Introduction
With SAP Data Intelligence release 2110 a new set of operators have been introduced: The generation 2 operators. It is more a leap than a next step that includes not only new features but the fundamental design has also changed. This is a first release of these new type of operators therefore not all properties of the generation 1 operators have their counterpart in this next generation operators and not all operators are yet available. The next releases will close the gap.
The new features covered in this blog
- Strict data type definitions -> increased code quality
- Changes of creating new operators
- Streaming support of operators
- Pipeline resilience – Saving and retrieving operator states
- Cross-engine data exchange -> far more flexibility, e.g. Custom Python operators connects with Structured Data Operators
For a while the generation 1 and generation 2 operators will co-exists but you cannot mix them into one pipeline. When creating a pipeline you have to choose.
Strict Data Types
When making a custom operator you first start with defining the data types that the operator should receive and send. In addition you also define the header data type. A header type is not necessary but should be good practise. There is a way to define data types at runtime or infer data types, but again this should be rather the exception.
There are 3 types of data types:
- Scalars – basic data types – e.g. integer, float, string,…
- Structures – 1 dimensional list of Scalars – e.g. com.sap.error [code:int,operatorID:string, …] or embedded Tables (e.g. com.sap.error)
- Tables – 2 dimensional list of Scalars
Hierarchical structures that you can build with dictionaries/json are not supported. We have to keep in mind that these data types should be used by all operators independent of the code language/service/engine. For the time being these kind of structures needs to be flattened.

Due to my project of testing the new Data Intelligence Monitoring PromQL API I am going to use a big data generation custom Python operator that sends periodically generated data with
- id – com.sap.core.int64
- timestamp – com.sap.core.timestamp
- string_value – com.sap.core.string
- float_value – com.sap.core.float64
Whereas the basic data types integer, float and string are common across most languages, timestamp for example has different implementations. This means you might have to cast specific types first before you use them in a vtype-data structures. We have yet voted against an automatic casting due to performance reasons.
The following table tells you how the vtype-scalars are implemented:
| Type template | vflow base type | Value restrictions and format |
| bool | byte (P6) bool (P7) | enum [0, 1] (P6) enum [false, true] (P7) |
| uint8 | byte (P6) uint64 (P7) | range [0; 2^8-1] |
| int8 | int64 | range [-2^7; 2^7-1] |
| int16 | int64 | range [-2^15; 2^15-1] |
| int32 | int64 | range [-2^31; 2^31-1] |
| int64 | int64 | range [-2^63; 2^63-1] |
| uint64 | uint64 | range [0; 2^64-1] |
