NSE Whitepaper
What is NSE ?
HANA SPS 04 version has introduced the NSE. NSE is used to store the warm data. HANA was used to store the hot data in memory but as data growth occurred in some of the organization the need for another store came into picture and SAP came out with a solution to introduce the another store called as warm store which in turn called as NSE.
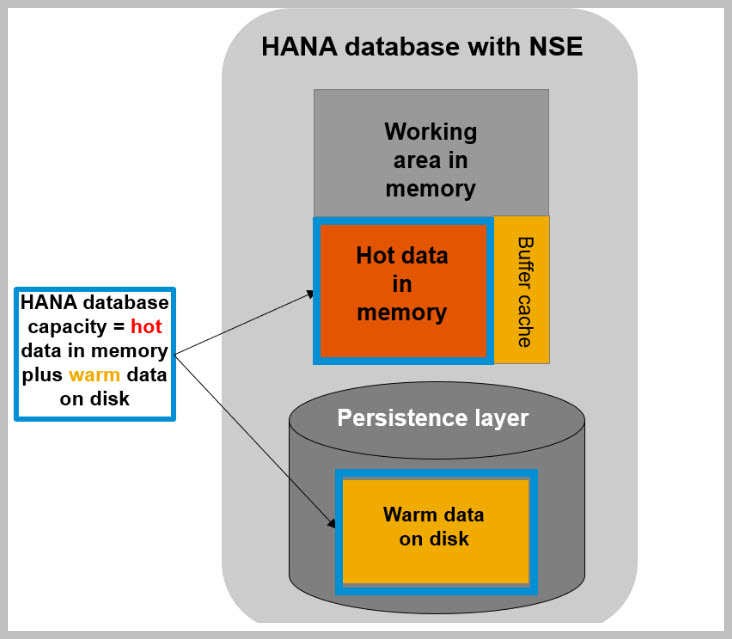
Please refer the below block diagram by SAP :

Customers implementing the SAP NSE solution:
Customers who are planning to think about implementing the NSE should closely monitor the data growth. They need to compare the total memory size vs the used size.
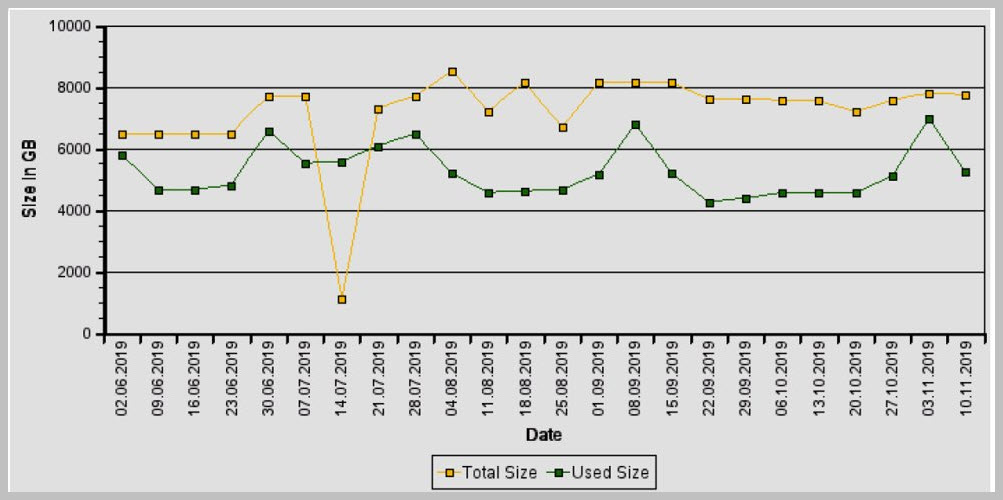
In our system we found the database growth of 61.91% per year so we moved towards implementing the NSE.
In-Memory/Hybrid/On-Disk – NSE has the feature to store the data in disk-based column store and Hana has the feature to store the data in in-Memory column store.So it has a hybrid column store approach.
NSE integration is based on the Hana Persistence layer in close connection to Page Access and Resource Manager.
Buffer Cache (BC) is required for performance access to pages on disk.The buffer cache should avoid redundant I/O operations by keeping pages which are access frequently in memory rather than reading them from the disk repeatedly.The Buffer Cache uses LRU (Last Recently Used) and HBL (Hot Buffer List) strategies and reuses the pages from the internal pools instead of allocating/deallocating pages via HANA memory management.
