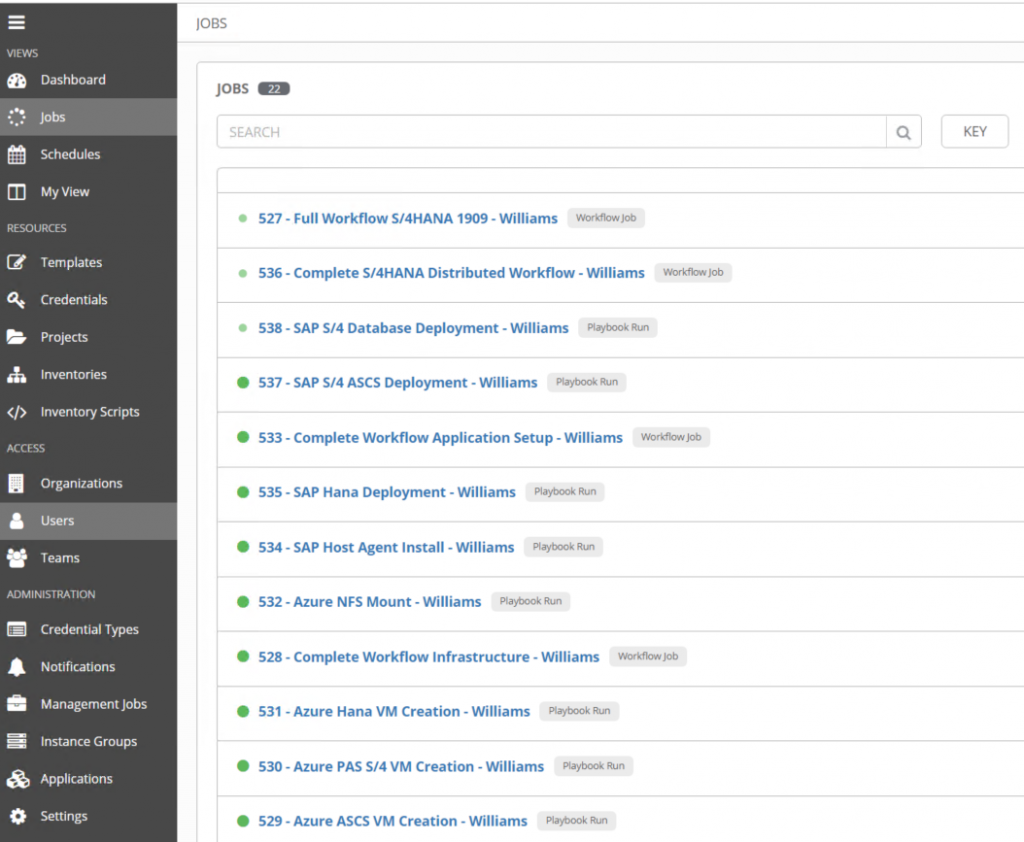
The IaC methodology is nowadays the way to go to accelerate the infrastructure deployment to cloud or on-premise, and have a repeatable and sustainable process. But what about the application portion when it comes to SAP workload on Azure?
In this article, I will explain and walk you through on how you can automate the full deployment of your SAP application such as S/4HANA, in a distributed environment with Ansible Tower products from RedHat on Azure.
Again, and as always, before you start any action and to guaranty the success of the exercise, it is important to do some reading on our subject. Here is a collection of guides, references, and SAP Notes to be reviewed. These references differ from the previous article, so take the time to review them:
SAP Notes
- 2871484 – SAP supported variants of Red Hat Enterprise Linux
- 2526952 – Red Hat Enterprise Linux for SAP Solutions
- 1631106 – Red Hat Enterprise Linux for SAP Applications
- 2769531 – SAP S/4HANA 1909: Release Information Note
- 2844322 – SAP HANA Platform 2.0 SPS 05 Release Note
- 1928533 – SAP Applications on Azure: Supported Products and Azure VM types
Guides
- SAP HANA Server Installation and Update Guide 2.0 SP5
- SAP NetWeaver 7.5 and ABAP Platform (Guide Finder)
Knowledge Base
- Overview of the Red Hat Enterprise Linux for SAP Solutions subscription
- Red Hat Enterprise Linux System Roles for SAP
So why this article? Here I will cover additional aspects of the deployment process in regard to the infrastructure, such as Azure specifics, but also the nature of the SAP deployment with the fact that it will be in a distributed environment.