| float32 | float64 | IEEE-754 32bit single-precision floating-point number. In order to not introduce an additional vflow base type, the value is stored in base type float64. approx. range [-3.4E38; 3.4E38] |
| float64 | float64 | IEEE-754 64bit double-precision floating-point number. approx. range [-1.7E308; 1.7E308] |
| decimal | string | Regex ^[-+]?[0-9]*\.?[0-9]+$ Derived type must specify precision and scale. |
| decfloat16 | string | IEEE-754 64bit decimal floating-point number (decimal64) encoded as string. Regex ^[-+]?[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?$ approx. range [-9.9E384; 9.9E384] |
| decfloat34 | string | IEEE-754 128bit decimal floating-point number (decimal128) encoded as string. Regex ^[-+]?[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?$ approx. range [-9.9E6144; 9.9E6144] |
| date | string | ISO format YYYY-MM-DD Range: 0001-01-01 to 9999-12-31. |
| time | string | ISO format hh:mm:ss.fffffffff Up to 9 fractional seconds (1ns precision). Values without fractional seconds or less than 9 fractional seconds are allowed, e.g. 23:59:59 or 23:59:59.12. Range [00:00:00.000 to 23:59:59.999999999] |
| timestamp | string | ISO format YYYY-MM-DDThh:mm:ss.fffffffff Up to 9 fractional seconds (1ns precision). Values without fractional seconds or less than 9 fractional seconds are allowed, e.g. 2019-01-01T23:59:59 or 2010-01-01T23:59:59.123456. range [0001-01-01T00:00:00.000000000 to 9999-12-31T23:59:59.999999999] |
| string | string | String encoding is UTF-8 Derived type can specify length property. The length property specifies the number of Unicode characters. |
| binary | blob | Derived type can specify length property. The length property specifies the number of bytes. |
| geometry | blob | geometry data in WKB (well-known binary) format |
| geometryewkb | blob | geometry data in EWKB (extended well-known binary) format |
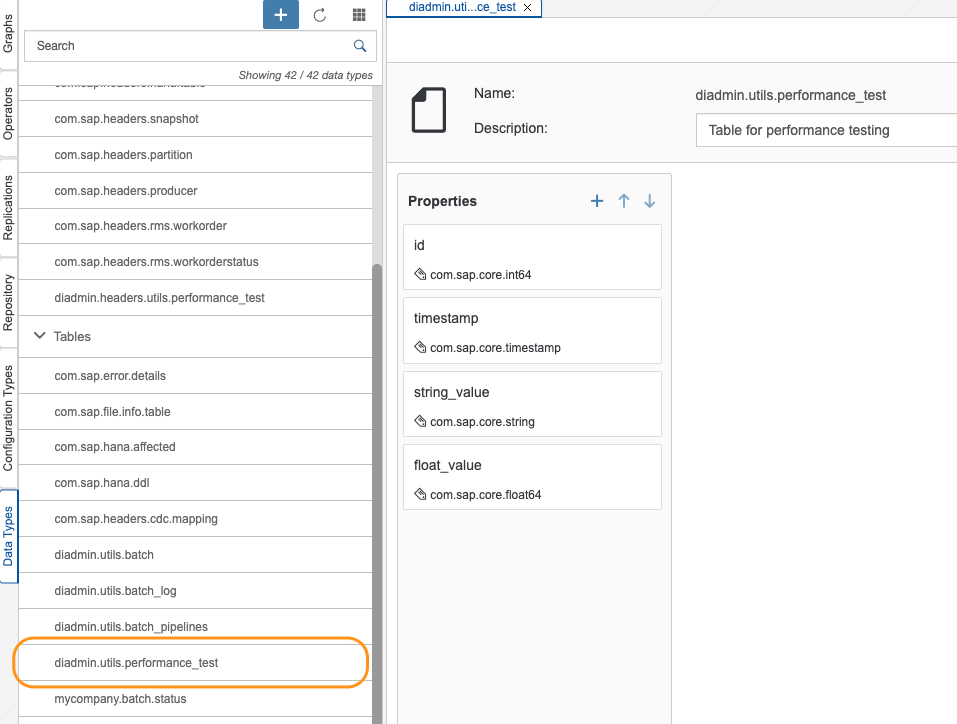
As a header data structure only Structures can be used. For my data generator operator I like to store the configuration parameter and the number of data that had already been generated:
Create Generation 2 Operator
The framework of generation 2 operators are quite similar to the generation 1 operators with a few exceptions.
Still the same:
- Operator creation wizzard is still the same
- The creation framework is still the same
- ports
- tags
- configuration
- script
- documentation
- ports
- Script framework
- function calls hooked to port(s) with a callback function
- api.config access
- data sending functions
- function calls hooked to port(s) with a callback function
Differences in addition to function name change:
- messages have ids
- response can be send to previous operator (not covered in this blog)
- with api.OperatorException hook into the standard operator exception flow
- batch and stream data supporting functions (not covered in this blog)
- additional functions to save and load operator state (resilience)
- No generator function “api.add_generator”, yet only “api.add_timer” or “api.set_prestart”
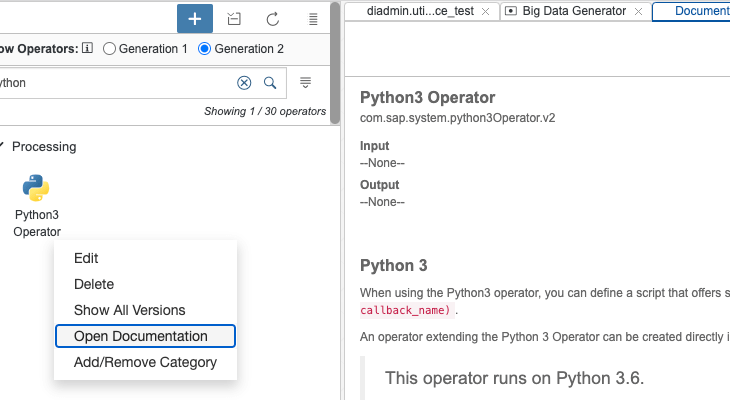
Some additional information you find in the documentation of the generation 2 Python Operator.
