As promised in part one, let’s have a closer look at the delta handling in CDS based extraction.
In cases, in which big data volumes with a frequent changes are expected, e.g. transaction data like sales orders or similar, the application needs to provide delta records. In most of the cases daily (nightly) full uploads are not what you want, as time windows for data extractions are limited. Extraction of transaction data should always be delta enabled as this allows a seamless loading and reporting scenario.
The good news, the ODP framework for CDS extraction provides delta capabilities. You have actually two options for delta handling that you can chose from:
- Generic Timestamp / Date based Delta: This requires date/time information being available in the relevant application tables that is updated based on changes of the application data.
- Change Data Capture (CDC) Delta: This delta option captures changes to the application tables based on data base triggers and enables the ODP framework to just provision these newly created/changed/deleted records to the consumers.
Let’s check the two delta mechanisms in detail below, from which you can infer which option suites your data model and logic best.
Generic Date/Timestamp Delta
The generic delta based on date / timestamp has been around since release SAP S/4HANA 1809 on-premise and relies on a date/time element being present in the CDS view reflecting the changes of the underlying records.
You can use the following field types as delta criterion:
- UTC timestamp
- date field (ABAP type DATS)
Using a UTC time stamp is the preferred way for delta extraction. If no appropriate UTC time stamp is available in the application tables/CDS view, a date field can be used as well.
The following annotation identifies the relevant time/date field to be used by the ODP framework:
@Analytics:{
dataCategory: #FACT,
dataExtraction: {
enabled: true
delta.byElement: {
name: 'LastChangeDateTime'
}
}
}Using this field, the ODP framework determines up to which record a data consumer has extracted records already. On a subsequent extraction request, only records with a higher time stamp/date value are extracted.
As safeguarding measure, a safety interval can be specified. This can accommodate technical delays like waiting for a database commit on the application system side.
You can specify the safety interval using this annotation
@Analytics.dataExtraction.delta.byElement.maxDelayInSeconds
If you do not add this annotation, a default delay of 1800 seconds, i.e. half an hour, is applied.
@Analytics:{
dataCategory: #FACT,
dataExtraction: {
enabled: true,
delta.byElement : {
name: 'LastChangeDateTime',
maxDelayInSeconds : 1800
}
}
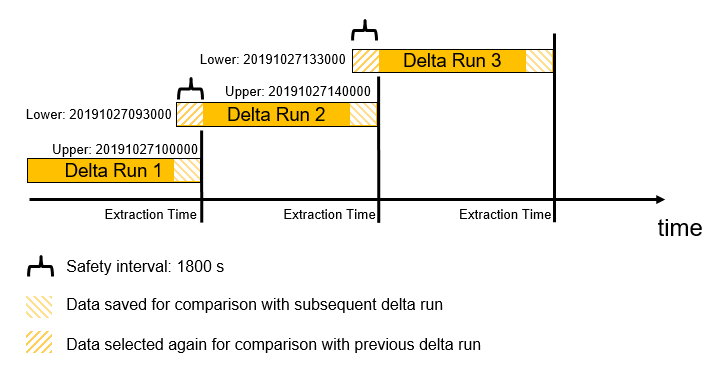
}A record with a time stamp falling in this time safety interval will be selected twice from the CDS view. Once with extraction run 1 and once with extraction run 2. The ODP frame work stores key data and hashes of all records belonging to the safety interval for finding changed records.
In the extraction run 1 records belonging to the time interval Start Timestamp of Extraction run 1 – maxDelayInseconds will be stored for later comparison.
In subsequent extraction run 2, records belonging to this time interval will be selected again and compared against the formerly saved records/hashes of extraction run 1.
Only records with changed hashes belonging to the safety interval will be extracted “again” to reflect the changes in the target system. Previously extracted records that have not changed within the safety interval, will not be extracted again.
Detecting deletion records using the generic delta
With the annotations so far, you will get newly created records as well as updates to existing records, but no deletions. The annotation
@Analytics.dataExtraction.delta.byElement.detectDeletions
enables the view to detect deleted records as part of the generic delta mechanism.
