Digging into further analysis of the data, using some newer technologies and datasets, I want to focus on a couple of areas:
- Finding Similar Activities using the HANA Vector Engine
- Using External Datasets to enrich data, and in my case find areas of concern using HANA Spatial Engine (not new but always good to use newer datasets).
- Restricting data between users using SAP Data Access Controls.
Also additional SAP Analytics Cloud examples developed will be demo’ed as part of a Webinar that will be linked to this blog.
With a bit more details:
1. Finding Similar Events using the HANA Vector Engine
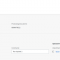
Using a dataset of about 2000 different activities, the goal was to find similar efforts, irrespective of location. Here is a sample of a few records to get an idea of the dataset:
Using the columns: Elapsed Time, Distance. Relative Effort and Elevation Gain – I created vectors in the HANA Cloud based on these values:
ALTER TABLE LOCAL_ACTIVITIES ADD (EMBEDDING REAL_VECTOR);
UPDATE LOCAL_ACTIVITIES SET EMBEDDING = TO_REAL_VECTOR('[
'||to_varchar("Elapsed Time")||',
'||to_varchar("Distance")||',
'||to_varchar("Relative Effort")||',
'||to_varchar("Elevation Gain")||']')
WHERE "Elapsed Time" IS NOT NULL
AND "Distance" IS NOT NULL
AND "Relative Effort" IS NOT NULL;Then creating a view on this, which can be used as a view / SQL query in Datasphere:
CREATE VIEW RELATED_ACTIVITIES_VECTOR_V as
SELECT
A."Activity Date" AS "SourceActivityDate", B."Activity Date" AS "TargetActivityDate", A."Activity Name" AS "SourceActivityName",
B."Activity Name" as "TargetActivityName", A."Distance" AS "SourceDistance",
B."Distance" AS "TargetDistance", A."Relative Effort" AS "SourceRelativeEffort", B."Relative Effort" AS "TargetRelativeEffort",
A."Elevation Gain" AS "SourceElevationGain", B."Elevation Gain" AS "TargetElevationGain",
cosine_similarity(A.EMBEDDING, B.EMBEDDING) COS,
l2distance(A.EMBEDDING, B.EMBEDDING) L2
FROM LOCAL_ACTIVITIES A, LOCAL_ACTIVITIES B
WHERE A."Activity ID" > B."Activity ID"
AND cosine_similarity(A.EMBEDDING, B.EMBEDDING) > .999999
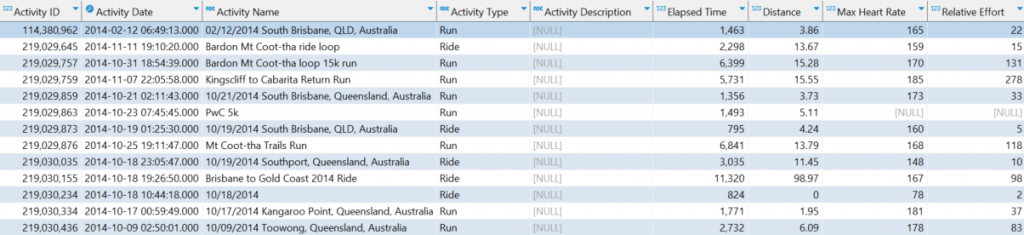
AND l2distance(A.EMBEDDING, B.EMBEDDING) < 100;Then making the query available in Datasphere and presenting the results in SAP Analytics Cloud:
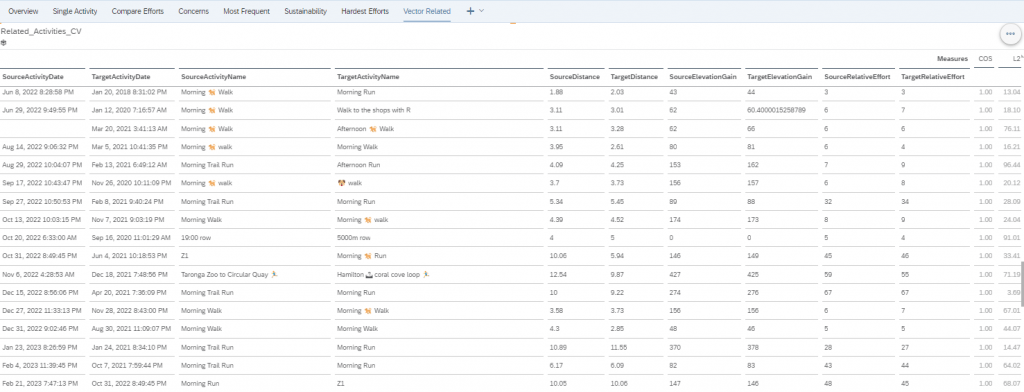
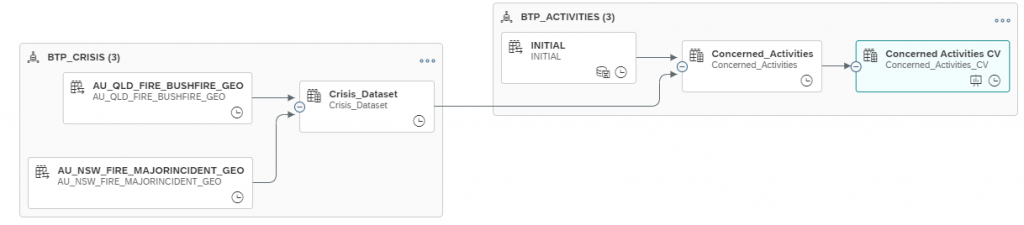
2. Using External Datasets to enrich data, and in my case find areas of Concern using HANA Spatial Engine.
In a separate Datasphere space, we have a range of Global Crisis Datasets. For me and my fitness data, I thought the simplest would be determining if I ran near any fires as part of my run. Yes, this data is hindsight – but either way an interesting use case. we easily build a BTP Build App that is preventative to the user, but I’ll leave that for someone else in my team to build.
So picking Queensland and New South Wales fire data, and joining them together:
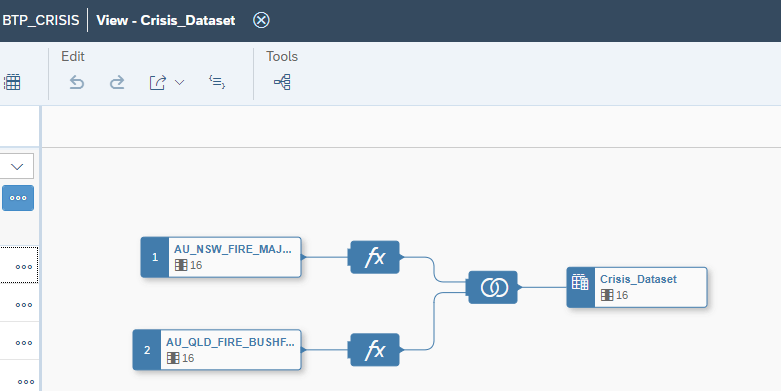
In a relatively simple query, I can perform geospatial analysis query based on location and time:
SELECT distinct "L_ROW", "Activity ID", "ACTIVITY_DATE", "Activity Type", "SOURCE", "DESCRIPTION", TO_INTEGER("GEO".ST_TRANSFORM( 3857 ).ST_Distance("ST_POINT_3857", 'kilometer')) "Distance_KM",
"A"."LATITUDE" "ACTIVITY_LATITUDE",
"A"."LONGITUDE" "ACTIVITY_LONGITUDE",
"C"."LATITUDE" "CRISIS_LATITUDE",
"C"."LONGITUDE" "CRISIS_LONGITUDE"
FROM "INITIAL" "A", "BTP_CRISIS.Crisis_Dataset" "C"
where "GEO".ST_TRANSFORM( 3857 ).ST_Distance("ST_POINT_3857", 'kilometer') < 2
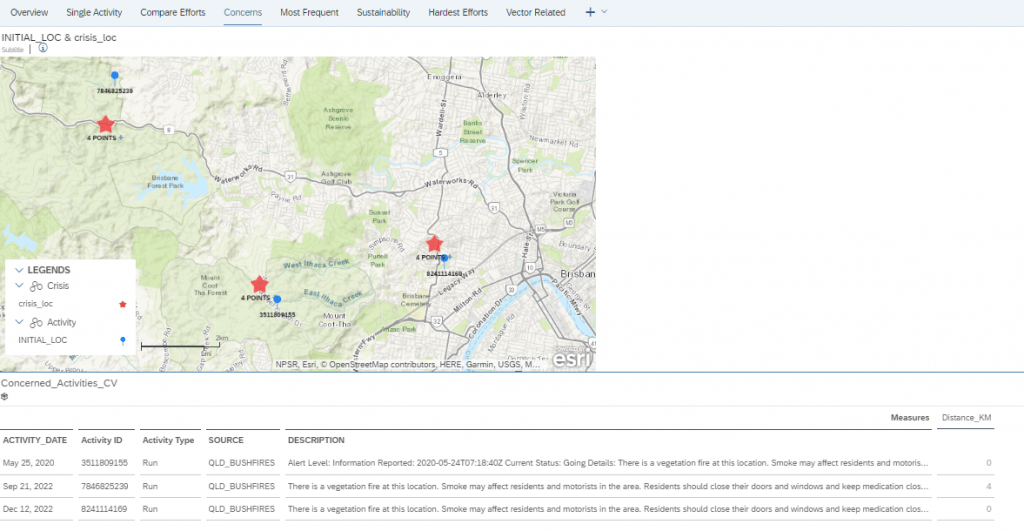
and "ACTIVITY_DATE" BETWEEN add_days("PUBLISHED", -1) AND add_days("PUBLISHED", 1)This query is finding all the fire warnings that were published within 1 day, and within 2 km of my start point of the run. I could have also made these parameters, so that the user can also dynamically choose the timescale and the distance. I could also have used the query to be based on any point on the run. Maybe as a V2.