NSE Advisor:
With the help of the NSE Advisor the objects (tables, partitions or columns) that are suitable to be converted to page loadable (to save the memory space) or to column loadable (to improve the performance) can be identified within the recommendations result view.
NSE Functional Restriction:2
Consider the following when storing large data sets in NSE on servers with limited memory capacity
• HANA as an in-memory database executes queries with allocating transient data and interim results in memory. Queries do not page interim results or parts of interim results from memory to disk.
• HANA keeps NSE data in memory in a buffer cache. Low hit rates in the buffer cache can cause insufficient query performance due to high number of disk reads.
• SAP provides general guidelines about the buffer cache sizing in the SAP HANA Administration Guide for SAP HANA Platform. Deviations from the guidelines require application based sizing or proof of concepts with workload simulations.
• Users can store warm data in NSE instead of on Dynamic Tiering. In contrast to Dynamic Tiering, the query execution in the HANA service, storing the NSE data, creates transient data and interim result in memory only. Thus, the memory requirement for a comparable workload can be higher with NSE. A solution to migrate data from Dynamic Tiering to NSE in on the road map for SAP HANA.
• SAP HANA NSE is for scale-up systems. For scale-out systems, SAP HANA does not check if users create tables with page-loadable columns or convert tables to page-loadable.
• SAP HANA NSE supports partition load units for heterogeneous partitions but does not support partition load unit for non-heterogeneous partitions.
• Specifying partition-level load unit is supported for the following partitioning schemes:
-Unbalanced range
-Unbalanced range-range
For all other partitioning schemes used in SAP NSE tables, load units can be specified only on column, table, and index.
NSE Advisor Usage:
- Identify representative workload of your system
- Optionally configure the NSE Advisor
- Enable the NSE Advisor
- Run the representative workload
a. Monitor the performance of statements
b. Monitor the memory usage
c. Monitor the duration of processes - Disable the NSE Advisor
- Evaluate and save the recommendations of the NSE Advisor
- Migrate the objects selected from the recommendations
- Run the representative workload
a. Monitor performance of statements
b. Monitor the memory usage
c. Monitor the duration of processes - Iterate your tests, e.g. restart from step 2, until you have a proven set-up, which fits your requirements.
Configure NSE Advisor :
ALTER SYSTEM ALTER CONFIGURATION ( ‘indexserver.ini’ , ‘SYSTEM’ ) SET ( ‘cs_nse_advisor’, ‘min_object_size’ ) = ‘XXX’ WITH RECONFIGURE ; —