Before we run the tool
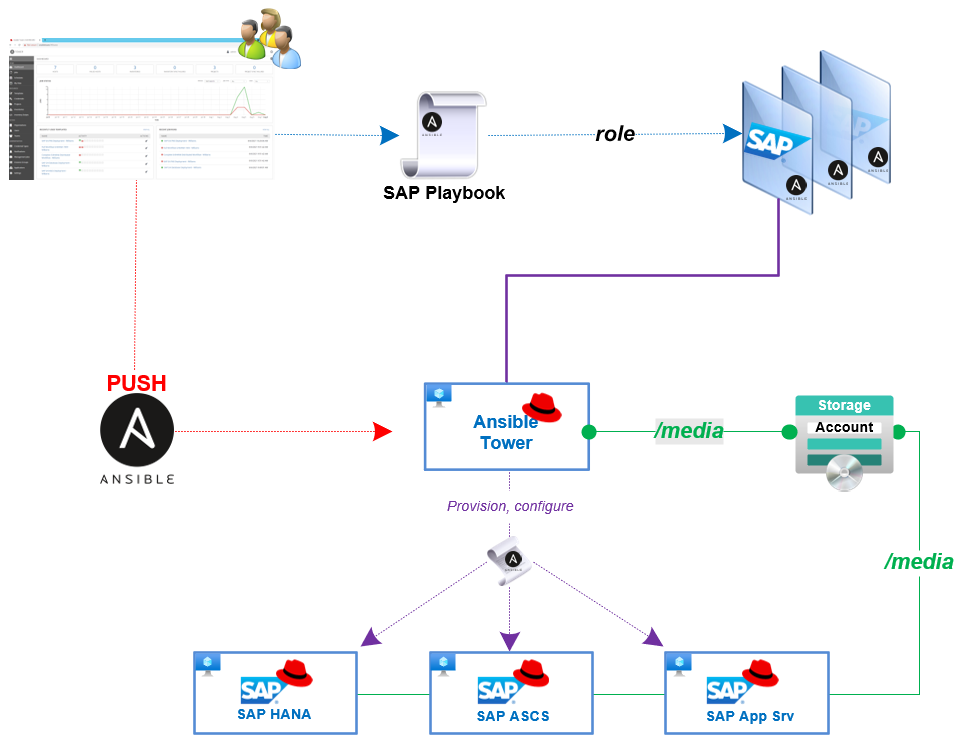
Well, in this article I will not cover the installation of Ansible Tower obviously, but because my deployment is happening on Azure cloud some preparation needs to be taken care of. The first thing to know, Ansible like many other IaC tools, use modules and libraries to interact with cloud providers or any other platform. Therefore, once your Tower is installed you will need to load them in Azure.
Once Tower is installed run the command “ansible –version” to check your ansible and python versions.
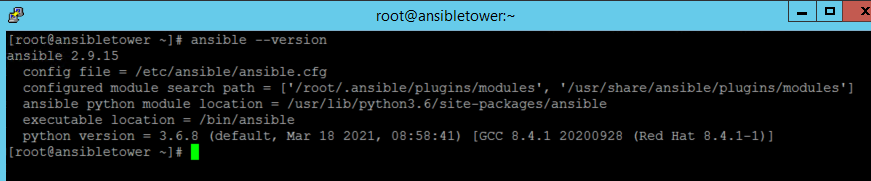
Since Ansible Tower installs Ansible 2.9.15 core, run the command at the OS level “pip3 install ansible[azure]” to load the necessary module from Azure.