@Analytics:{
dataCategory: #DIMENSION,
dataExtraction: {
enabled: true,
delta.byElement : {
name: 'LastChangeDateTime',
detectDeletions : true
}
}
}Including this annotation will store all record key combinations being extracted in a separate data storage.
To identify deletions all records of this data storage are compared against all records still available in the CDS view during each extraction run. Records not available in the view anymore are sent to the consuming clients as deletions.
Needless to mention that this concept is only feasible for low level volumes of data (~< 1.000.000 data records) and should not be used for high volume data applications. Hence this mechanism is mainly applicable for small master data and text extractions.
The annotation
@Analytics.dataExtraction.delta.byElement.ignoreDeletionAfterDays
can be used to reduce the time frame of which records are considered for the deletion comparison. This means you have a trailing limit and only the set of extracted records falling into this time frame are compared against the currently available records in the CDS view.
@Analytics:{
dataCategory: #DIMENSION,
dataExtraction: {
enabled: true,
delta.byElement : {
name: 'LastChangeDateTime',
detectDeletions : true,
ignoreDeletionAfterDays : '365'
}
}
}Examples:
- Archiving: If data base records in your source system were archived after one year, you could define a value of 365. In this case, these “deletions” due to archiving in the data base tables will be ignored. In data warehouse scenarios you usually would not want these archiving deletions on source system side propagated as deletions in your data warehouse.
- The application can guarantee a fixed time frame in which records can be deleted, preventing records to be deleted after this time frame; then only this interval needs to be taken into account for the deletion detection comparison.
Miscellaneous facts for Generic Delta
Please note the extraction example in the following figure, uses a date (ChangeDate), as the delta identifier.
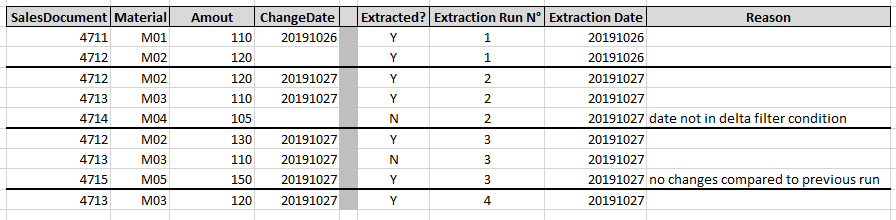
- Data records with an empty ChangeDate are only extracted during a “Delta Init with data”.
- After the “Delta Init with data” has run, newly created records having an empty ChangeDate field will not be extracted anymore during further delta requests. (Record 4714).
- Intraday changes will be reflected during intraday delta requests (cf. record 4712 on 27. Oct 2019) and corresponding records will be extracted again.
- Timestamp based delta extraction only supports one time field (time stamp or date). This means only one field can be identified in the @Analytics.dataExtraction.delta.byElement.name annotation. You cannot assign two fields, e.g. creation date CREADAT and change date CHANGEDAT of an application table as delta determinants. You will need to make sure, that the change date field is equally filled at creation time and not only after a first change to the record. Otherwise these records will not be considered during delta updates.
- Use only persisted time-stamp or date fields and refrain from using virtually derived or calculated fields in CDS views. This can lead to severe performance penalties.
