Background
SAP Datasphere released replication flows starting from SAP Datasphere version 2021.03. This new capability allows one to copy multiple tables from a source to a target in a fast and seamless way.
This blog will demonstrate how to replication data from SAP sources to Google BigQuery.
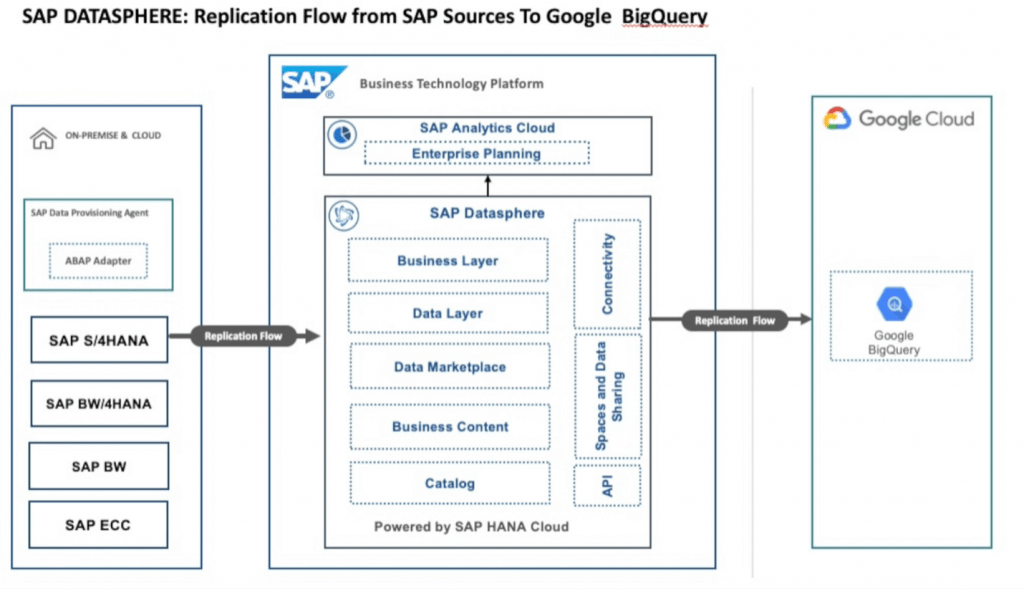
Steps
- To start, you will need to create a connection in SAP Datasphere to Google Big Query.
- Make sure you have a Dataset in Google BigQuery that you want to replicate the tables into.
- Make sure you have a source connection. In this case, we will be using S4 Hana Cloud. You will need to create this connection in the Connections tab in SAP Datasphere.
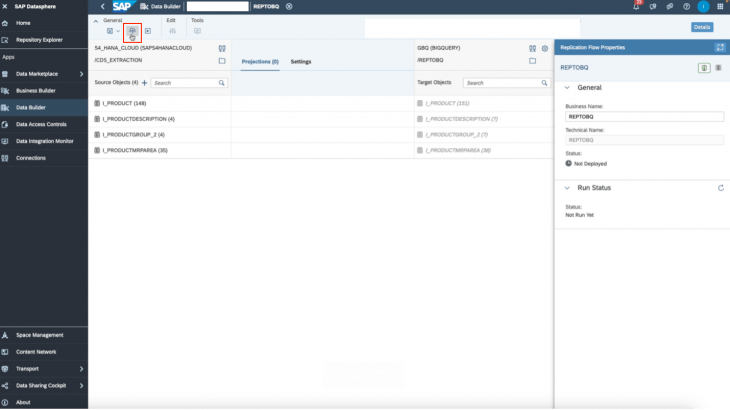
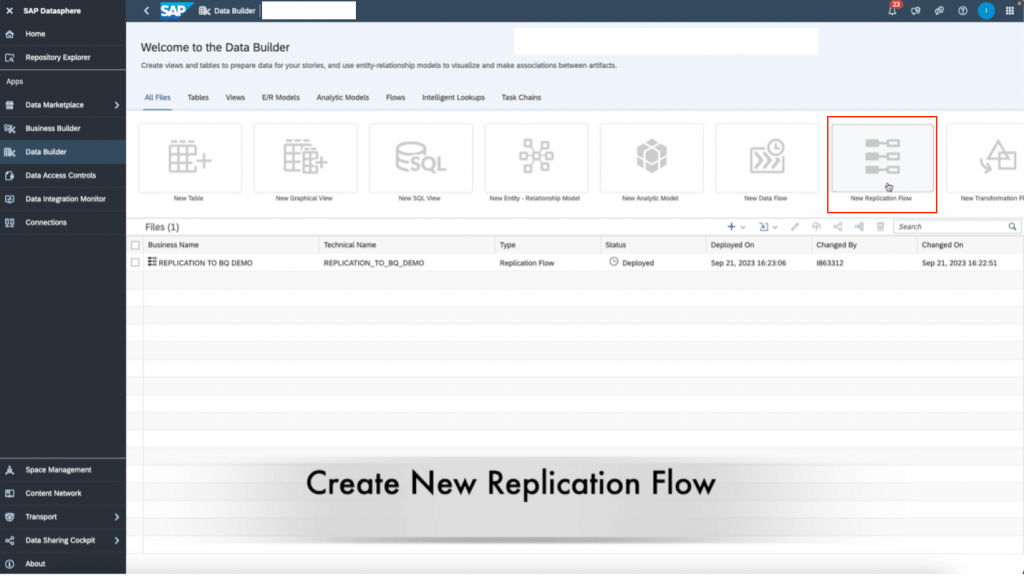
- Navigate to SAP Datasphere, and click on Data Builder on the left panel. Find and click the “New Replication Flow” tile.