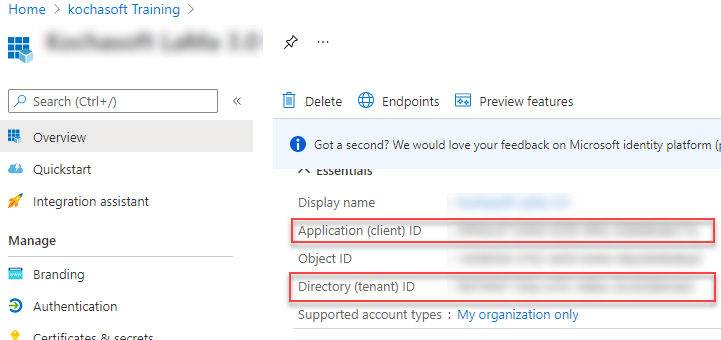
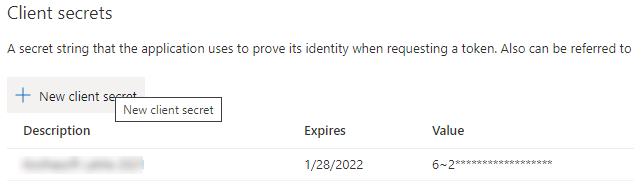
Ok, it’s the first step for the Azure preparation part, now we need to interact with Azure to run actions. To do so you will need to create a service principal user form Azure AD, capture the Application ID, Tenant ID, and Client secret password.
Once done, also capture the subscription ID where it needs to apply.
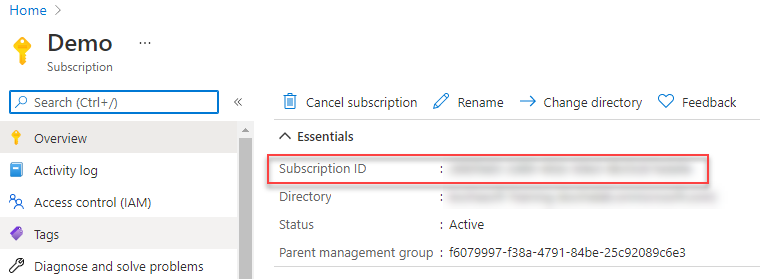
Now it’s time to get in Ansible Tower, finally ? and provide the necessary information to be able to interact with Azure. Once logged in, go under credentials on the left panel and add the Azure credential.
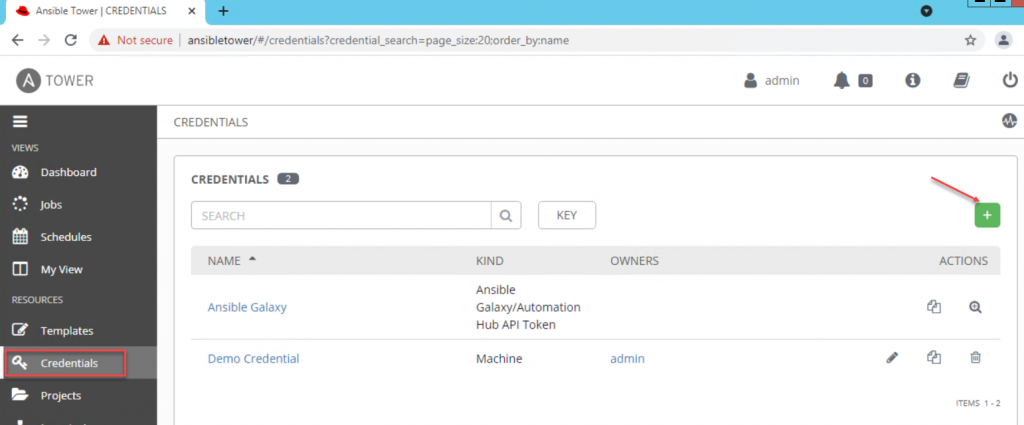
Under “Credential Type” select “Microsoft Azure Resource Manager” and provide all the captured information from previous steps and save.