Change Data Capture Delta
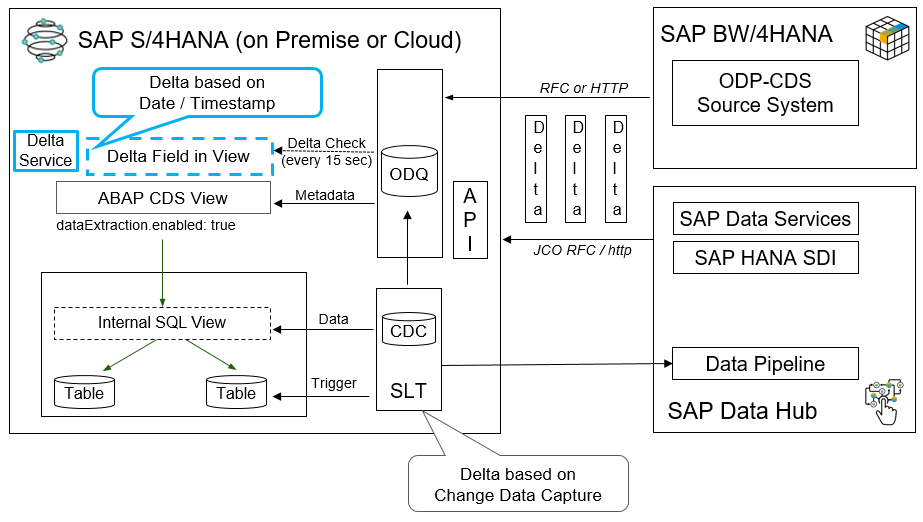
Starting with SAP S/4HANA Cloud 1905 and SAP S/4HANA 1909 FPS01 (on-premise) an additional delta capability facilitating database triggers can be used.
The second delta method goes by the name of Change Data Capture (CDC). For a CDS view using this delta method, changes in tables belonging to this view are recorded by the Change Data Capture mechanism. From a technology point of view this delta method makes use of real-time database triggers on table level based on SLT technology.
INSERT, UPDATE and DELETE operations can be recorded by the framework.
To function properly, the key fields of all underlying tables need to be exposed as elements of the CDS view and be mapped accordingly. The framework records the key field values of the changed table rows.
In case of an INSERT or UPDATE operation a scheduled job is selecting the records based on these key combinations from the CDS view and pushes them as complete records into the Operational Delta Queue (ODQ).
In case of a DELETE operation the job generates an empty record with just the key field(s) filled, sets the deletion indicator and hands them over to ODQ.
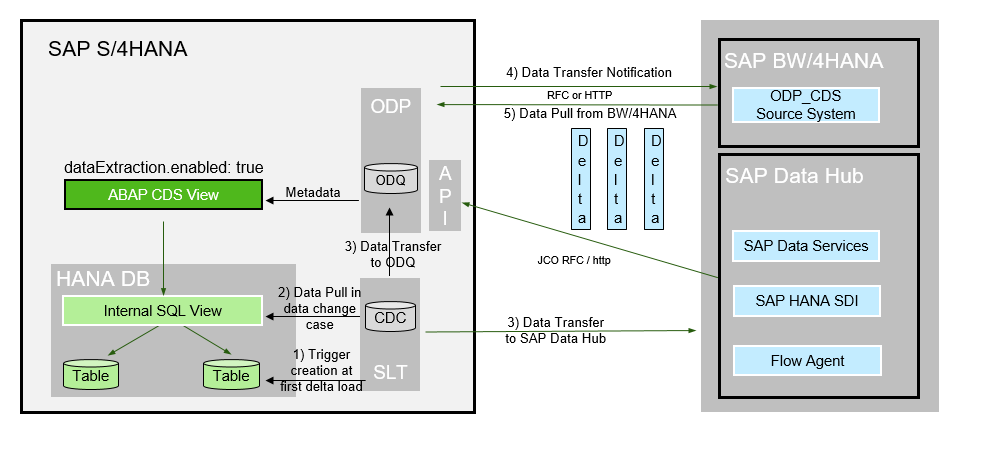
Let’s go into the detailed annotations needed for the CDC delta method.
The main task for exposing a CDS view with CDC delta method is to provide the mapping information between the fields of a CDS view and the key fields of the underlying tables. The mapping is necessary to enable a comprehensive logging for each of the underlying tables and subsequently a consistent selection/(re-)construction of records to be provided for extraction. This means the framework needs to know which tables to log, i.e. monitor for record changes.
Given one record changes in possibly only one of the underlying tables, the framework needs to determine which record/s are affected by this change in all other underlying tables and need to provide as consistent set of delta records to the ODQ.
Projections
The easy case is a projection CDS view on a table.
In this case the frame work can derive the relation between the fields of the CDS view and key fields of the underlying table itself. Whenever a record is inserted, updated or deleted in the underlying table, a record with the respective table key is stored in a generated logging table. Based on this info the scheduled job selects the data record from the CDS view and pushes it into the ODQ.