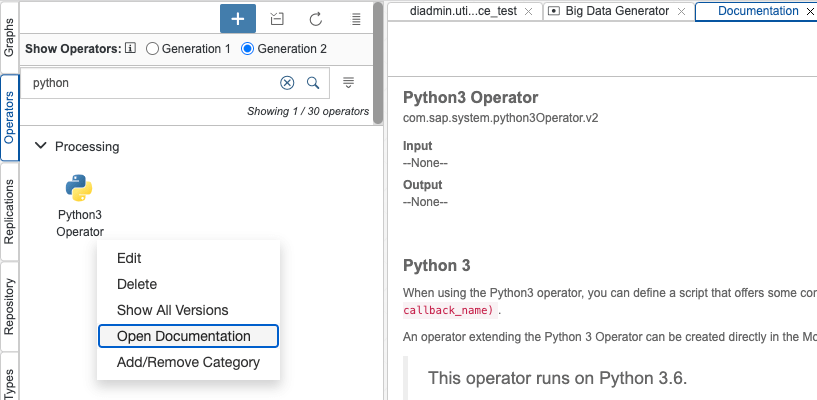
First when you like you like to add a new Custom Python operator choose the “Python3 Operator (Generation 2)” option.
Sending Data Operator
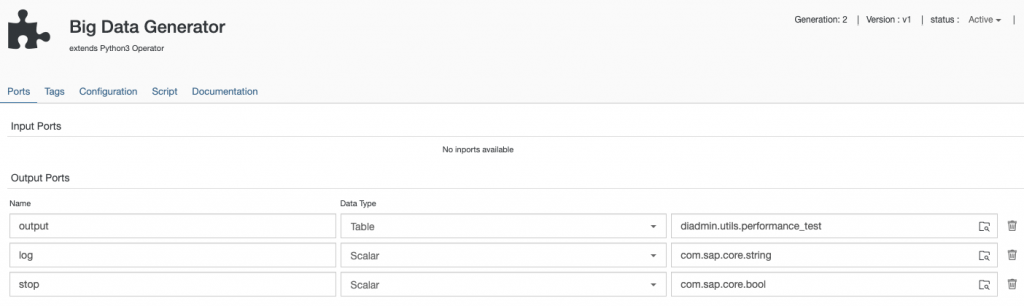
To be explicit for my operator “Big Data Generator” I need no inport because I am going to use a timer that should regularly produce data tables and 3 outports:
- output of data type table using the previously defined table data type diadmin.utils.performance_test
- log of data type scalar com.sap.core.string for replacing the debug functionality
- stop of data type scalar com.sap.core.bool for stopping the pipeline
For the configuration I add 3 parameters
- num_rows (integer) for the number of records
- periodicity (number) for the seconds to generate a new data table
- max_index (integer) for the number of iterations before the pipeline should stop
- snapshot_time (integer), the idle time before the forced exception is raised
- crash_index (integer), the index at which the forced exception should be raised to demonstrate the resilience.
Finally we come to the scripting.