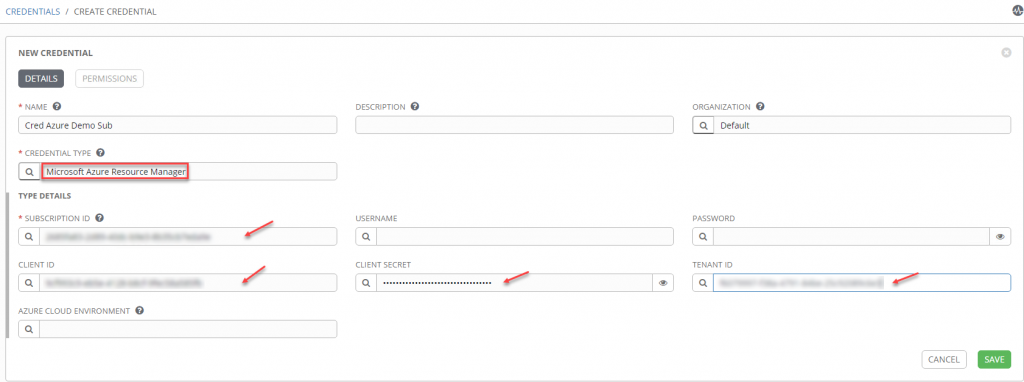
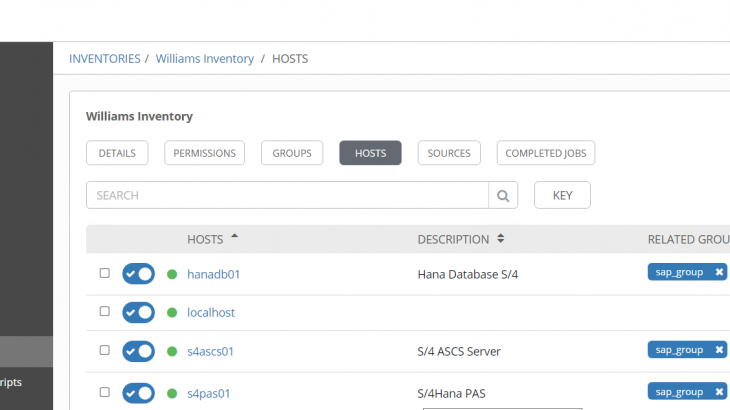
At this point we are ready to interact with Azure, but, yes as always … you must to set your inventories. Just a quick reminder, the inventory reflects all the servers and groups of servers where the action will be performed. You will notice my 3 servers hostname (hanadb01, s4ascs01 et s4pas01) used for my sap components to deploy (Hana, ASCS, PAS).
Ok, now let’s have a look at the procedure itself to deploy the infrastructure.
Run the procedure
From the articles by Marcos and Anastasiia (see part What and how to articulate it ? ), it’s covered how to set and run your playbook when your infrastructure is already in place, so what if this is not the case for you?
In my scenario, I’m creating 3 different playbooks, one for each SAP server component that will be used by Ansible to create the job template.
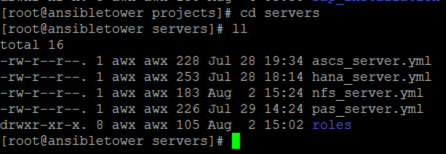
I will also create roles used by the playbooks in order to perform all the necessary actions.
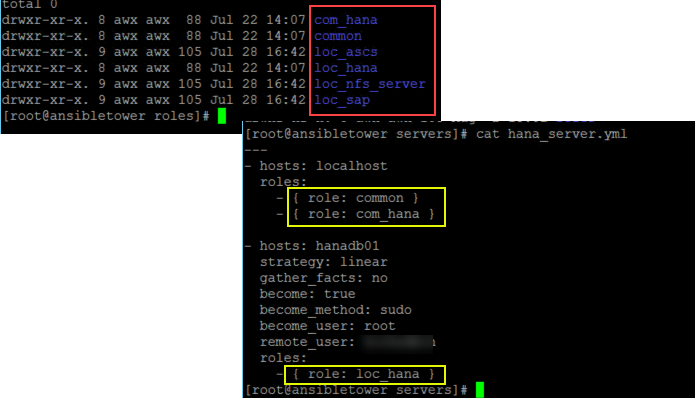
These roles create the infrastructure from nic, servers, storage, security group, and perform actions directly on the respective server or groups of servers such as setting up the disk, installing software, and more action according to your needs.
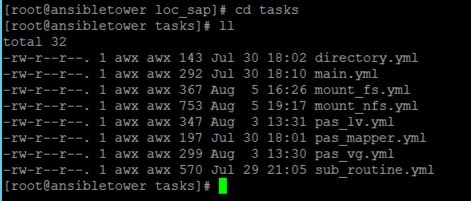
So, to summarize I have Tower installed, credentials to azure set, azure modules, project and inventory servers set … it’s a good start.
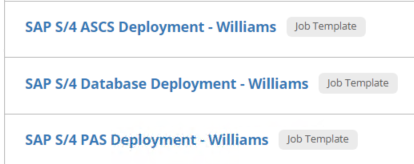
Ansible Tower uses 2 kinds of templates to run your playbook, Job Template (JT) and Workflow Template (WT) which contains multiple JT.