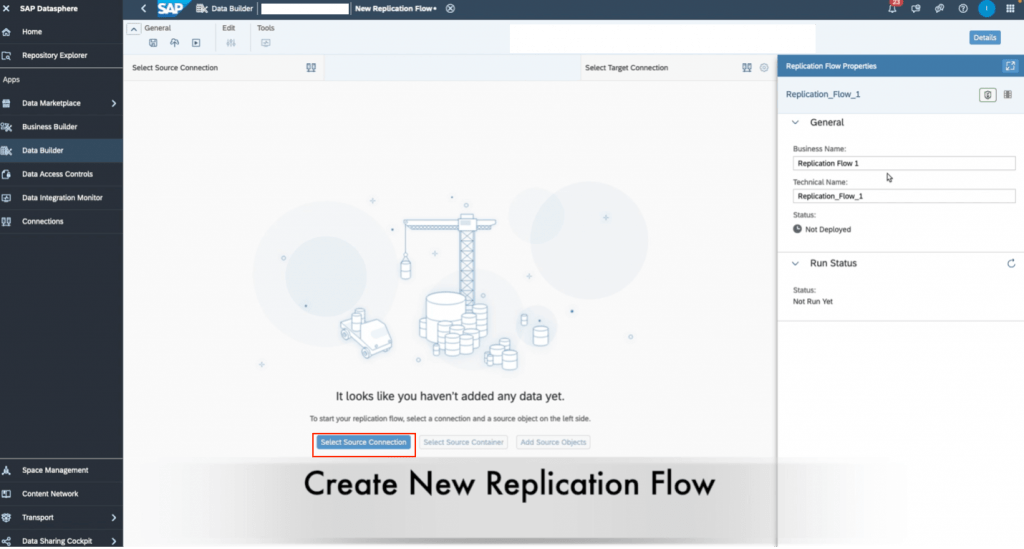
5. Click on Select Source Connection
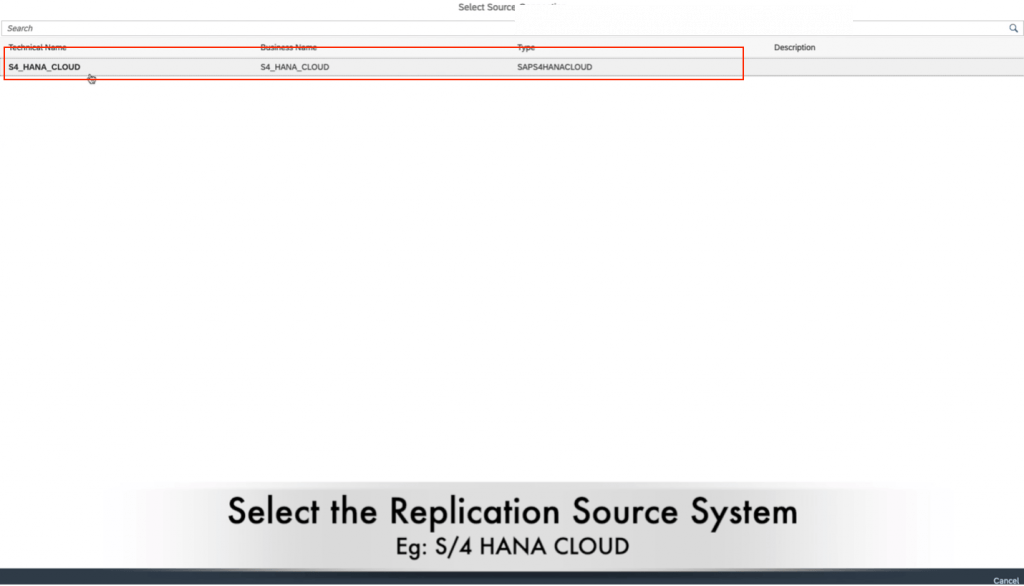
6. Choose the source connection you want. We will be choosing SAP S4 Hana Cloud
7. Click select Source Container.