First I need to generate data consisting of an integer “id”, a Python datetime “timestamp”, random float and string column:
def create_test_df(num_rows,str_len=5):
alphabeth = list(string.ascii_lowercase)
df = pd.DataFrame(index=range(num_rows),columns=['id','timestamp','string_value','float_value'])
df['id'] = df.index
df['timestamp'] = datetime.now(timezone.utc)
df['string_value'] = df['string_value'].apply(lambda x: ''.join(np.random.choice(alphabeth, size=str_len)))
df['float_value'] = np.random.uniform(low=0., high=1000, size=(num_rows,))
return dfThe callback function looks like:
from datetime import datetime, timezone
import string
import pickle
import time
import pandas as pd
import numpy as np
def gen():
global index, data_df, crashed_already
api.logger.info(f'Create new DataFrame: {index}')
data_df = create_test_df(index,api.config.num_rows)
# Create Header
header_values = [index,api.config.max_index,api.config.num_rows,float(api.config.periodicity)]
header = {"diadmin.headers.utils.performance_test":header_values}
header_dict = dict(zip(['index','max_index','num_rows','periodicity'],header_values))
api.logger.info(f'Header: {header_dict}')
# Check if graph should terminate
if index >= api.config.max_index: # stops if it is one step beyond isLast
api.logger.info(f'Send msg to port \'stop\': {index}/{api.config.max_index}')
api.outputs.stop.publish(True,header=header)
return 0
# forced exception
if index == api.config.crash_index and (not crashed_already) :
api.logger.info(f"Forced Exception: {index} - Sleep before crash: {api.config.snapshot_time} - Crashed already: {crashed_already}")
crashed_already = True
time.sleep(api.config.snapshot_time)
raise ValueError(f"Forced Crash: {crashed_already}")
# convert df to table including data type cast
data_df['timestamp'] = data_df['timestamp'].apply(pd.Timestamp.isoformat)
data_df = data_df[['batch','id','timestamp','string_value','float_value']]
tbl = api.Table(data_df.values.tolist(),"diadmin.utils.performance_test")
# output port
api.outputs.output.publish(tbl,header=header)
# log port
api.outputs.log.publish(f"{index} - {data_df.head(3)}")
index += 1
return api.config.periodicity
api.add_timer(gen)There are two comments regarding to the changes from Generation 1 scripts:
Outports
With Gen2 the outport name is now an attribute of the class “outputs” (api.output.output, api.output.log and api.output.stop) and the outport has the method publish that takes 3 arguments: api.outputs.<port_name>.publish(data, header=None, response_callback=None) where only the data is necessary.
Outport Data Format
Data send to outports must comply to the data types of the outport. That means
- scalars: data value according to the vtype representation (see table)
- structure: 1-dim list of values. For headers using “structure”-data type you have a dictionary with the key = vtype-id and a list of values with the given sequence
- table: api.Table constructor with the vtype-id and a 2-dimensional list of values
In this case we use a structure-vtype for the header (metadata) and a table-type for the actual data.
Structures consist of dictionary with one key, that is the vtype id (e.g. “diadmin.headers.utils.performance_test”) and an array of values with the same order as defined in the vtype definition.
header = {"diadmin.headers.utils.performance_test":[index,api.config.max_index,api.config.num_rows,float(api.config.periodicity)]}
A genuine dictionary might be helpful but that is the current approach. In addition there is no way to retrieve the vtype definition (names and data types) from the registry. This might be added in the next release.
For the table-vtypes we have some more support. To construct a table you need to pass the vtype-id and a 2-dimensional array for the data, e.g.
data_df['timestamp'] = data_df['timestamp'].apply(pd.Timestamp.isoformat)
data_df = data_df[['batch','id','timestamp','string_value','float_value']]
tbl = api.Table(data_df.values.tolist(),"diadmin.utils.performance_test")Again you have to check if the order of the columns corresponds to the vtype definition and if the data types are among the supported. In the case of the datetime I convert it to a string in isoformat.
With this we have all the pieces for the first generation 2 operator. But be aware that for testing this operator you have to connect operators to all ports to which you send data or comment out the “publish”-call.
Receiving Data Operator
As a counterpart for the previously described “sending” operator we create a simple “receiving” operator with the same inport data type. Because the operator is doing nothing but providing food for the garbage collector of Python we call it “Device Null”.
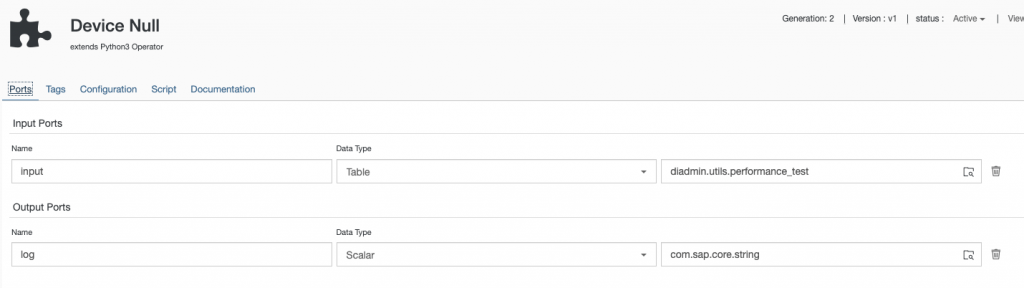
The script does nothing more than to unpack the header information and the data and construct a pandas DataFrame.