To specify the CDC delta for simple projections, you can use the
@Analytics.dataExtraction.delta.changeDataCapture.automatic
annotation:
@Analytics:{
dataCategory: #DIMENSION
dataExtraction: {
enabled: true,
delta.changeDataCapture: {
automatic : true
}
}
}This is all you need and off you go with your CDC delta enabled extractor.
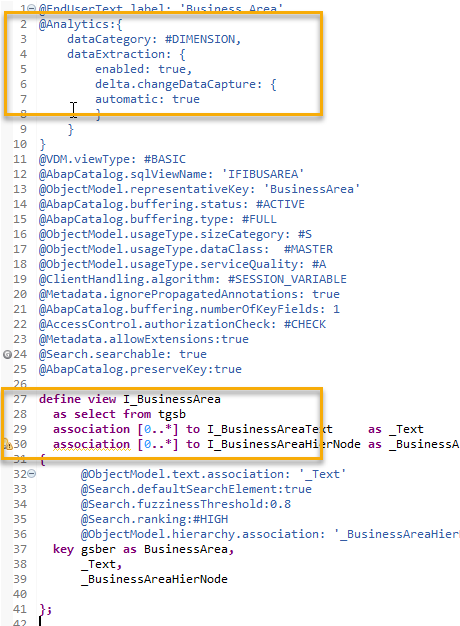
As an example for this, you can have a look at the CDS view for Business Area (I_BUSINESSAREA), which is a projection on table TGSB. In this case you only need the @ @Analytics.dataExtraction.changeDataCapture.automatic annotation.
Joins
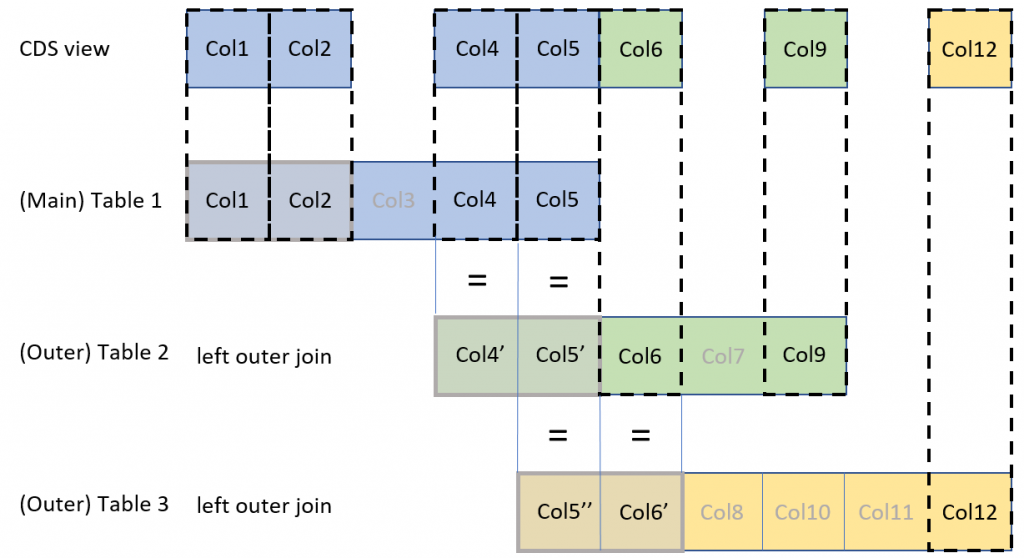
In other cases, like joins, the developer must explicitly provide the mapping to the frame work. Depending on the number of involved tables this can be a challenging task. All key fields of the main table and all foreign key fields used by all on-conditions of the involved join(s) need to be exposed as elements in the CDS views.
The first step is to identify the tables participating in the join and its roles in the join. Currently only Left-outer-to-One joins are supported by the CDC framework. These are the common CDS views with one or more joins based on one main table. Columns from other (outer) tables are added as left outer to one join, e.g. join from an item to a header table.
