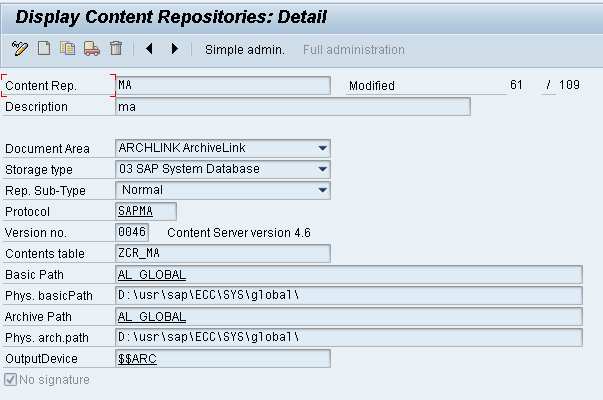
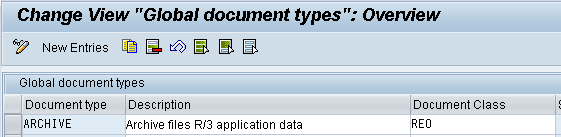
2. Maintain the Document Type (OAC2)
The document type is maintained by Tx. OAC2. Every Archiving Object is associated with the document type which is in turn linked to document class. The document class identifies the archive format for the document in the Content server.
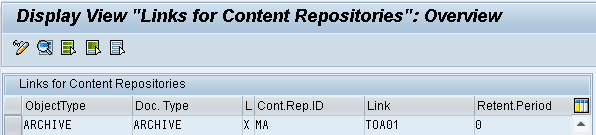
3. Linking the Content Repository to Document Type (OAC3)
In transaction OAC3, the content repository will be linked to Document Type.
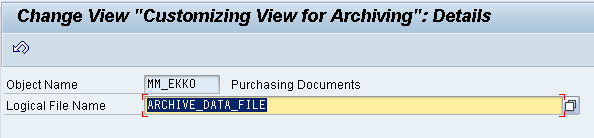
4. Maintain the Logical Filename (FILE)
Archived data is stored in archive files in the file system/3rd Party Storage (Like PBS Software etc.)
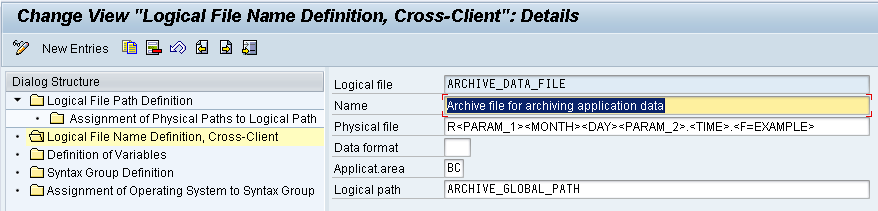
If an Archive file is created by the write program, then it’s a physical file name is derived from a logical file name.
In the same way, the physical pathname is derived from a logical pathname. The logical file name and the logical path should be maintained to get an appropriate physical file name and physical pathname.
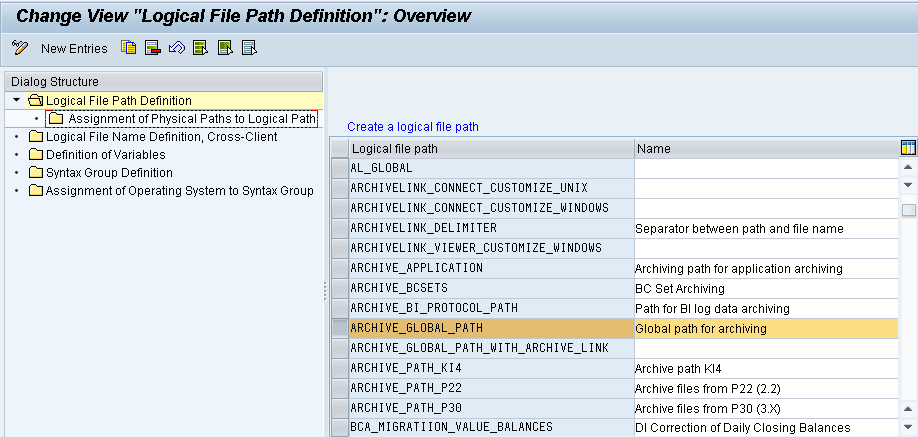
- Defining a Logical Path Name:
First, determine the target directory in which you want to create the archive files of a certain archiving object. The physical name of the directory is stored in a logical pathname.