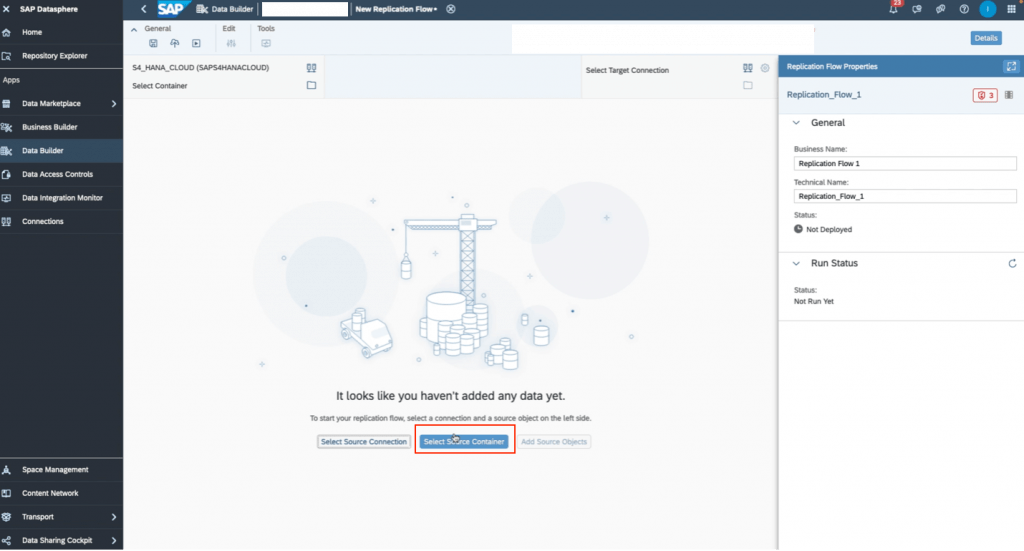
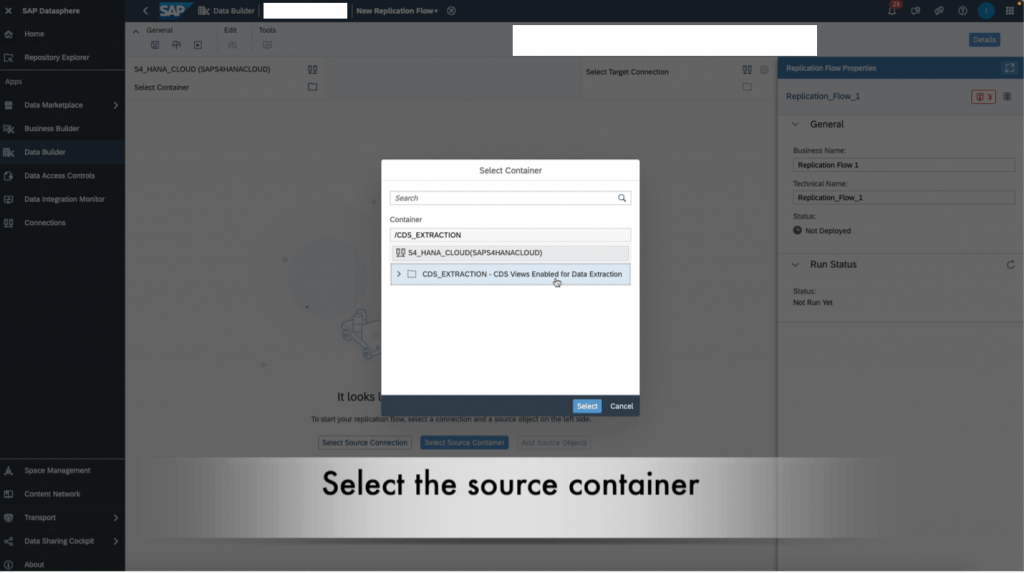
8. Choose CDS Extraction – CDS Views Enabled for Extraction and then click Select.
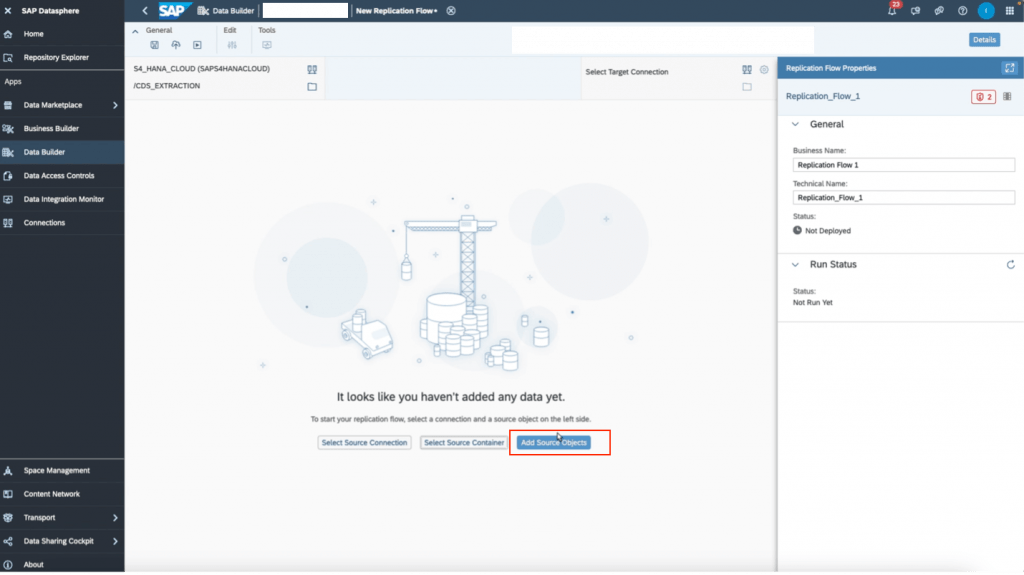