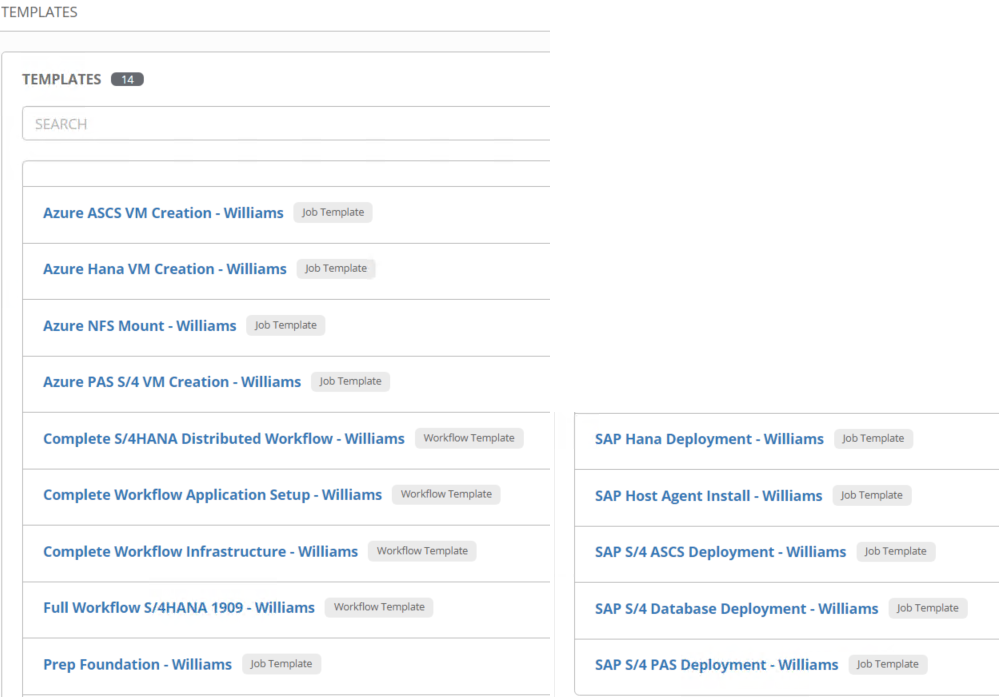
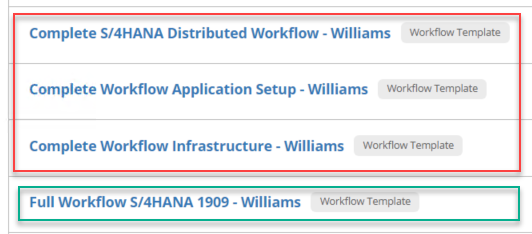
In my case, for better control and flexibility, I’m creating individual templates from infrastructure components to build (ASCS server, PAS server, Hana server)…
to the Installation of S/4 components that I encapsulate in workflows.

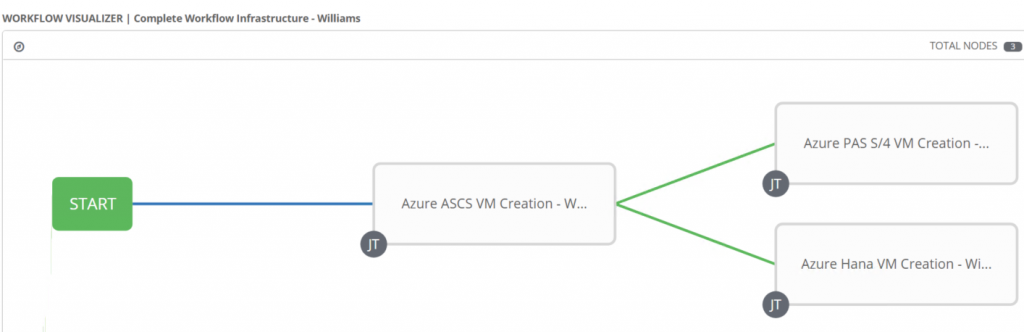
Here are the 3 main workflows, in the red square, which execute every milestone. The one in green square encapsulates all of them in chronological order.