Given there are no restrictions applied to the CDS view, the number of records of the CDS view constitute the number of records of the main table. All records from the main table are visible in the CDS view. Deletions of a record with regards to this CDS view only happen, if the record in the main table is deleted.
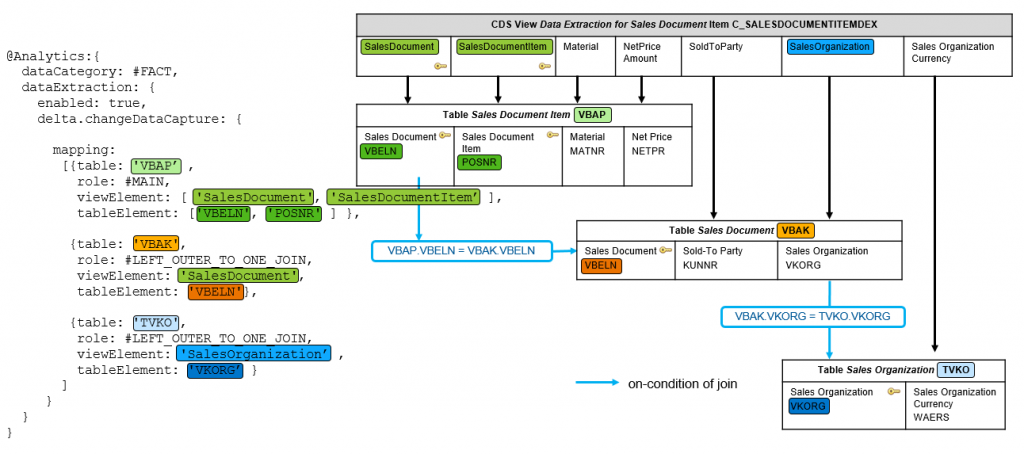
Secondly the developer needs to provide the mapping between the key fields of the underlying tables and their exposure as elements in the CDS view. Please check the following figure in which you see the representation of all underlying key fields surfacing in the CDS view.
The annotations relevant for this mapping task are subsumed under
@Analytics.dataExtraction.delta.changeDataCapture.mapping
@Analytics:{
dataCategory: #DIMENSION
dataExtraction: {
enabled: true,
delta.changeDataCapture: {
mapping : [ {
table : 'name of table',
role : #MAIN|#LEFT_OUTER_TO_ONE,
viewElement : ['list of CDS view elements'],
tableElement: ['list of table fields']
}, ...
]
}
}
}For each of the underlying tables, the following four mapping annotations must be maintained:
1. @Analytics.dataExtraction.delta.changeDataCapture.mapping.table
This annotation serves to identify the name of the underlying table(s) to be logged.
2. @Analytics.dataExtraction.delta.changeDataCapture.mapping.role
This annotation is used for identifying the role of a participating table
The main table receives the value #MAIN. The key(s) of the CDS view correspond(s) exactly to the key(s) of the underlying main table to be logged. The outer table(s) receive(s) the value #LEFT_OUTER_TO_ONE_JOIN.
3. @Analytics.dataExtraction.delta.changeDataCapture.mapping.viewElement
In case of the main table, (identified by role: #MAIN), this list enumerates all exposed CDS view element names corresponding to the key fields of the main table
In case of an outer table, (identified by role: #LEFT_OUTER_TO_ONE_JOIN), this list enumerates all exposed CDS view element names that correspond to key fields in this underlying outer table; in other words that correspond to the foreign key fields used in the on-conditions of the joins.
4. @Analytics.dataExtraction.delta.changeDataCapture.mapping.tableElement
This list enumerates the respective key fields of the underlying tables to be logged.
Both lists, viewElement and tableElement, must contain an equal number of elements and must list them in the same order so that corresponding fields match.