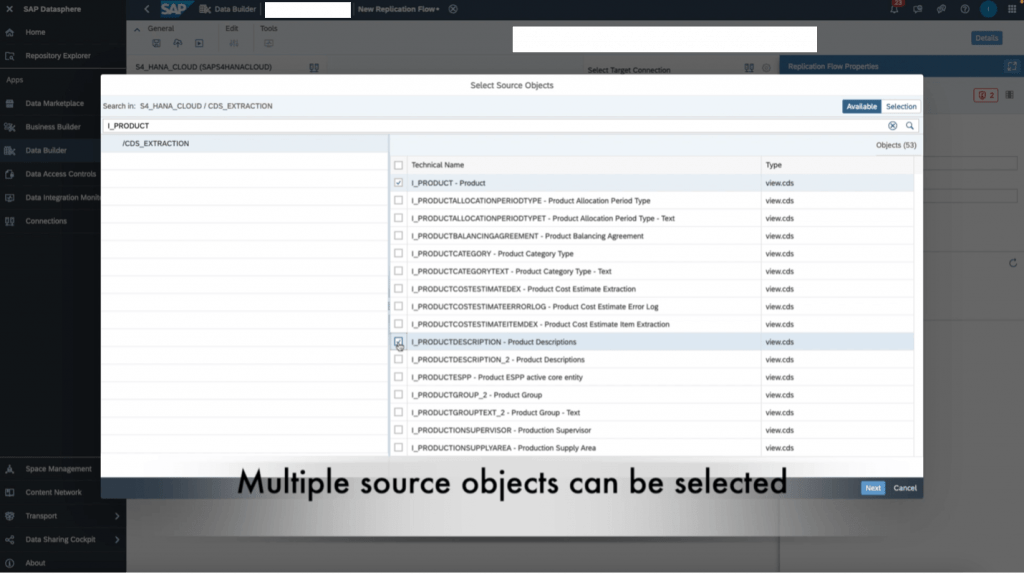
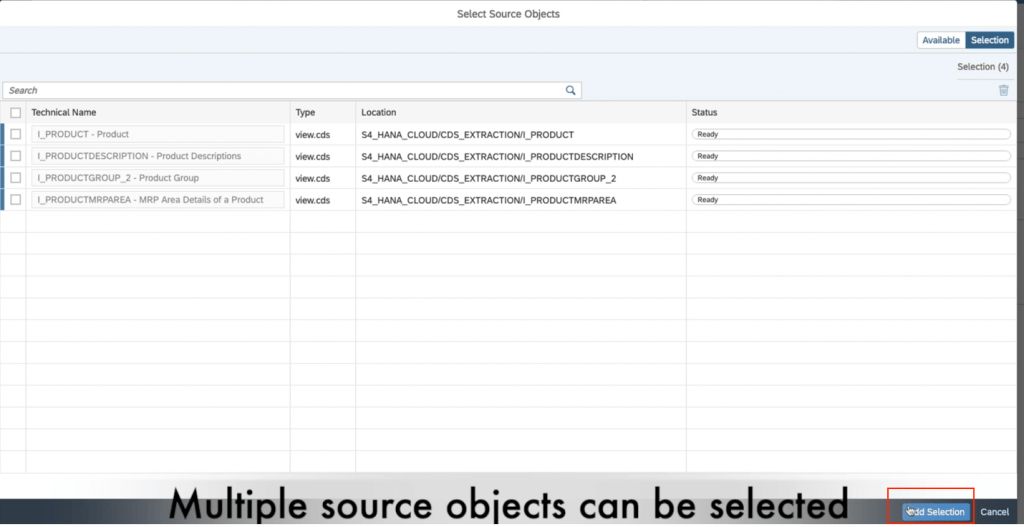
9. Click “add source objects” and choose the views you want to replicate. You can choose multiple if needed. Once you finalize the objects, click add selection.
