
Introduction
Data volumes are growing and the pace of this growth is unprecedented. The volume, variety, velocity and veracity of these data coming from Sensor, Social media, and other sources are far outstripping traditional data warehousing approach. With all this new data connecting us, we should be sailing smoothly. Unfortunately, we are drowning in our own data. Forward-looking organizations are trying to harness these new sources in a productive way to achieve unprecedented value and competitive advantage.
What is Data Lake?
As of now, there is no Clear industry definition for Data Lake. For some, Data Lake is a repository for large quantities and varieties of data, both structured and unstructured. For others, data lake is an architectural strategy and an architectural destination. But the concept of data lake is emerging as a popular way to organize and build the next generation of systems to face the big data challenges. The need for data lake arose because a new type of data needed to be captured and exploited by the organizations.
Capabilities and Salient Features of Data Lake:
- Capture and store huge amount of raw data at low cost. Can be scaled very easily.
- Supports Advance Analytics. Utilizes the large quantities of coherent data and facilitates the use of various algorithms (e.g. deep learning) for analytics.
- Allows Schema-Less Write and Schema based Read. This is very handy at the time of data consumption.
- No compulsion of data modeling at the time of Data Ingestion. It can be done at the time of consumption.
- Can store data from diverse sources and in various formats e.g. Sensor data, social media data, XML and more.
- Accommodate high-speed data in conjunction with additional tools like Kafka and Flume.
- Perform single subject analytics base on specific use cases.
- Data Lake with Hadoop 2.0 with YARN overs comes the limitation of Batch -oriented and only single means for user interaction with data.
Data Lake vs. Data warehouse
Both have their own sweet spot. The enterprise data warehouse was designed to create a single version of the truth, that can be reused again and again. The model is based on schema on write, thereby demanding a lot of time during design and modeling. This makes it less flexible. On the other hand, if you need Fast response time, high concurrency consistent performance, easily consumable data and Cross-functional analysis – Enterprise data warehouse is the option to go ahead with.
Let’s try to summarize few of the differences between Data Lake and Data Warehouse:
| Data Lake | Data warehouse | |
| Data | Raw, Structured, Unstructured, semi-structured. | Structured, processed |
| Storage | Low-cost storage | Expensive for large data volumes |
| Processing | Schema -on -read | Schema – on -write |
| Agility | Configurable and reconfigurable as and when needed. | Fixed configuration |
| Security | Work in progress | Mature |
| User | Meant for Data scientists | Business and Technical users. |
| Analytics Support | Excels at utilizing the large volume of coherent data | Limited. |
| AS-IS data format | Data modeling not required at time of Ingestion can be done at the time of consumption. | Typically, Data is modeled as a cube during ingestion. |
| Access Methods | Data Accessed through programs created by developers, SQL-like systems. No standard of the prefixed way. | Data Accessed through standard SQL and BI tools. |
With few complimentary set of features and property, the data lake concept has impacted the organization traditionally using the only data warehouse. One of the visible extension of data lake role in such organization is using data lake for preparing data for analysis in a data warehouse.
It can be used as “scale-out ETL” environment for big data and get the data into a form that can be loaded into a warehouse for wider use. By doing so organizations are not only running ETL against data from enterprise application but also from big data sources at the same time.
Many organizations owning both Data Lake and Enterprise Data Warehouse are using both the environments in distributed fashion for Analytics. Media files like video, audio, images etc are stored in the filesystem of data lake and are exposed to various analytics tools to extract insights. The other data which could include unstructured or semi-structured are also stored in the filesystem but are exposed to separate sets of analytics tools. Once processed the results of analytics are distilled further and moved to Enterprise Data Warehouse for a wider audience.
In short, Organizations are trying to use Data Lake and Enterprise Data warehouse as a hybrid unified system which can full fill their data discovery and data exploration needs, thereby allowing them to visualize the data as and in the form they want. Hybrid solution provides users to take what is relevant and leave the rest.
