1. Introduction
I’ve had the opportunity of trying some test in a customer with a SAP BW/4HANA in order to improve performance in his reports. This customer has a modern infrastructure with a SAP BW/4HANA (BW 7.5, HDB 2.0) with an intensive reporting with AFO, webi and other third-party tools.
The reporting models have been built using mixed (or hybrid) scenarios following the LSA++ methodology. The different models are heterogeneous, some models are based mainly in HANA views (and using BW “only” for acquisition layer with a Composite Provider + query in top), and others models are using complex composite providers.
2. Business case
Using a copy of production environment, we want to try different actions that should require low effort in order to improve the performance reporting. These actions will be designed only from a technical point of view (no functional topics analyzed).
Our system has high amount of records (billions in some cases) and is loaded 4 times a day.
We compare performance before and after apply the actions.
3. Technical optimizations
There are some acknowledged best practices that are NOT subject to explanation in detail in this post.The goal of this post is explain the results obtained after applying these techniques in order to evaluate them.
3.1 ADSO partitioning (physical and logical partitions)
Our BW4 has a few ADSO much bigger than others, so is logic to start focusing in these ADSO. I have to admit that the results have surprised me by being quite different from what I expected: we have gained relevant improvement only in certain circumstances.
About partitioning… physical partition or logical partition?
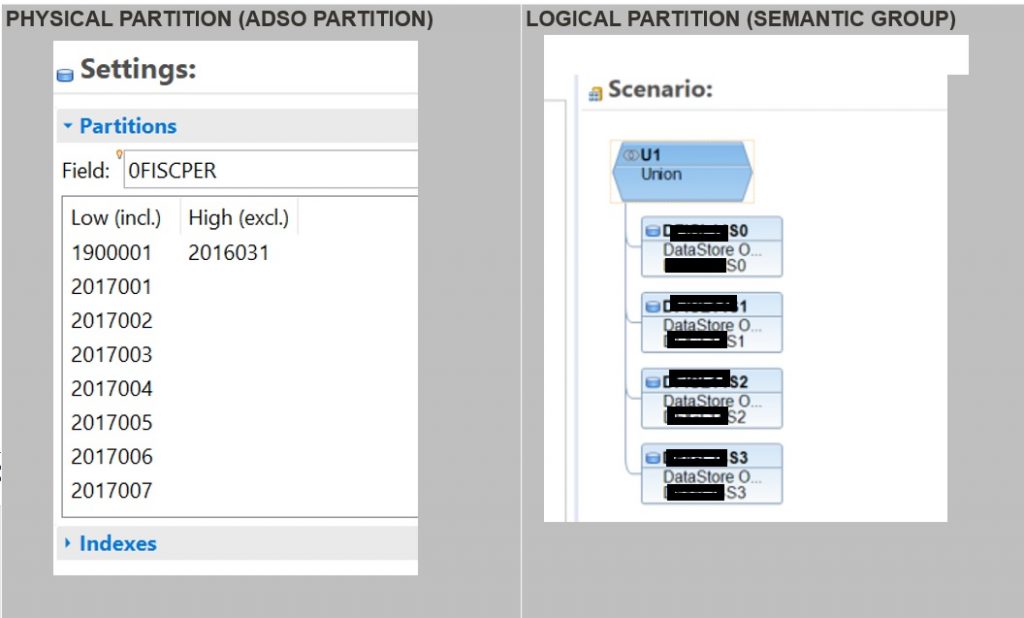
We have tested with physical and logical partition (with semantic group), with the following improvement in performance:
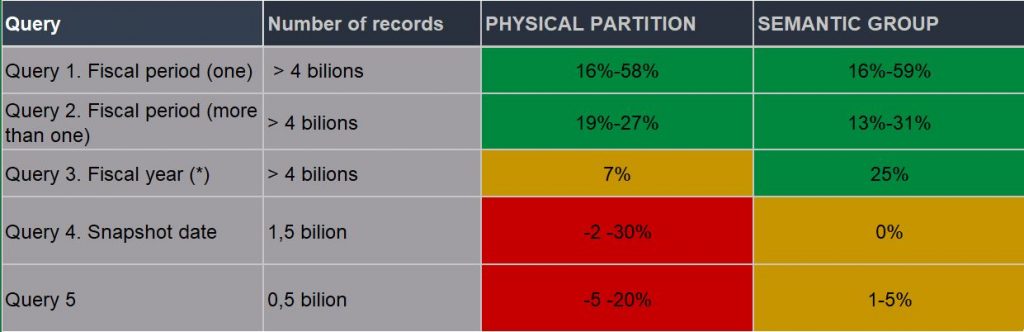
My conclusions here are:
- We have (obviously) different results in the same query depending on the selection and drill-down done.