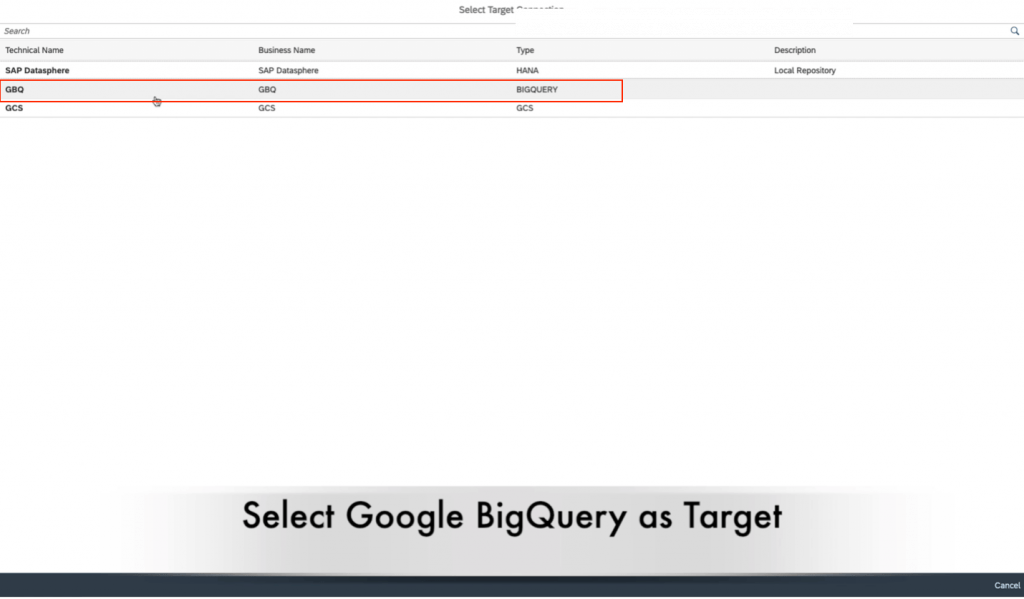
10. Now, we select our target connection. We will be choosing Google Big Query as our target. If you experience any errors during this step, please refer to the note at the end of this blog.
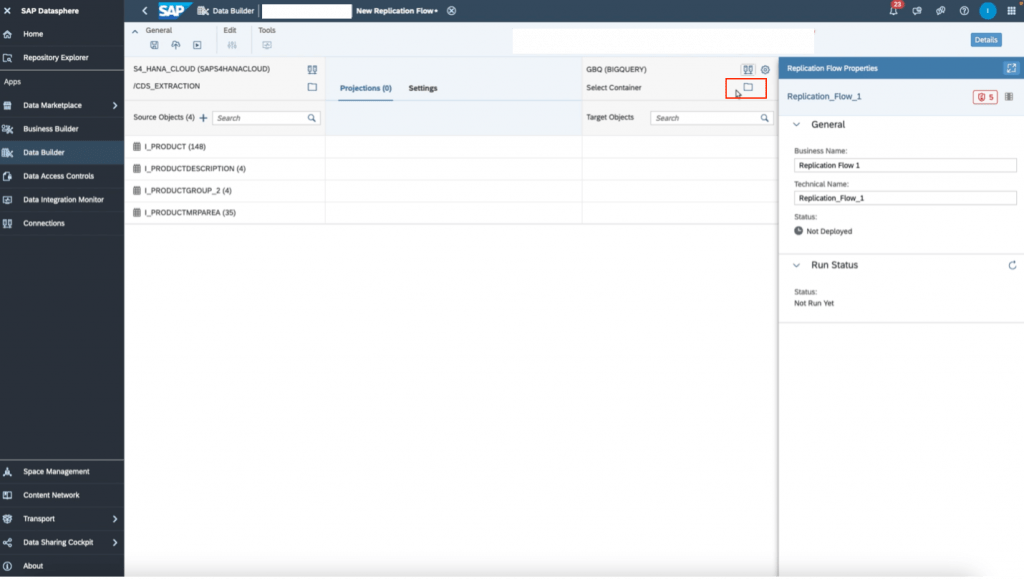
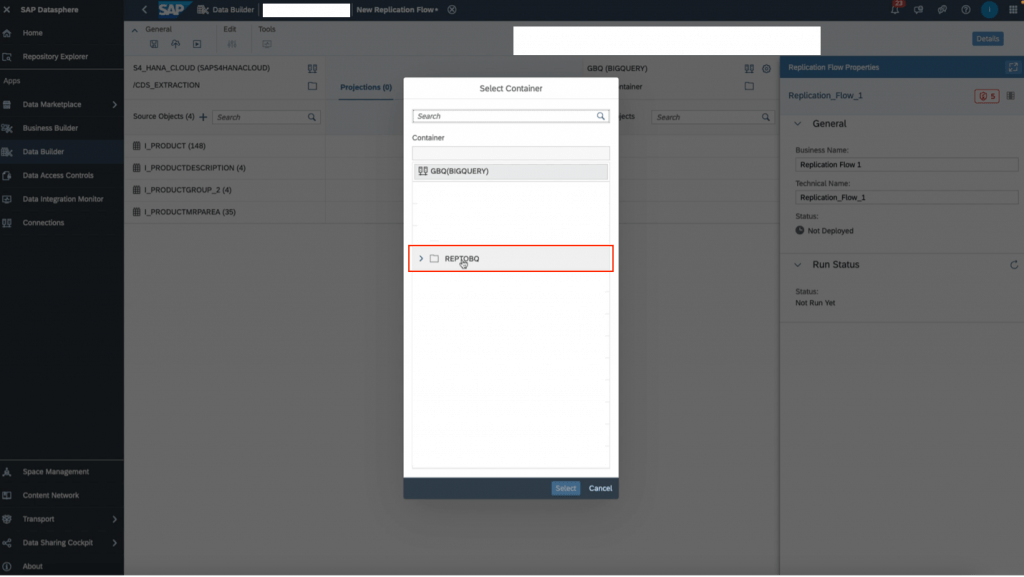
11. Next we choose the target container. Recall the dataset you created in Big Query earlier in step 2. This is the container you will choose here.