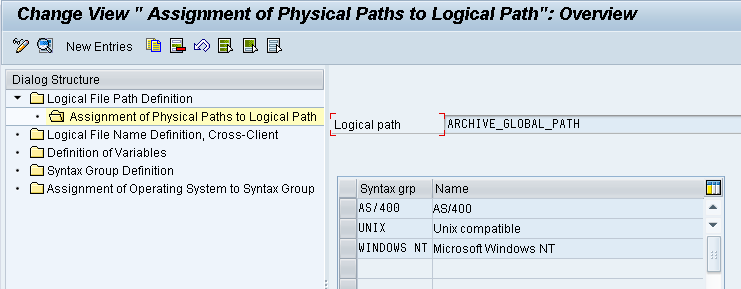


Suppose, You have created a subdirectory called “archiving” for archive files in the global directory. The physical pathname should be defined as follows:
<P=DIR_GLOBAL>/archiving/<FILENAME> (syntax group UNIX)
<P=DIR_GLOBAL>\archiving\<FILENAME> (syntax group WINDOWS NT)- Defining a Logical File Name:
- Assign a Logical File Name to the Archiving Object:

Step by Step Procedure for Data Archiving
1. Go to Tx. SARA, and enter the Archive Object. Example: MM_EKKO (Purchase Documents)
Click on the ‘Preproc’ button. This step is optional.
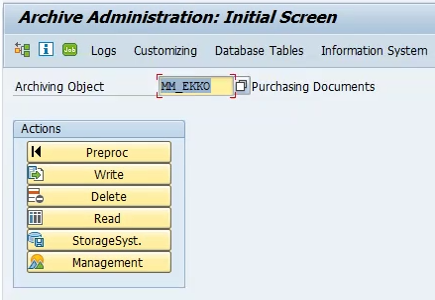
2. Give the variant and click on the maintain button. Next screen is displayed.
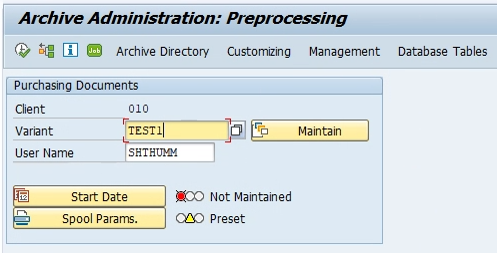
3. Select the parameters as shown below and click on continue.
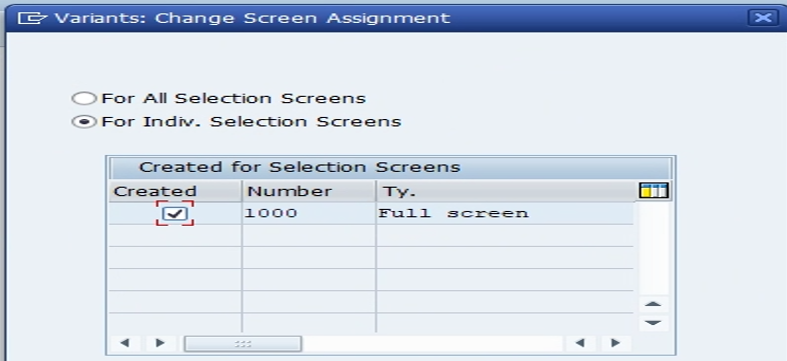
4. This is the selection screen for Preprocessing. Provide the selection criteria as per the requirements and click on “Attributes”.