default value 1048576 = 1 MiBEnable NSE Advisor:
ALTER SYSTEM ALTER CONFIGURATION ( ‘indexserver.ini’ , ‘system’ ) SET ( ‘cs_access_statistics’,’collection_enabled’ ) = ‘true’ WITH RECONFIGURE;Disable NSE Advisor:
ALTER SYSTEM ALTER CONFIGURATION ( ‘indexserver.ini’ , ‘system’ ) SET ( ‘cs_access_statistics’,’collection_enabled’ ) = ‘false’ WITH RECONFIGURE;
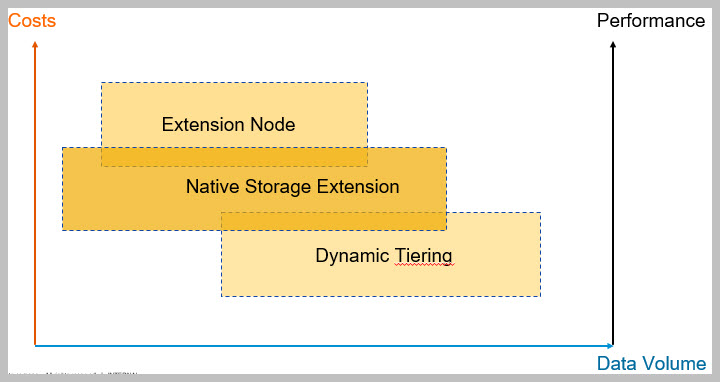
Evaluate and save the NSE advisor run.Hana Data Tiering Options are as follows:
- Hot Store
– Persistent Memory
- Warm Store
– Native Storage Extension , Extension Node, Dynamic Tiering
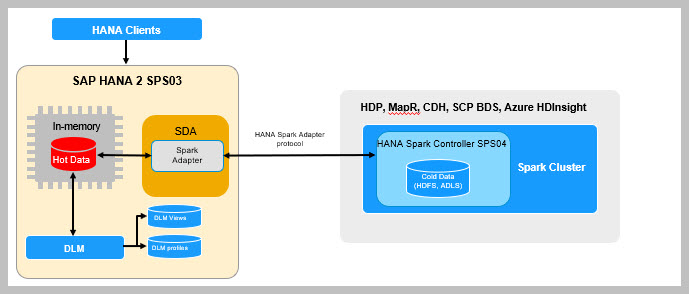
- Cold Store
– Spark Controller

NSE Value Proposition and Use Case:
- Value proposition:
- Increase HANA data capacity at low TCO
- Deeply integrated warm data tier, with full HANA functionality
- Will support all HANA data types and data models
- Simple system landscape
- Scalable with good performance
- Supported for both HANA on-premise and HANA-as-a-Service (HaaS)
- Available for any HANA application
- Complements, without replacing, other warm data tiering solutions (extension nodes, dynamic tiering)
- Use cases:
- Any customer built or SAP built HANA application that is challenged by growing data volumes
- S/4HANA data aging (NSE is an evolution of “paged attributes”)
- BW team currently uses extension nodes, but they communicated in TECH ED 2019 that NSE is certified for BW/4HANA
Specifying data as “page loadable”
- Data may be specified as “page loadable” at table level, partition level, and column level
- Data may be converted between “page loadable” and “column loadable”
- NSE supports range, range-range, and hash partitioned tables
- For hash partitioning the entire table or column must be page loadable or column loadable
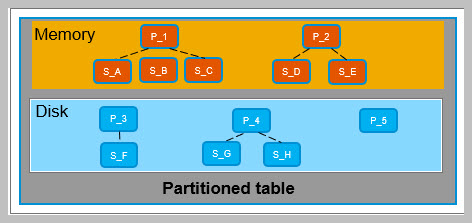
NSE Technical Overview:
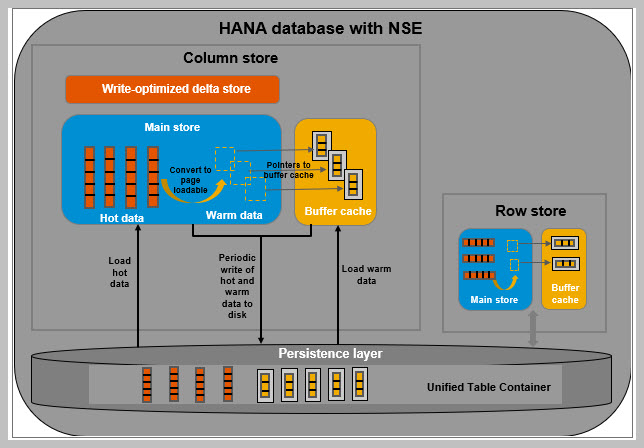
- The HANA column store and row store each have a buffer cache.
- Column loadable data is fully loaded into memory from disk.
- Page loadable data is loaded from disk into the buffer cache, page by page as needed.
- Converting column/row loadable data to page loadable format moves the data into the buffer cache.
- When buffer cache is full, it will eject pages intelligently based on user access patterns.
- Warm and hot data are written together from main store to disk during normal save point operations. The write-optimized store is not paged
Tooling:
HANA Cockpit:
- Configure buffer cache size (on-premise only; HaaS will configure this for the user)
- Configure tables, columns, and partitions as “page loadable”
- Monitor buffer cache usage and capacity
- Report on resident memory status for page loadable data
- Includes rule-based “recommendation engine” to monitor user data access patterns.