import pandas as pd
def on_input(msg_id, header, data):
header_dict = dict(zip(['index','max_index','num_rows','periodicity'],list(header.values())[0]))
tbl = data.get()
api.outputs.log.publish(f"Batch: {header_dict['index']} Num Records: {len(tbl)}",header=header)
tbl_info = api.type_context.get_vtype(tbl.type_ref)
col_names = list(tbl_info.columns.keys())
df = pd.DataFrame(tbl.body,columns = col_names)
api.set_port_callback("input", on_input)callback function “on_input”
The callback function of an inport has three arguments
- message_id: for identifying the message
- header: the metadata information always a list of vtype “structure”
- data: the data with one of the types scalar, structure or table
Access to the Header
Unsurprisingly the header data can be access reciprocal to the creation. The header is a dictionary with an array of the values, e.g the first value “index” can be retrieved by
header['diadmin.headers.utils.performance_test'][0]
or again you map the data to dictionary that reflects the vtpye-definition of the header
header_dict = dict(zip(['index','max_index','num_rows','periodicity'],list(header.values())[0]))
Hope this is not too cryptic. Sometimes I cannot deny my strong C and PERL -heritage.
said previously it would be a bit more elegant if an api-method would provide this data-structure in the first place.
Access Data of a Table
To get the data of a Table you have to call “data.get()” to connect to the underlying data stream and load it. The data itself – the 2-dimensional list – is stored with the attribute body. In order to build again a DataFrame out of a table you need to accomplish the following steps:
- tbl = data.get() – for creating a table instance from the data-message
- tbl_info = api.type_context.get_vtype(tbl.type_ref) – for getting the data-type reference
- col_names = list(tbl_info.columns.keys()) – for getting the column names via the vtype-reference stored in the table instance
- df = pd.DataFrame(tbl.body, columns = col_names) – build the DataFrame
As an advanced option you can exert an dtype-conversion by using the tbl_info.columns-dictionary with the column-names as key that gives you the components/scalars of the table. These you can map to the pandas data types.
There is a standard conversion-to DataFrame planned that will relieve you from the above steps but it will of course come with performance price and might not exactly match to your kind of data. For a standard conversion not only the data types but also the NaN-values have to be processed.
Streaming-Support
Sometimes in particular for big data it makes sense to convey the data in batches rather in one chunk of data. For this you can create a writer and a reader of a stream and then read only the pieces you like to digest. You can mix both kind of operators, e.g. send all the data at once and the next operator only reads batches. This is what we are going to do here and change the script of the receiving operator:
import pandas as pd
def on_input(msg_id, header, data):
header_dict = dict(zip(['index','max_index','num_rows','periodicity'],list(header.values())[0]))
table_reader = data.get_reader()
tbl = table_reader.read(2)
tbl_info = api.type_context.get_vtype(tbl.type_ref)
col_names = list(tbl_info.columns.keys())
df = pd.DataFrame(tbl.body,columns = col_names)
while len(tbl) > 0 :
api.outputs.log.publish(f"Stream: {header_dict['index']} Num Records: {len(tbl)}",header=header)
tbl = table_reader.read(2)
dft = pd.DataFrame(tbl.body,columns = col_names)
df.append(dft, ignore_index=True)
api.set_port_callback("input", on_input)The essential difference are the following lines
table_reader = data.get_reader()
tbl = table_reader.read(2)instead of calling the “get”-method you create first a reader-instance and then read the number of data records you like until nothing is left in the stream. If you pass ‘-1’ then you get all data left in the stream. You do not have to care about the number of bytes. The given data-structures is used for doing the job automatically under the hood similar to a ‘readline’ of FileIO. This is definitely a very handy feature having missed in the past.
Snapshot
For big data processing pipelines that might run for days you always had to find a way to bookkeep the process status to be able to restart from the last process step instead from the very beginning. This you had to do for every pipeline again. Now with the snapshot feature it is part of each generation 2 operator. As you will see the additional effort is quite reasonable and you do not have to do it for each operator.
Marcel Oenning pointed out that in general whenever a pipeline restarts that has operators with a state that is essential for producing the correct output resilience is mandatory. It is not only matter of convenience when processing big data.