Important: for technical reasons all foreign key fields pointing to the respective outer tables which are used in joins need to be exposed as fields in the CDS view. If some of these fields are not meant to be consumed by the end user, they can be hidden by the annotation
@Consumption.hidden
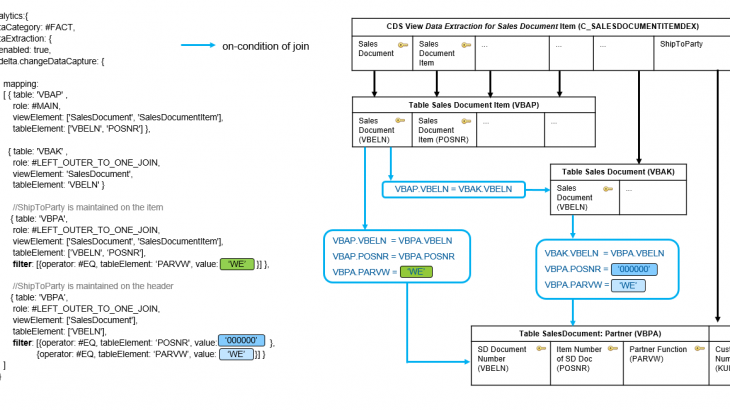
The figure below illustrates these mappings based on CDS view Data Extraction for Sales Document Item (C_SALESDOCUMENTITEMDEX) which you can find in any SAP S/4HANA system starting from release CE1905 /OP1909. Please note, not all annotations are listed here, but just the relevant ones for pointing out the mapping.
Filters
You might only want to track certain values which you deem relevant for your extraction. For this purpose you can use the filter annotation
@Analytics.dataExtraction.delta.changeDataCapture.mapping.filter
It can be used to define filter values on the table to be logged. If you only have a single filter value for a field, It can also be used to replace a missing mapping between a viewElement and a tableElement (i.e. an on-condition for a join).
@Analytics:{
dataCategory: #DIMENSION
dataExtraction: {
enabled: true,
delta.changeDataCapture: {
mapping : [ {
table : 'name of table',
role : #MAIN|#LEFT_OUTER_TO_ONE,
viewElement : ['list of CDS view elements'],
tableElement : ['list of table fields'],
filter: [{ tableElement : 'table element to be filtered'
operator : #EQ|#NOT_EQ|#GT|#GE|#LT|#LE|#BETWEEN|#NOT_BETWEEN;
value : 'filter value'
highValue : 'upper filter value in case of range' } ], ...
}, ...
]
}
}
}In detail, this is
…delta.changeDataCapture.mapping.filter.tableElement
specifies the table field to be restricted.
…delta.changeDataCapture.mapping.filter.operator
Restriction operator, possible values are: #EQ, #NOT_EQ, #GT, #GE, #LT, #LE, #BETWEEN, #NOT_BETWEEN
…delta.changeDataCapture.mapping.filter.value
the actual filter value
…delta.changeDataCapture.mapping.filter.highValue
specifies the upper value in case of a range in conjunction with .operator #BETWEEN or #NOT_BETWEEN
In some cases, a field for an explicit on-condition might be missing in one table, i.e. an additional constant value is used for determination of a unique record in the joined outer table.
This behavior is again illustrated based on CDS view Data Extraction for Sales Document Item (C_SALESDOCUMENTITEMDEX). The value for Business Partner function ShipToParty for a sales order (item) is stored in table SalesDocument: Partner (VBPA) with document number, item number and constant value ‘WE’ in key field Partner Function (PARVW).
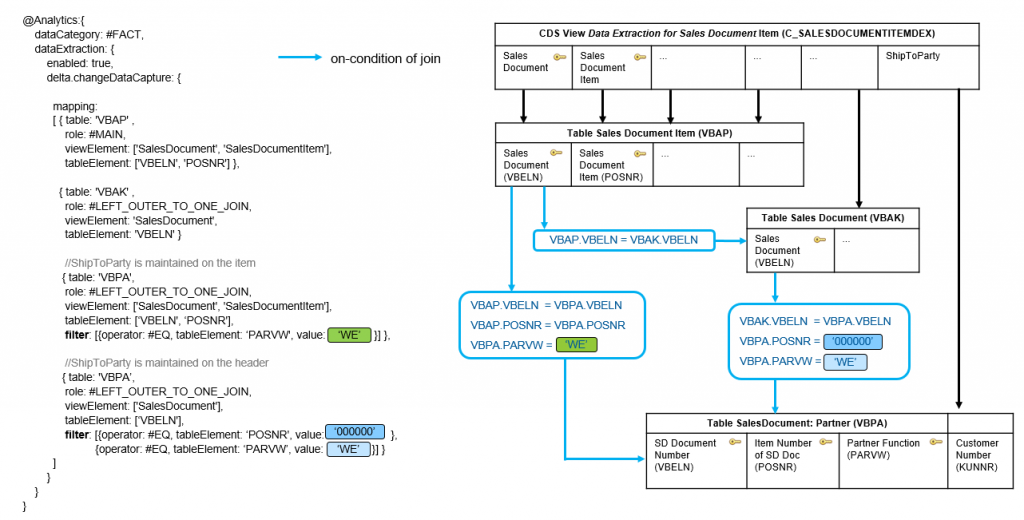
To complicate things the ShipToParty can either be maintained in the header document or individually directly on a sales order item level in the application.