The sequence looks like this on the workflow visualizer.

Now that the full workflow is created do you think that I’m ready to deploy it end-to-end? Not really and this is where you have to be precise. Remember I told you that I want to run a “distributed environment” from an SAP deployment perspective.
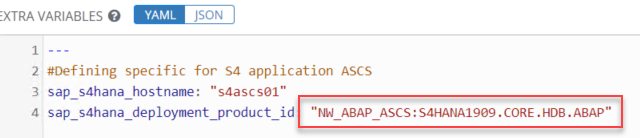
Here is what you need to take care of to realize it properly, since it’s not infra-related but the application you will need to focus on the S/4 Template at the extra variable level.
The key point is to declare the right product ID for each of the components in their respective template.
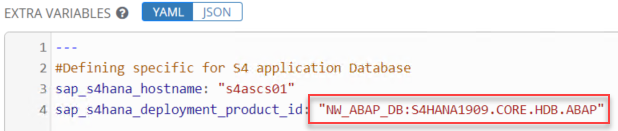

Some of you might wonder where to get them and how to know them. When you decompress the SWPM tool a file called “product.catalog” is extracted.
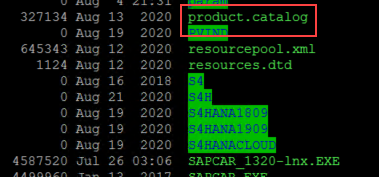
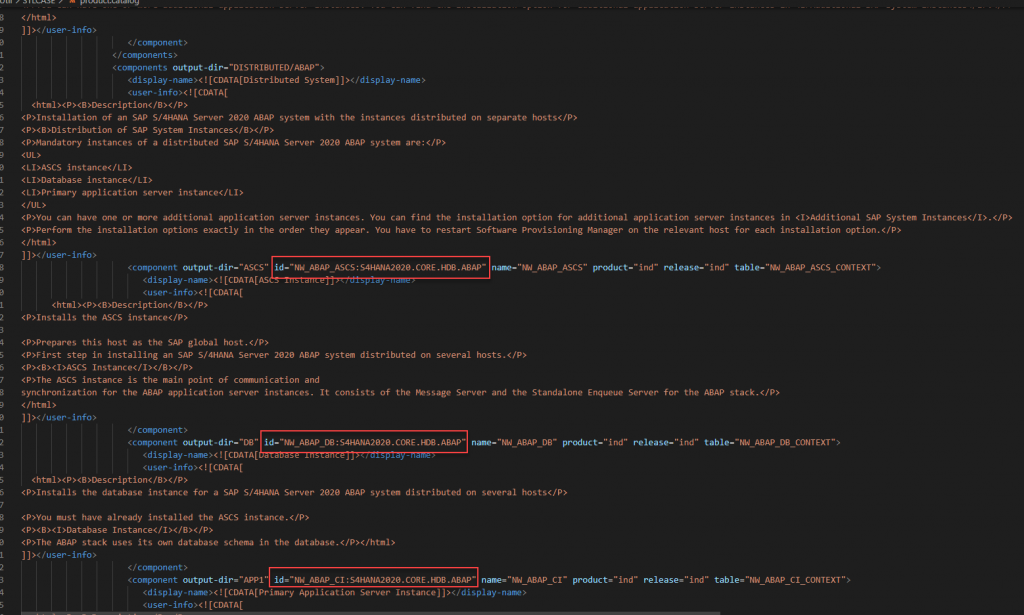
Open the file with your preferred editor and search for the product ID related to the software component you want to install.