- Partitioning only works when the ADSO has more than 2 billion of records.
- ADSO with less of two billion, physical partition can be harmful. Logical partition with semantic group is neutral (but can be interesting to implement it for other reasons, not only for performance reasons).
(*) Obviously, if we are partitioning by fiscal period and our query is asking for fiscal year, we have to change this (there are some ways to do this).
!: Important: the models tested have a few ADSO much bigger than others, but these models are complex too, this is, the models don’t have only a big adso, but also several joins and others ADSO involved. Is for this that the gain with the partitioning has been modest in some cases.
For the same reason, removing historical data from these ADSO didn’t have relevant improvement: We removed 20% of historical data in these ADSO and we only obtained 2-5% of gain in performance.
A different case was a model that was relatively simple, with few joins and only one relevant ADSO with 1 billion of records. We detected that this ADSO was partitioned by fiscal year, however the queries were using fiscal period. After changing the partitioning criteria, the gain was 8%-35%, depending on the values selected in the query.
Finally, comment that we had some problems with the “remodelation process” of these big ADSO. We finally decided to do first a copy of them, drop the data in the ADSO, to do the partition and reload from the copy.
3.2 Add input-parameters in HANA views
I’ts recommended by SAP that data must be filtered as early as possible using input parameters. This means for example that if you have a projection reading an ADSO, you should have an input parameter in this projection (or/and a filter if possible).
Some of the models had the filters (variables) in the BW-query in the top. Changing the model by adding a input parameter instead a query-filter, we had about 5-20% of improvement, depending on the model and the data requested.
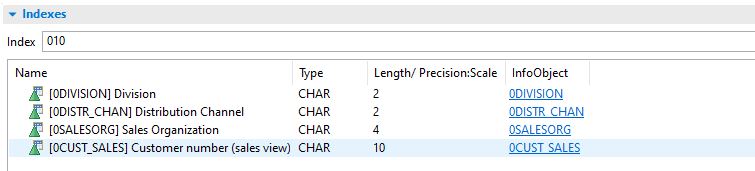
3.3 Join on Key columns and indexed columns
Sometimes, we think that the primary keys and indexes are not relevant in HANA environments. However, SAP recommends that all relevant joins should be done using the key columns or indexed columns.
We checked all the mains joins and we added indexes where needed. I have to admit that the results were not good. In most cases the gain wasn’t relevant or even a little bit worst.
Only in one case, where some fields were used in several joins in a view, we gained about 17% of performance. This join was at customer level in an ADSO with 700 millions of records.
Thought this action in most of times won’t have positive results, I recommend to check this, is easy to test.
3.4 “Optimize joins columns” flag
Really I don’t understand completely how this flag works. However, we detected that in one HANA view, where the performance was bad, the problem was concentrated only in one join, and this join apparently was not more complex that the rest. After activate this flag, we gained about 50% in performance.
3.5 Replace composite unions by HANA unions in top
By experience in other projects, I can affirm that if you have a composite provider with unions, is good idea to replace this BW-unions by HANA-unions. Yes, I know, you’re thinking that it doesn’t make sense. But this is my experience, and the gain is relevant.
In this customer, only one model was in this situation, and the change wasn’t relevant, I think because depending on the selection in the query, not all the ADSO was being reading at the same time. however, I recommend this action.