Regarding the extraction, a ShipToParty maintained on the item overrules the one in the header document, evaluated by the COALESCE statement in the CDS view; similarly for the PayerParty and BillToParty.

If the ShipToParty is maintained on item level, the on-condition of the join between Sales Document: Item Data (VBAP) and SalesDocument: Partner (VBPA) consists of
- ? Sales Document Number (VBELN)
- ? Sales Document Item (POSNR)
- ? Constant value ‘WE’ for Partner Function (PARVW)

In this case a filter value for Partner Function (PARVW) is needed to uniquely determine the matching record in table SalesDocument: Partner (VBPA).
If the ShipToParty is maintained on header level, the on-condition of the join between Sales Document: Header Data (VBAK) and SalesDocument: Partner (VBPA) includes
- ? Sales Document Number (VBELN)
- ? Constant value ‘000000’ for Sales Document Item (POSNR)
- ? Constant value ‘WE’ for Partner Function (PARVW)
In this case a filter value for Sales Document Item (POSNR) AND Partner Function (PARVW) is needed to uniquely determine the matching record in table SalesDocument: Partner (VBPA).

If the ShipToParty is changed either on header or item level, a new delta record for this CDS view is generated.
Pheeew, that’s it…
What do we get on BW side now?
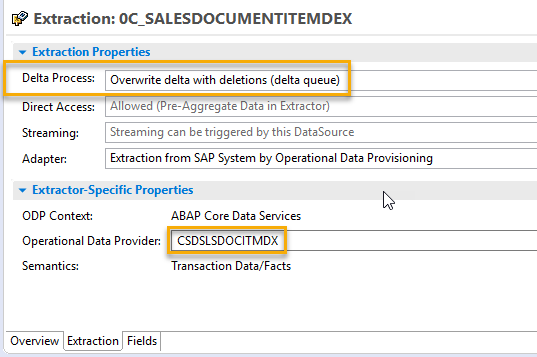
So let’s check this DataSource… Good news, SAP has started delivering out-of-the-box content for SAP BW/4HANA already. Let’s have a look at the delivered DataSource.
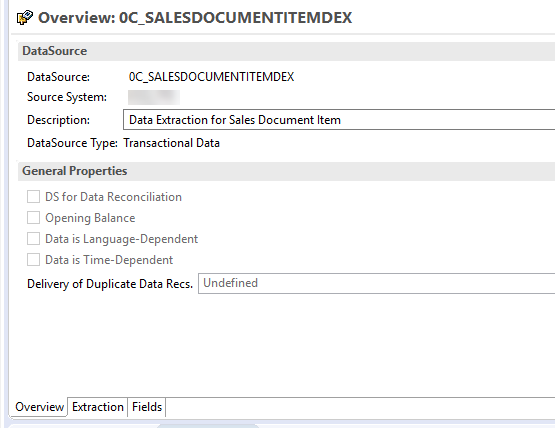
The interesting part is on tab Extraction
Delta Process, the DataSource is delta enabled and provides (overwrite) after images, which makes it easy to handle on BW side. And under Operational Data Provider we also spot the name of the @@AbapCatalog.technicalSQLView CSDSLDOCITMDX again.