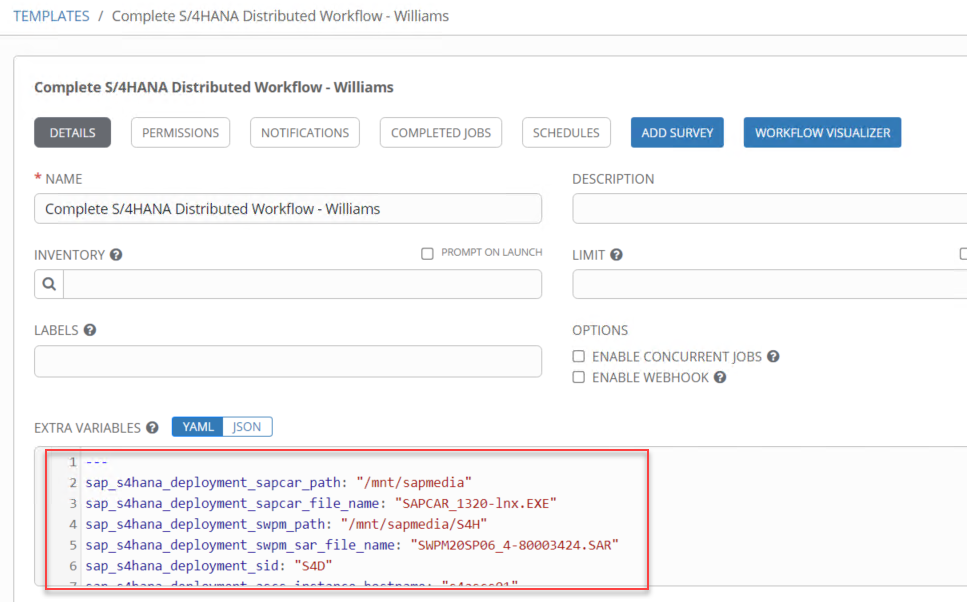
While we are on the variables field, if you look closely, I don’t have many variables defined in my individual template. It is on purpose because I define my common variables at the workflow template level in the “Extra Variables” field. In other words, variables set at the WT will apply to all templates encapsulated in it.
Hang on, we are almost done, you still need to apply so minor updates before you run your workflow. If you have followed the procedure (no doubt you did) to download the SAP role, you should have the 2 following folders.
This folder contains a subfolder called “templates” where it contains a configfile.j2.
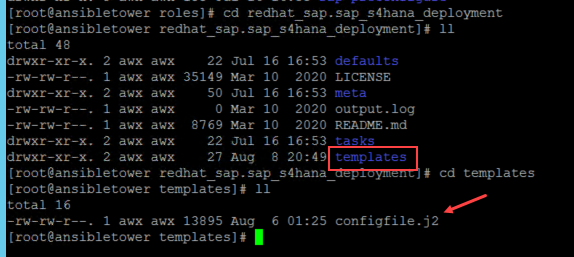
Basically, this is where you can customize your deployment because we are in a distributed setup from the S/4 application side. Open the file and add the following lines.

Few notes here, these parameters need to be added because SPWM requested in dialog mode, the schema name can be customized:
HDB_Schema_Check_Dialogs.schemaName = SAPHANADB
storageBasedCopy.hdb.instanceNumber = {{ sap_s4hana_deployment_hana_instance_nr }}
storageBasedCopy.hdb.systemPassword = {{ sap_s4hana_deployment_hana_systemdb_password }}This parameter was needed to be increased from 6 to 15 in my case because job failure occurred during the PAS installation while running the RSWBOINS report:
NW_WPConfiguration.ciBtcWPNumber = 15
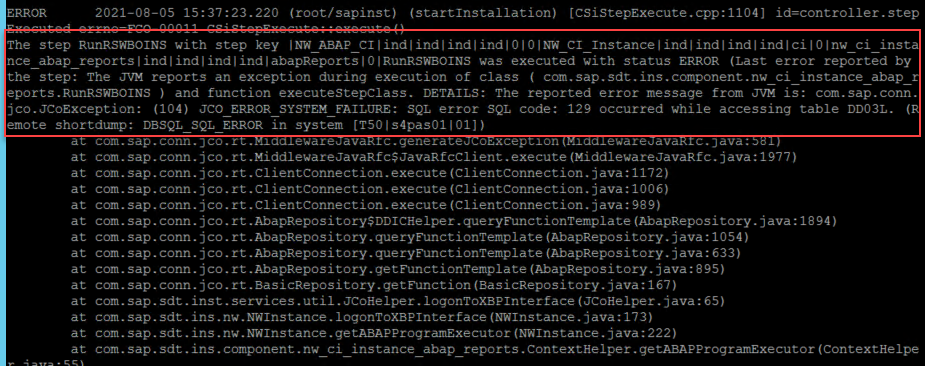
Now the full workflow can be executed, in my case, the full deployment from infrastructure to applications took approximately 1h 45min.