12. In the middle selector, click to”settings” and set your load type. Initial only means to load all selected data once. Initial and delta means that after the initial load, you want the system to check every 60 minutes for any changes (delta), and copy the changes to the target.
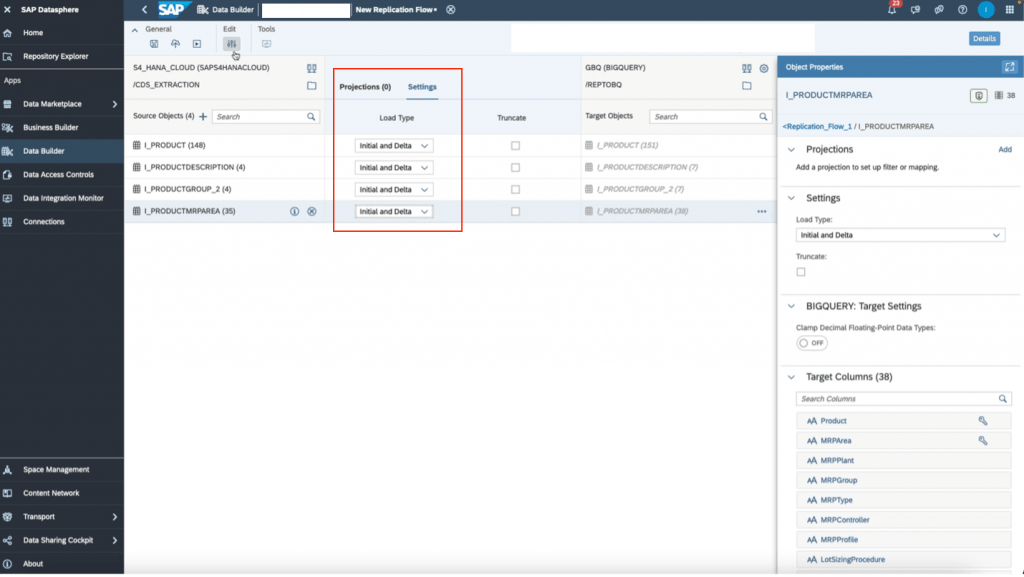
13. Once done, click on the edit projections icon on the top toolbar to set any filters and mapping.
14. You also have the ability to change the write settings to your target through the settings icon next to the target connection name and container.