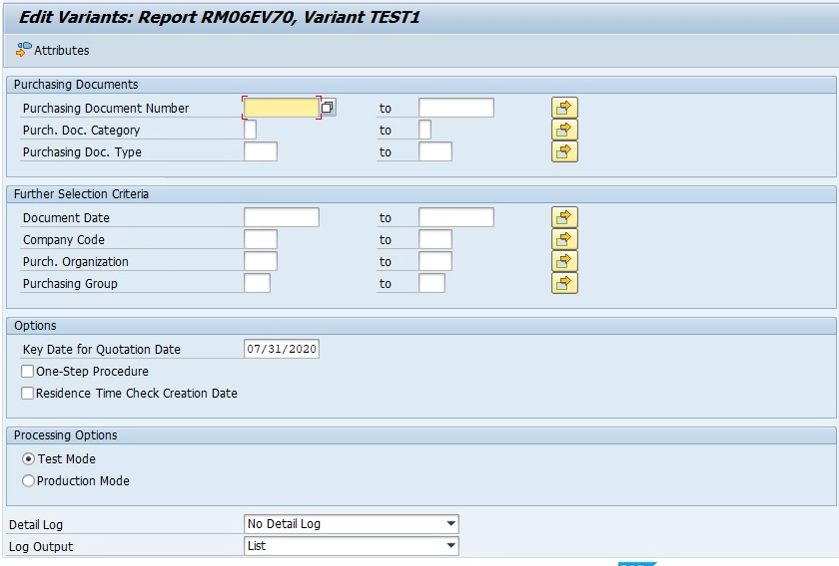
5. Give the meaning for the variant here and click on “save”
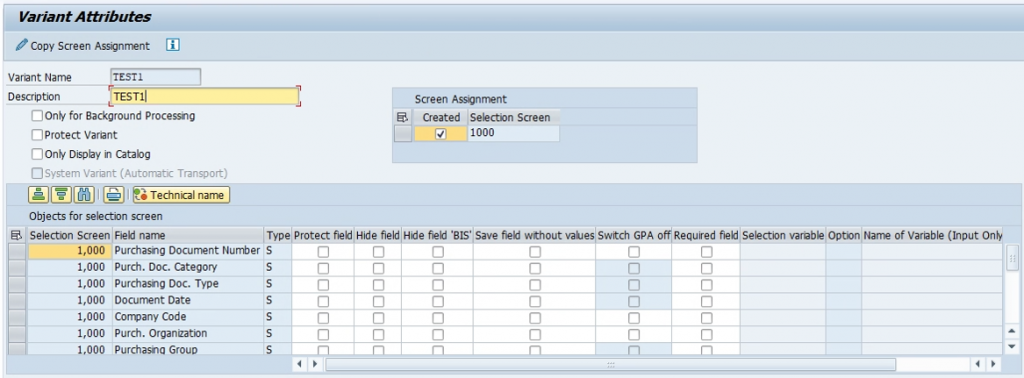
6. Go back to initial screen. Click on ‘Start Date’ Button.
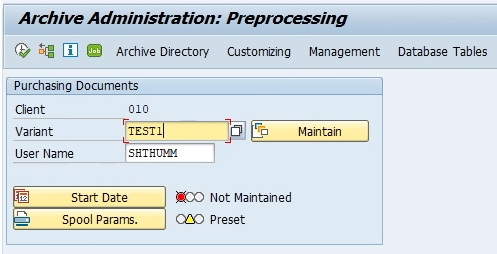
7. Click on ‘Immediate’ button to schedule the background job and save.
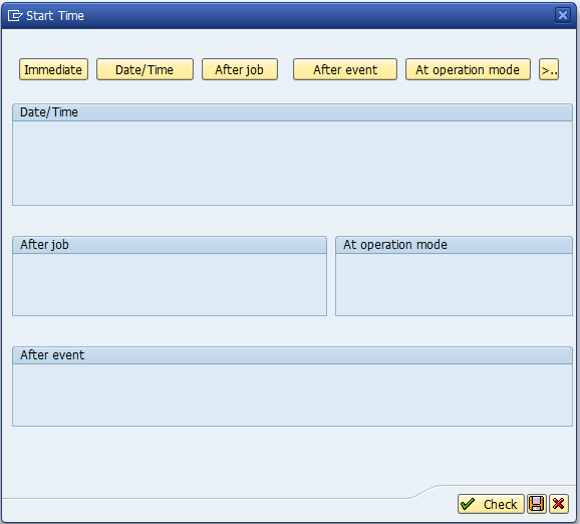
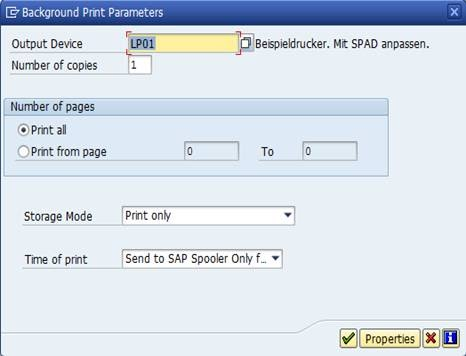
8. Now click on Spool Params and set the printer here.
9. The initial screen is now displayed as below in green status.

10. Click on ‘Execute’

11. Repeat the same procedure from 2 to 10 for Archiving object MM_EKKO (Purchase Documents) using write program by maintaining the Variant ‘TEST2’ along with same selection criteria as given for preprocessing program and click on ‘Execute’ button.

12. Click on ‘Job Overview’ button to see the archived session.
