Introduction
In SAP Datasphere we can “enhance” a data set using different development artifacts like data flow, transformation flow or SQL view (Query/Table Function). In this blog article, I’ll share my point of view and decision process for development artefact selection.
Datasphere Technical Limitations/Design Considerations
Let’s first cover the most important factor; persistent data tables performs better than views. (For the sake of clarity, persistent data is pre-computed data set derived from a query or a data flow and stored in a table.). So, if we face sql view performance problems, we should consider writing the results to a table.
1- The choice between “SQL View – SQL Query” and “SQL View – SQLScript (Table Function)” is done regarding 2 factors: The complexity of the requirement and the readability of the code. If a requirement can be coded using one select statement in a readable manner, “SQL View – SQL Query” should be the one.
2- In native Hana developments, graphical views’ execution plans are optimized automatically. So, theoretically graphical views should perform better than SQLScript views. I couldn’t find a noticeable difference myself…
3- Data Flow Limitation 1: The script operator doesn’t allow us to read other tables within the code. We can only use the data of the input of the operator.
4- Data Flow Limitation 2: The script operator (Python) has an unexpectedly poor performance. In my experience it’s 40-50 times slower than local Jupyter Notebooks and even slower than SQLScript/SQL view option.
5- Data Flow Limitation 3: Local tables with delta capture capability are currently unavailable as target of Data Flow. Also, surprisingly we can only read active data table of these table as source.
6- Data Flow Limitation 4: We cannot use views with a parameter as source.
7- Local Table Limitation; we cannot turn on or off delta capture capability of a local table.
8- Local Table Property: The delta capture fields (Change_Type, Change_Date) are updated automatically only if data is updated using excel upload or via Data Editor. For data flow or transformation flow updates, these fields should be updated within the data/transformation flow.
9- Even if script operator in data flow has poor performance, in case we are not concerned about long running data loads, we can use data flow for tasks which are much easier to do in python like NLP, Data cleaning, time series analysis and so on.
So, my “decision tree” for choosing one of these artifacts is as seen below. Bear in mind that the code that we write in the node 3 or 4 will be used in a data flow or a transformation flow as source. So, it’s not lost time…
Example Scenario
The idea of writing this blog article came to me with this question: “What should I use for a material master self-transformation?”. We wanted to flag materials in the material master data table (it’s a table with delta capture capabilities) which have not been moved within last 365 days to identify obsolete materials. For this example we’ll use 2 tables; Material Movement Data (IT_TR_MM_DOC_DEMO) and Material Master (IT_MD_MATERIAL_DEMO). So, here we are!
Steps/Explanations
1- You can find the material master data and material movements table data screenshots below. As it’s pretty straight forward, I’ll not walk through data loads. You can load csv files for testing following official documentation.
2- For our scenario, we’ll read the material movement data table for each material in material master and change the valıe of material master “Obsolete” field to ‘X’ if there’s no entry for the material in question. According to screenshot above, materials 10000001 and 10000002 are not obsolete but 10000003 is.
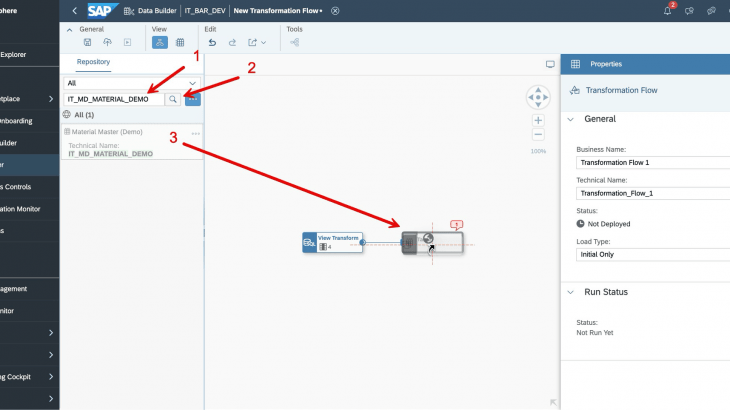
3- Go to Data Builder -> Select the space -> Click on “New Transformation Flow” -> Click on “View Transformation” and click on SQL View Transformation icon or the button.
4- Select “SQLScript (Table Function)”, copy-paste the code in the appendix.
5- Click on the Columns button and create the output table.
6- Validate the code using the button at the right top of the SQL View Editor, see that the SQL Code is valid and go back.
7- Search for the target table name, drag and drop it on the target box
8- Do the mapping of source and target fields by dragging and dropping them in the Properties Panel.
9- Click on an empty space of the canvas, rename the transformation flow, deploy it and wait for the deployment finished notification.
10- Run the transformation flow, refresh the run status until the status turns to “Completed”.
11- Go to data builder, open the target table, click on view data , filter the data for 3 materials we had in the material movements table and validate that none of the “Obsolete” values is null and 10000003 is marked as obsolete because latest movement was on 16.01.2022 which is more than 1 year before at the time of writing this article (22.04.2024).
Conclusion
In SAP DataSphere, creating a self-transformation is very easy using a transformation flow and pretty straight forward for BW/4HANA developers experienced in AMDP transformations (or anyone who codes SQLScript) but this method should only be considered for scenarios where we cannot achieve the desired result using a SQLView (Query or Table Function) due to complexity or performance reasons.