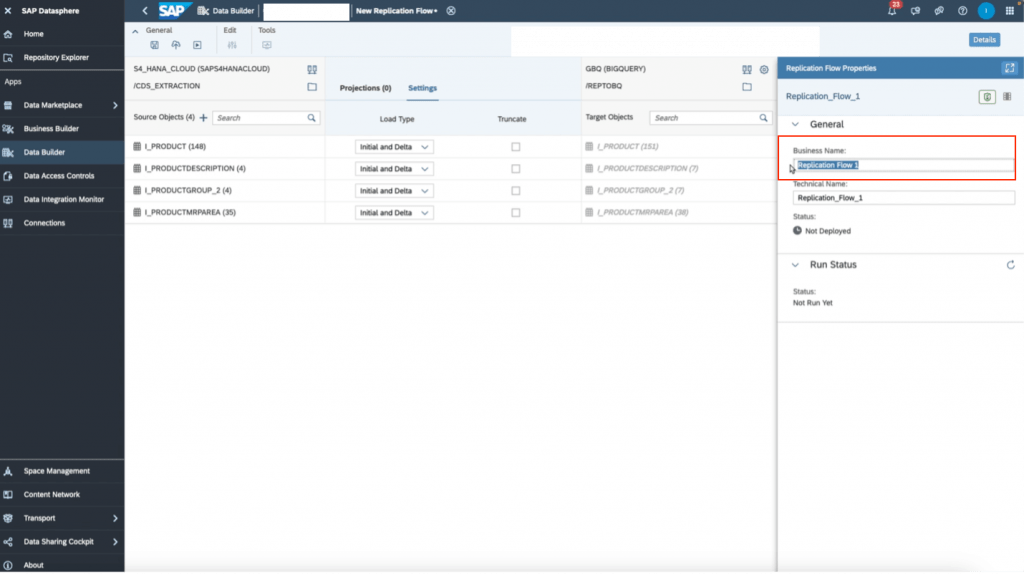
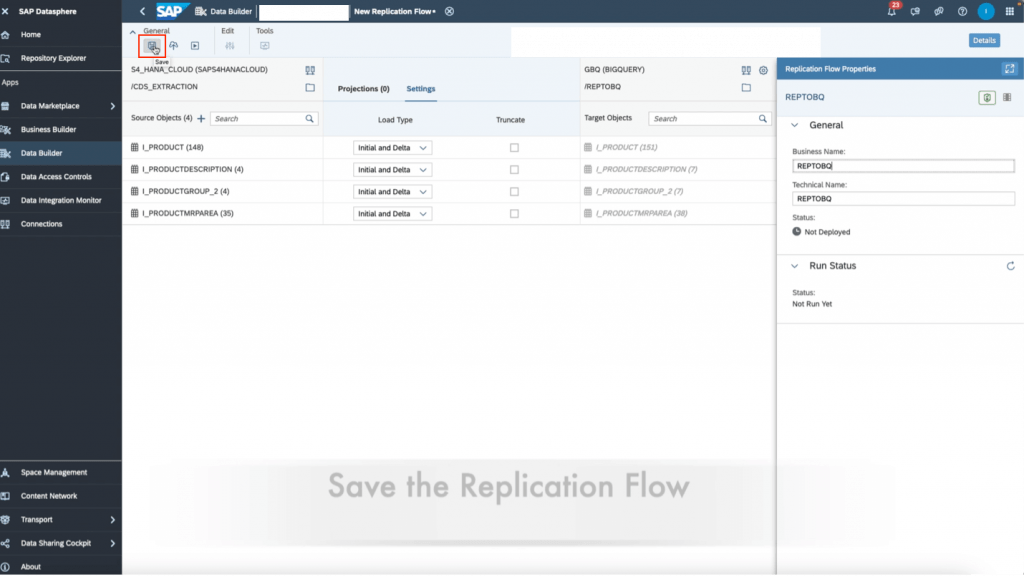
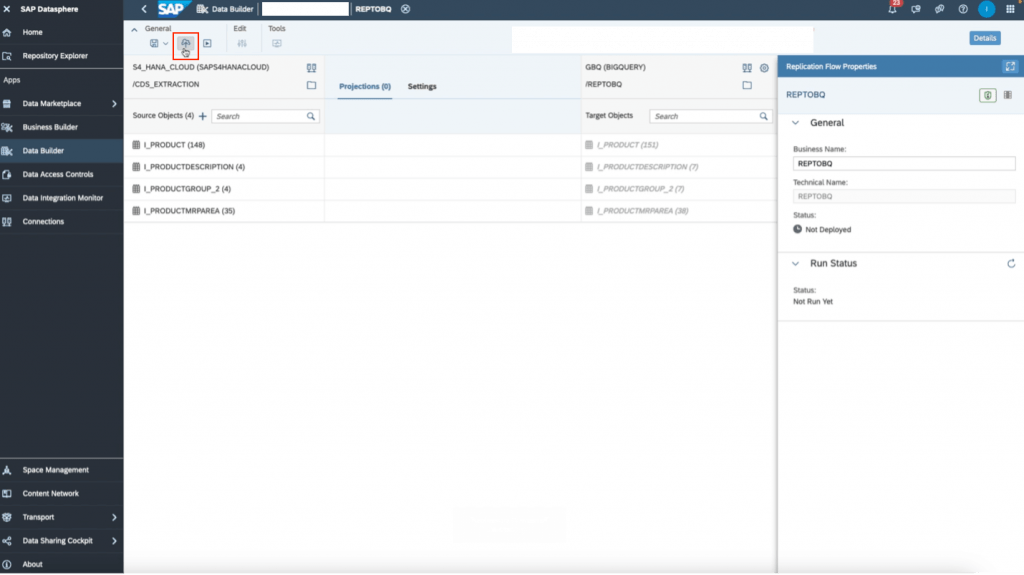
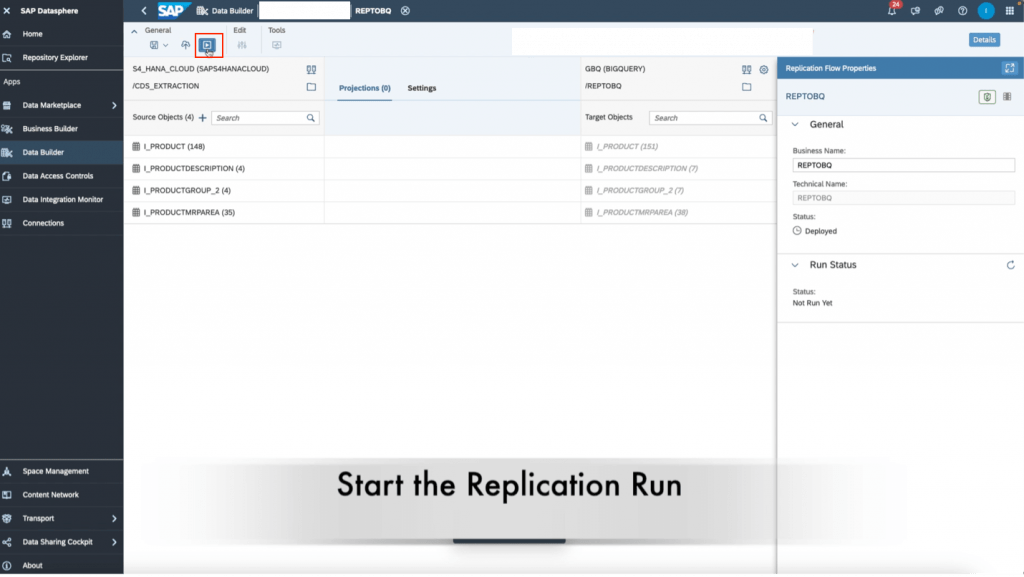
15. Finally, rename the replication flow to the name of your choosing in the right details panel. Then, save, deploy, run the replication flow through the top toolbar icons. You can monitor the run in the “data integration monitor” tab on the left panel in SAP Datasphere.