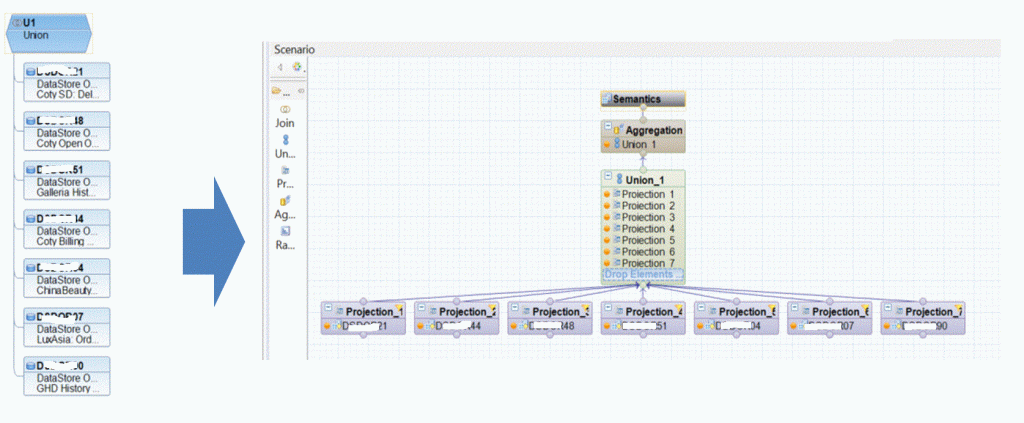
3.6 Navigational attributes
In parallel to my tests, some colleagues in a project discovered an interesting thing… one of the models had a composite provider in the top where some attributes had a lot of navigational attributes:
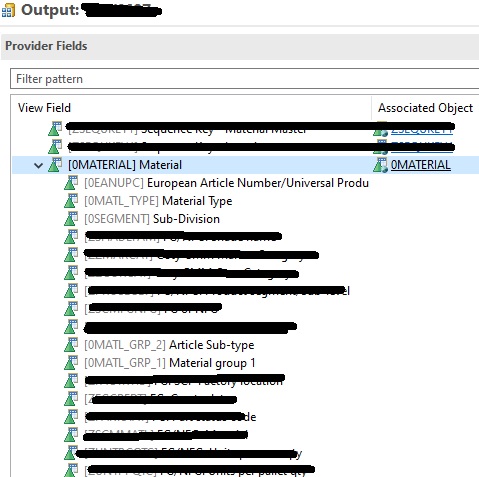
They decided add a new composite provider above the “old” composite provider, reading it and “remapping” the navigational attributes on their own infoobject:
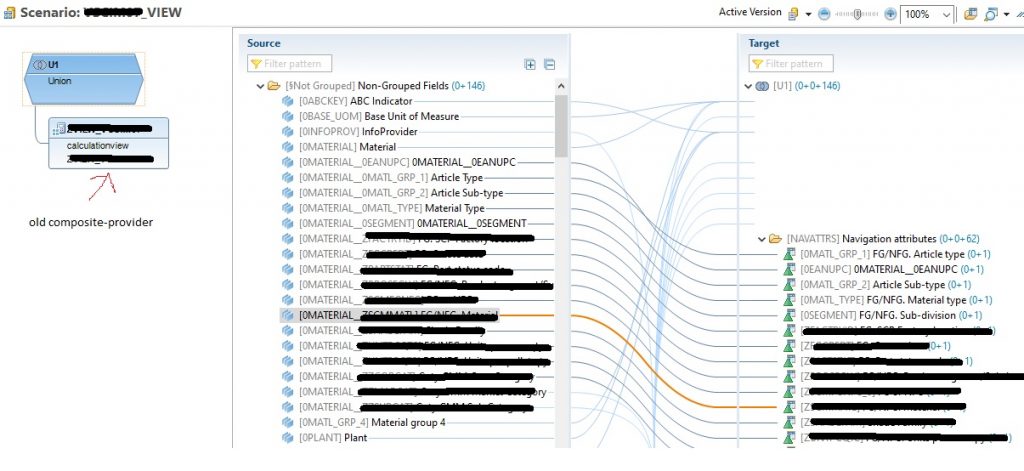
In this way, depending on the number of navigational attributes used in the query, the improvement was about 25%-45%.
3.7 Materialize the joins
Obviously, you don’t need to read this blog to know that if your remove a join and you add the fields required in the load of your ADSO (or creating a new ADSO in the EDW layer), the query performance will we better.
This is NOT, in general, a good best practice and good approach in BW4/HANA. We must analyze carefully this situation, but sometimes it can be highly recommended, specially when the compression rate by creating a new ADSO is high.
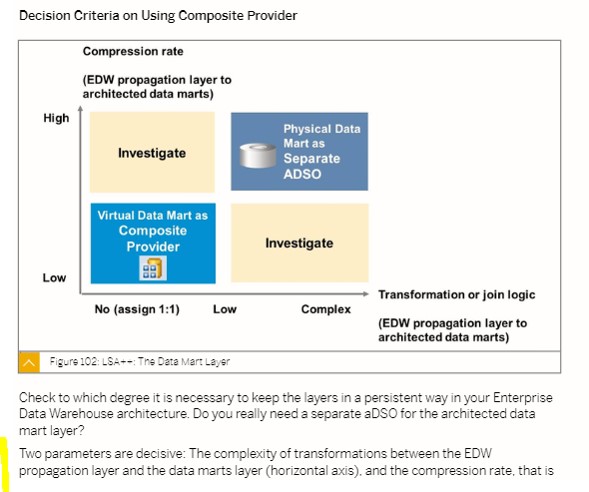
After some test, we concluded that in one area, where the EDW layer has billions of rows with a high granularity, this approach must be considered in future projects.
3.8 Left joins vs Inner joins
SAP recommends whenever possible, make inner joins instead of left joins. Personally, I’m not very sure about this, and probably depends on the model.
In the particular case of this customer, we changed some left join by inner joins, without relevant improvements.