- Based on statistics, the engine will advise user on which tables, columns, or partitions would benefit from being converted to “page loadable”
Data Lifecycle Manager (DLM):
- DLM tool will allow user to convert tables, columns, and table partitions between “column loadable” and “page loadable”
Web IDE:
- Visualized query plan will display when warm data is accessed from NSE in order to satisfy the query
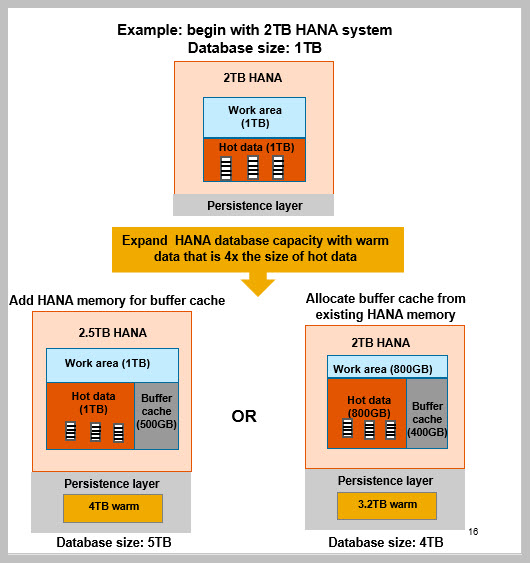
On-premise sizing
- HANA system must be scale up (first release)
- Determine volume of warm data to add to the HANA database
- May add as much warm storage as desired – up to 1:4 ratio of HANA hot data in memory to warm data on disk
- NSE disk store should be no larger than 10TB for first release of NSE
- Divide volume of warm data by 8 – this is size of memory buffer cache required to manage warm data on disk
- Either add more HANA memory for buffer cache, or use some of existing HANA memory for buffer cache (will reduce hot data volume)
- Work area should be same size as hot data in memory (equivalent to HANA with no NSE)
SAP HANA Extension Node – Whats New in SPS04
Common characteristics:
- HANA node in the scale-out landscape is reserved for warm-data storage and processing
- Supports all HANA operations and data management features
- Allows larger data footprint of up to 200% of the node DRAM size
- HANA persistent memory is supported
New Features:
- Benefits from new partitioning and scale-out features in SPS04:
–range-hash partitioning scheme
–“pinning” tables on fixed HANA nodes
–partition grouping
Warm Store Options – Getting Started
Cold Store:
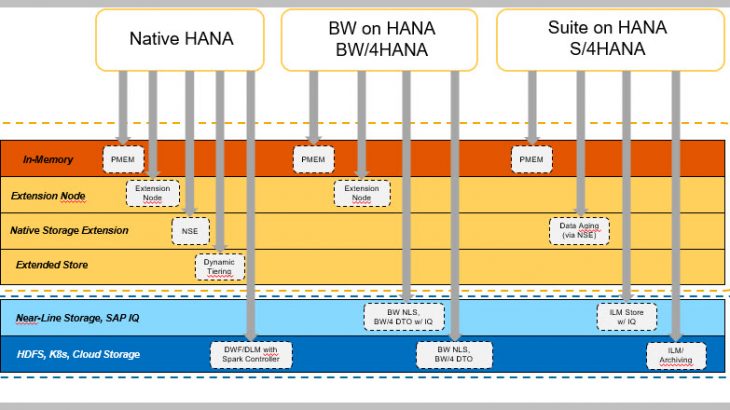
Which Data Tier Should I Use ?
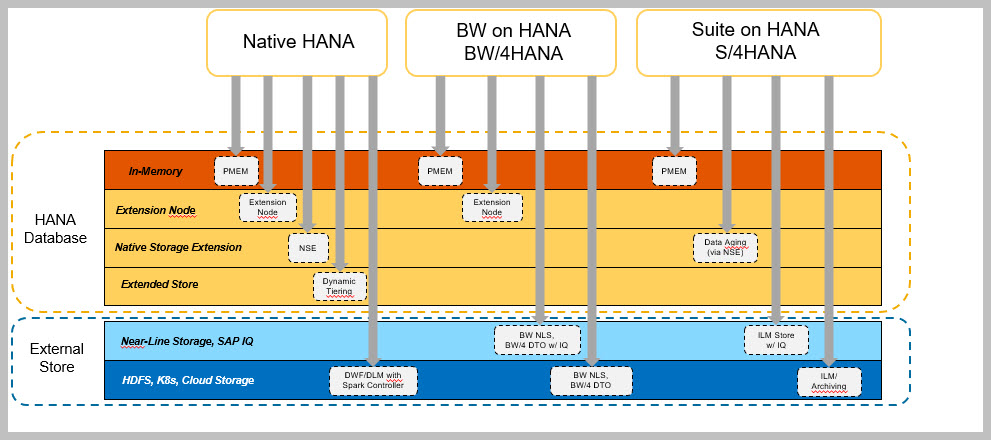
I tried to explain the best way of handling the NSE and also show case how to Select the NSE for each customers.In my next article I will try to articulate all the technical changes required for the NSE and also introduce the data aging concepts which is key to NSE.