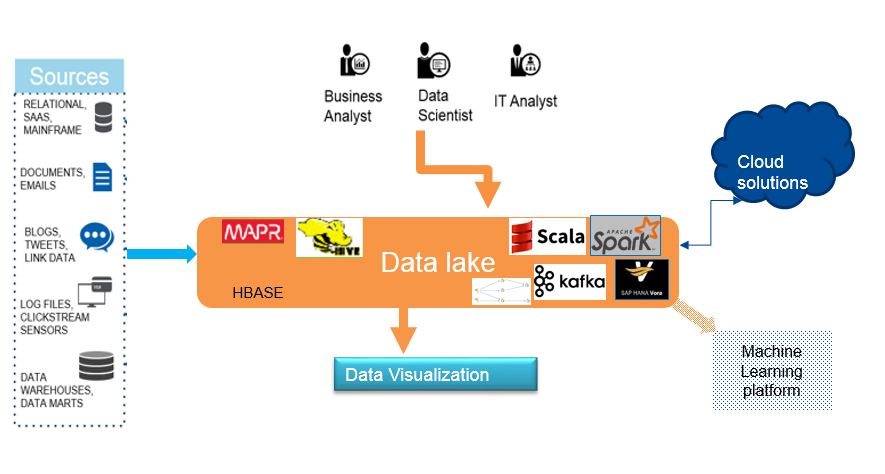
Fig: Generic landscape for Data Lake (please ignore the company specific flavors )
Points to consider while creating a Data Lake:
Depending upon our current situation, the road to data lake may differ. As always we first need to answer – “Where do we stand Now and Where do we want to Go with the data lake? “. The general recommendation is to follow your Data.
| Steps | Parameters |
| Step 01 (Start Point) | Know the volume, variety, velocity, and veracity of Data. For any organization, it’s important to learn and make sure that Hadoop works the way they desire (in their context). This is very important from a future perspective. Normally at this stage organization should indulge in simple analytics. |
| Step 02 | The focus moves from learning to improving on Analytics capability. In this stage, the organization should look for suitable tools and skillset to acquire more data and build an application on top of it. Transforming the data and co-creation of hybrid scenarios along with data warehouse should also be explored and worked onto. |
| Step 03 | Democratization data, provide access to as many people as possible. Data Lake and Enterprise data warehouse start playing the respective roles. |
| Step 04 (Long Running phase) | Apply Governance compliance and Auditing. Depending upon the maturity level of your Data Lake, you can apply the Governance concepts. |
Data Lake Maturity:
The data lake will fill with new data slowly and will not impact the existing models. The data lake foundation includes a big data repository, metadata management, and an application framework to capture and contextualize end user feedback. The increasing value of analytics is then directly correlated to increases in user adoption across the enterprise.
- Consolidation and categorized raw Data
- Attribute -level Metadata Tagging and linking
- Data Set extraction and Analysis.
- Business-specific tagging, synonym identification, and links.
- Convergence of Meaning within Context.
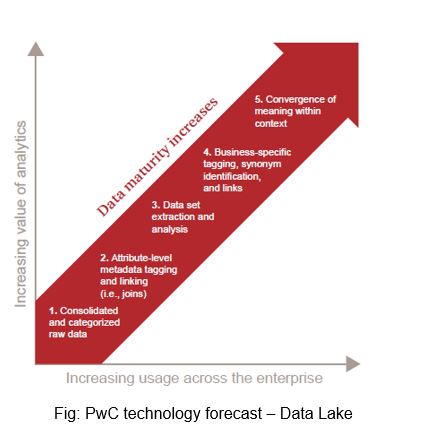
There is another school of thought which defines the Data Lake maturity in four step model:
Stage 1 – Evaluating Technology
Stage 2 – Reactionary
Stage 3 – Proactive
Stage 4 – Core Competency
As the organization progresses from stage 1 to 4, your data lake transforms from Technology infrastructure to Business Value. In course of the transformation, your organization gains IT efficiency, Analytical capabilities and hybrid usage of Enterprise Data warehouse and Data lake.