Once, I enable this data to be viewed in SAC, I can quickly get the output:
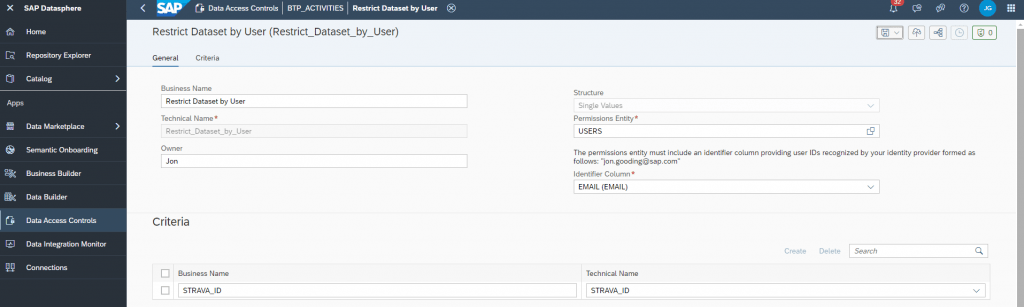
3. Restricting data between users using SAP Data Access Controls.
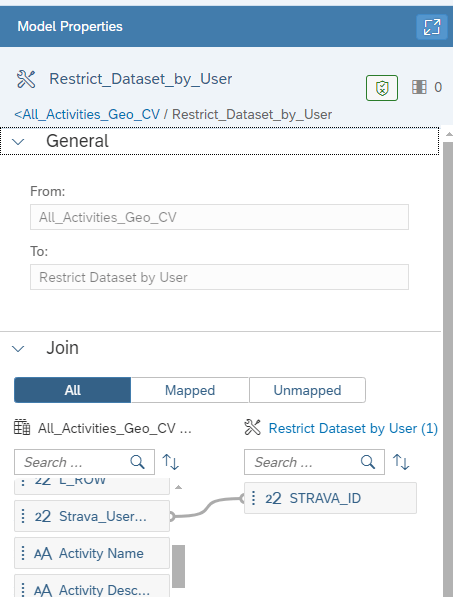
The data I am loading into the SAP Datasphere instance is multi-user and there is a requirement to keep it isolated across users. So to ensure data privacy, the Datasphere Data Access Controls
The datasets is unique by user of the Strava Id, so we can simply apply Data Access Controls to limit to their own datasets. For this, a reference table / view is needed, and we simply create a Data Access Control over based on the requirements:
Applying the Data Access Controls to the appropriate Views:
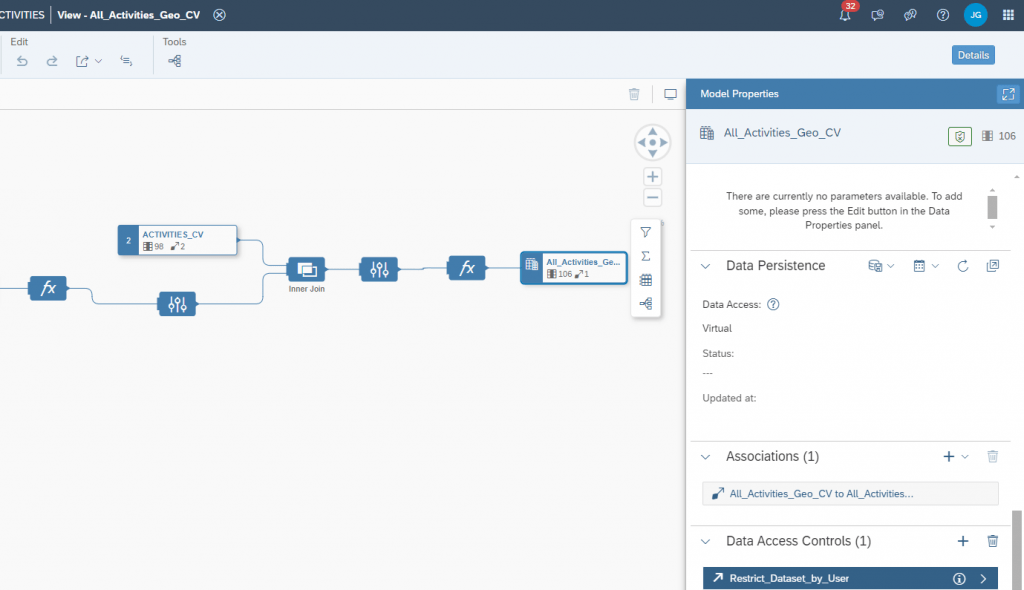
Now we have a platform that allows us to performs some rich data analysis using modern tools that suit the individual – using their own datasets. Some examples that have been used are around Jupyter Notebooks, DBeaver Analysis and also using text input the Vector engine to match this to the existing datasets. More to come in future blogs and Webinars.
Personally, I think it’s so much more interesting using you own datasets, in this case a personal fitness dataset – or in the business world , your own systems data – which can easily be supplemented into this technology to gain some invaluable insights.