The mechanism is quite easy. When you start a resilient pipeline you need to pass the seconds you like the pipeline is doing a snapshot of its state and the number of restart trials within a certain period:
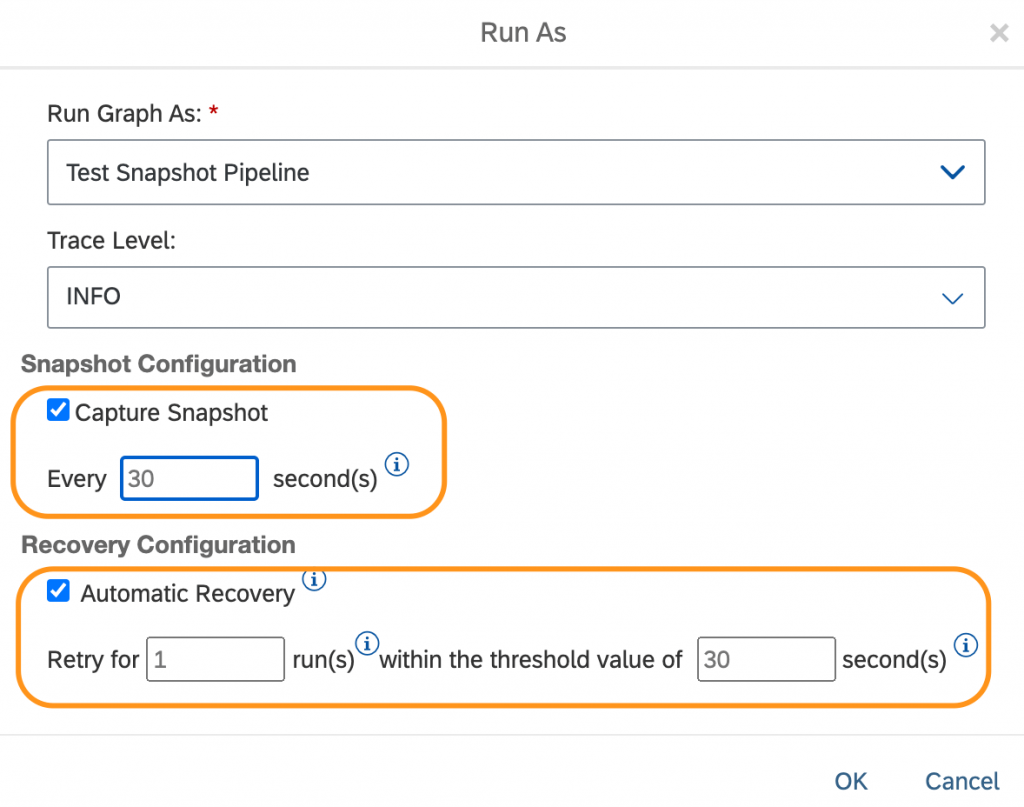
In the operator you have to define to new functions:
- serialize – for saving the data
- restore – for loading the data
and pass these to the corresponding api-methods
- api.set_serialize_callback(serialize)
- api.set_restore_callback(restore)
There are 2 other methods to be added but will not be configured
- api.set_epoch_complete_callback(complete_callback)
- api.set_initial_snapshot_info(api.InitialProcessInfo(is_stateful=True))
In our example I like to save the state of the first operator “Big Data Generator”, that means the index (=number of already generated data batches) and the generated DateFrame. In addition I like to save the information if the operator has already crashed because I like to infuse a toxic index that leads to a deliberately raised Exception. With this flag I ensure that the pipeline crashes only once.
def serialize(epoch):
api.logger.info(f"Serialize: {index} - {epoch} - Crashed already:{crashed_already}")
return pickle.dumps([index,crashed_already,data_df])
def restore(epoch, state_bytes):
global index, data_df, crashed_already
index, crashed_already, data_df = pickle.loads(state_bytes)
api.logger.info(f"Restore: {index} - {epoch} - Crashed already:{crashed_already}")Of course you have to ensure that all operator data that you like to save needs to be a global variable.
index = 0
crashed_already = False
data_df = pd.DataFrame()The toxic code I add to the script:
# forced exception
if index == api.config.crash_index and (not crashed_already) :
crashed_already = True
time.sleep(api.config.snapshot_time)
raise ValueError(f"Forced Crash: {crashed_already}")Before the Exception is raised the status “crashed_already” needs to be set and then some time is needed for the system to do a snapshot. The “sleep”-time has to be longer that the snapshot periodicity. This is obvious but I needed to learn this by 30min of tries and errors.