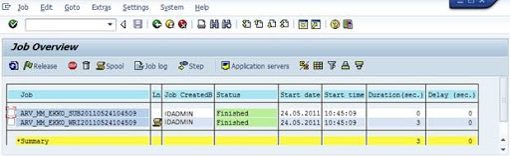
The above preprocessing and write jobs are in below format:
ARV_MM_EKKO_SUB* * * * * * *
ARV_MM_EKKO_WRI* * * * * * *
For remaining storing and deleting jobs are performing with the same process as did for preprocessing and write programs. Below are the jobs where it is triggered for remaining programs for various Archive objects MM_EBAN, MM_MATBEL and completed successfully.
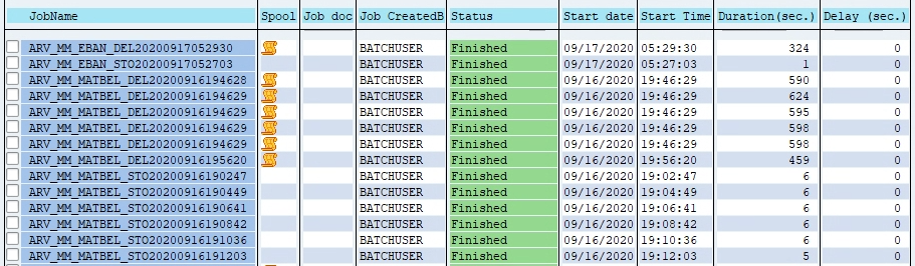
13. Select the Job and Click on the Spool to view the output.
Accessing the Archived data
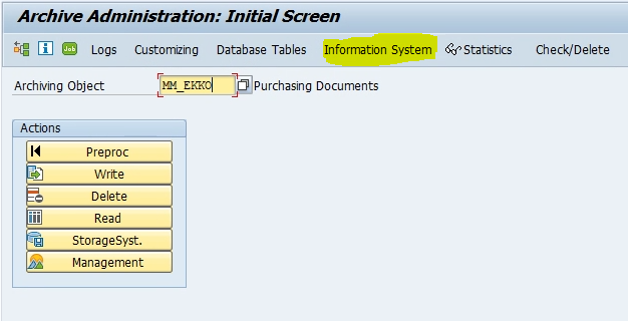
Users can access the archived data by Archive Information system (Direct Tx. SARI).
Users can check the Archive Information system by clicking on the ‘Information System’ button in the Archive Administration (Tx. SARA).