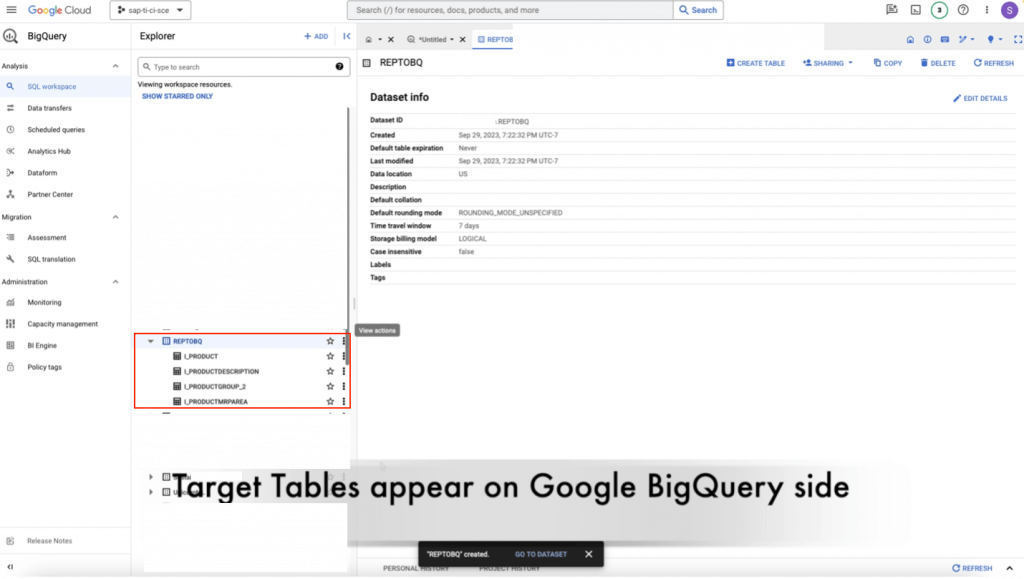
16. When the replication flow is done, you should see the target tables in BigQuery as such. It should be noted that every table will have 3 columns added from the replication flow to allow for delta capturing. These columns are operation_flag, recordstamp, and is_deleted.
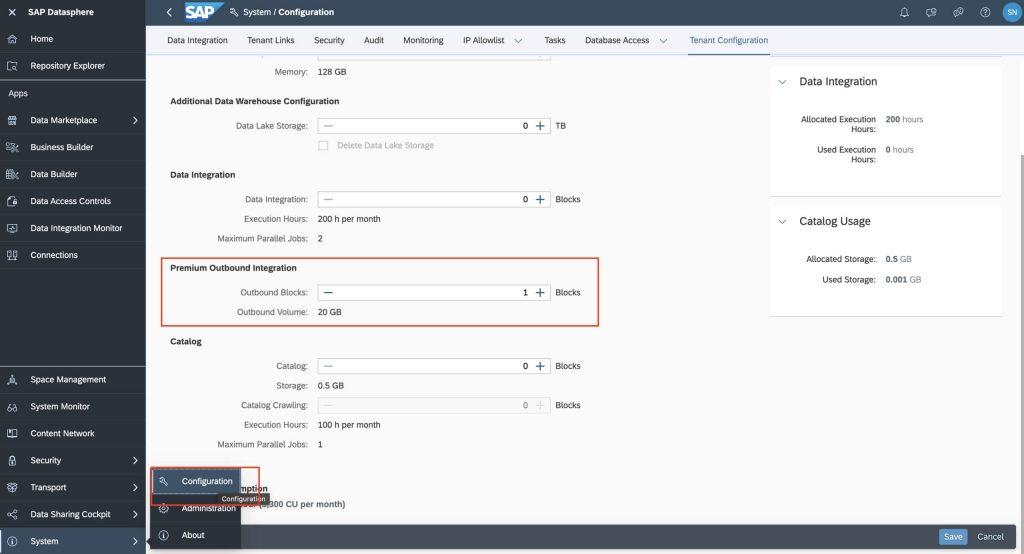
Note: You may have to include Premium Outbound Integration block in your tenant to deploy the replication flow.