By the way the final pipeline looks like this
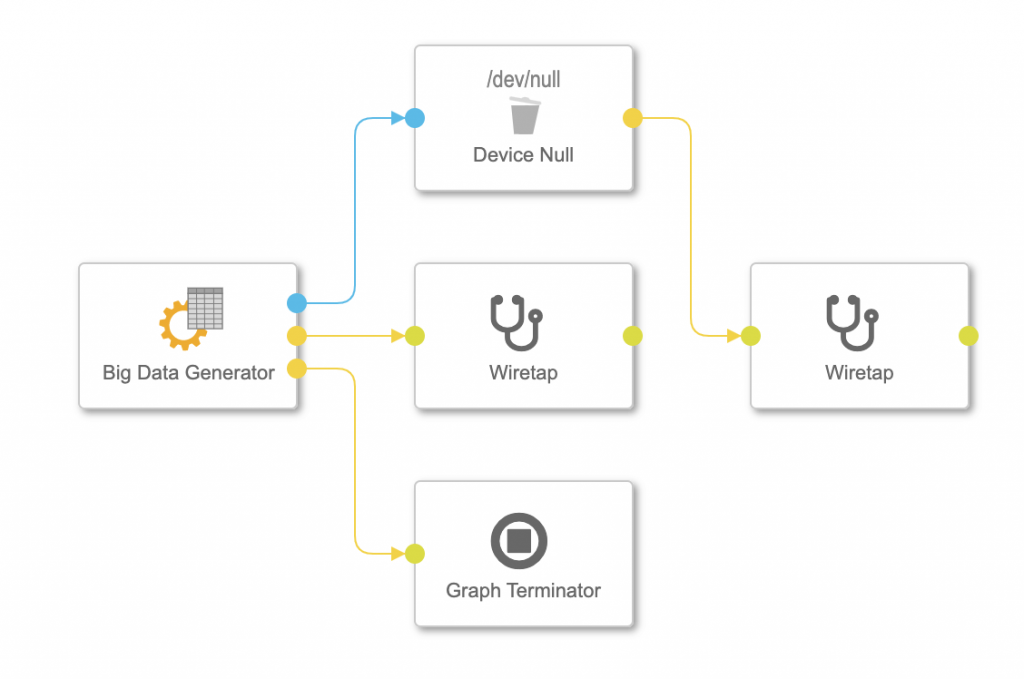
For a shortcut you can download a solution of the vtypes, operators and pipeline from my private GitHub.
Cross-engine data exchange
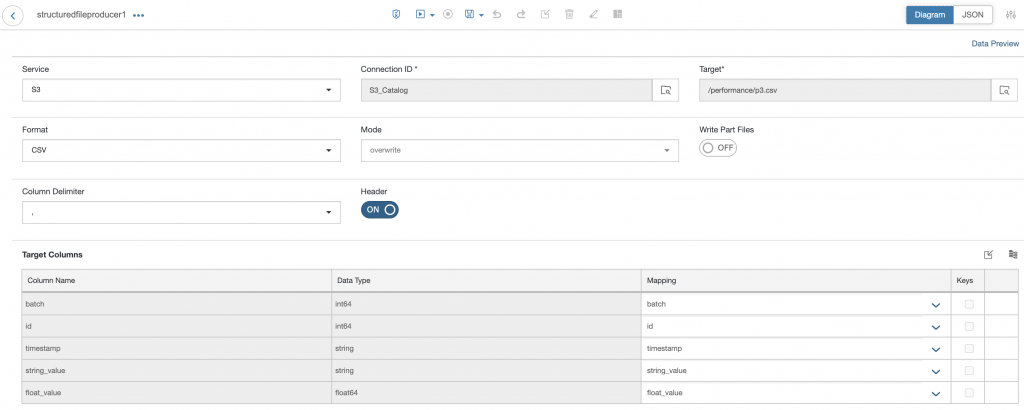
Finally with the Generation 2 operators you can connect all operators irrespective of the underlying subengine if the datatype matches. In our case if we like to save the generated data to File or Database we use the Structured Data Operators with all its convenience of data preview, mapping etc. I suppose this is what most of us are going to love.
In the next releases all of the commonly used operators will also be available as generation 2 operators and will boost the productivity and the robustness of the pipelines.