Creating an Infostructure
Every Archive file accessed using Archive Information System is through Infostructure. Every Infostructure belongs to a unique Archiving objects and also refers to the field catalog. A field catalog is the collection of fields suitable for indexing the archive files of Archiving object concerned. All the data related to Infostructure is maintained in database tables.
For creating an Infostructure, we use Tx. SARJ, or clicking on “Customizing” button in the Archive Information system: Central Management.
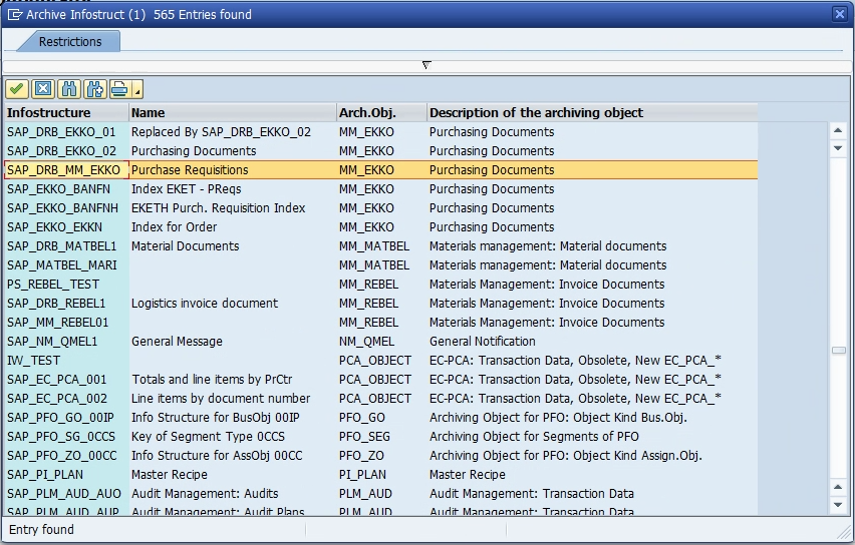
Note: The standard Infostructure SAP_DRB_MM_EKKO is used here.
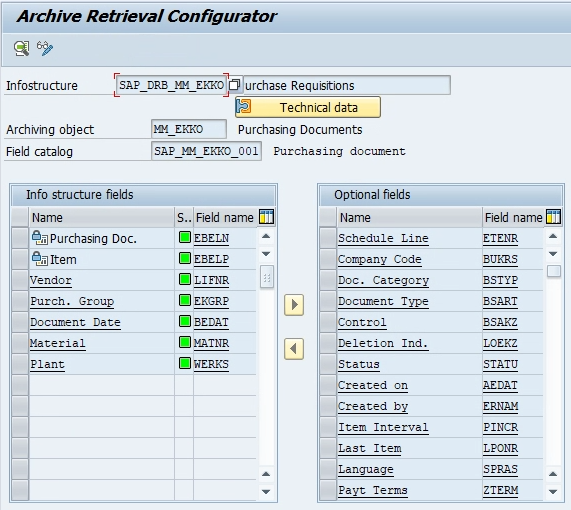
Activating an Infostructure:
To use an Infostructure, the user must activate the Infostructure. All the standard Infostructure will be already activated. Only after activating the Infostructure it can be filled with data from an archive file and evaluated.
Once the Infostructure is activated, it cannot be modified.
Evaluating an Infostructure:
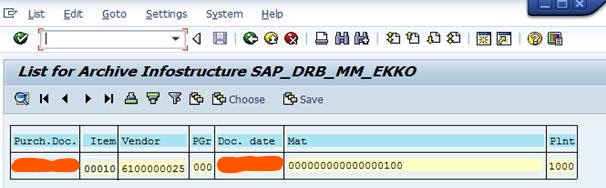
The data from the archive files can be retrieved using “Archive explorer” by Tx. SARE, or by clicking on “Archive Explorer” button in the Archive Information System.
The archived data is displayed as below:
Best Practices for Archiving objects
The most common approach is to implement archive objects in this order:
- Technical (IDOCs, Application Logs, etc.)
- Transactional Data (Financial, Sales, etc.)
- Master Data (Materials, Sales, Shipment documents, etc.)