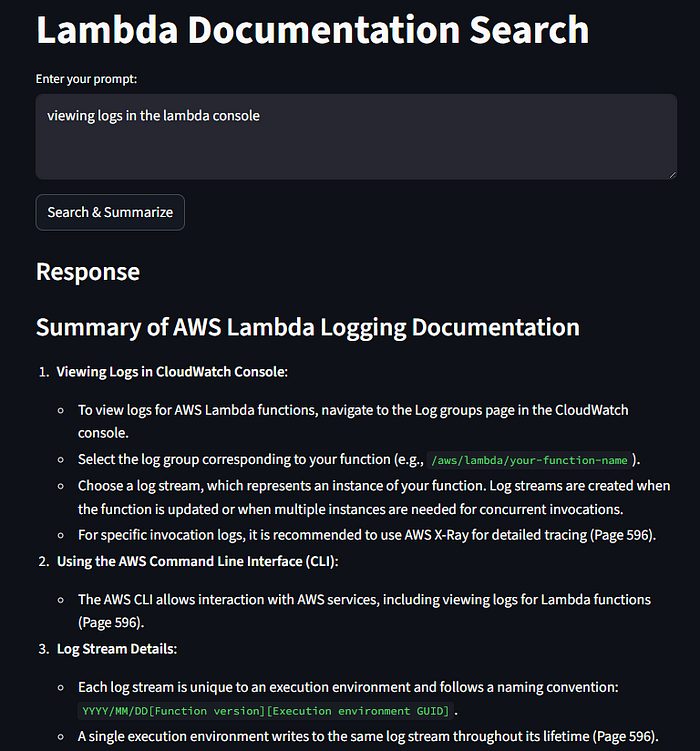
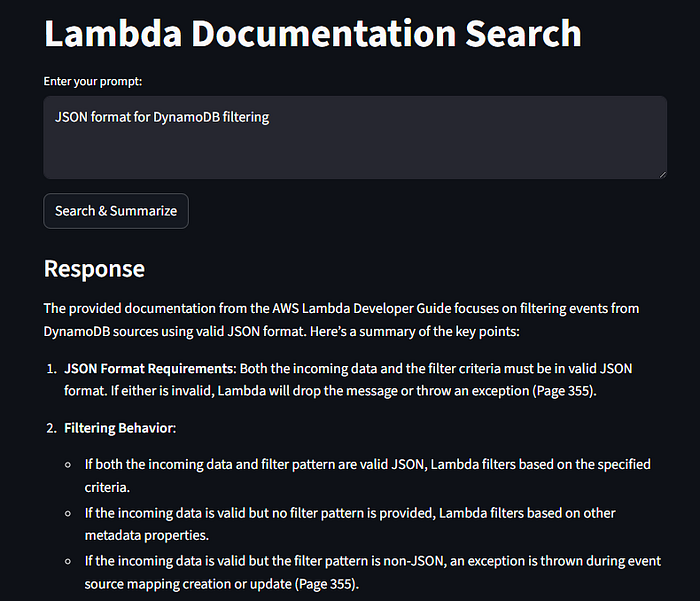
Retrieval-Augmented Generation (RAG) is a method for improving the output of large language models (LLMs). While LLMs are trained on vast amounts of data, they may lack access to proprietary or enterprise-specific information behind paywalls, or other custom data needed to generate accurate results. RAG supplements the LLM’s knowledge by retrieving relevant external information, making its outputs more accurate, relevant, and useful in a cost-effective way.
Key Challenges of LLMs Solved by RAG Bots
- Presenting False Information: LLMs can hallucinate when they lack the correct answer, often providing inaccurate responses that may appear convincing, which can lead to wrong decisions.
- Outdated Responses: LLMs are essentially prediction machines, generating answers based on their training data. As a result, they may provide outdated information if it falls beyond their knowledge cutoff.
- Terminology Differences: Natural languages like English, Spanish, or French are subjective, and the same term can have multiple meanings. LLMs may misunderstand context, leading to incorrect answers.
RAG bots address these challenges by supplementing LLMs with relevant, up-to-date information, making them a cost-effective and reliable way to enhance AI outputs.
To complete this project we will need
- Data not already accessible to the LLM: There’s no point in using widely known content, like Shakespeare’s plays, as the LLM likely already knows it.
- A Vector Database: In this example, we’ll use SAP HANA Vector Engine. Many options exist, including AWS vector engines and open-source alternatives. choose the one that fits your needs.
- A Python Environment: All code will be implemented in Python.
- An Embedding Model: Here, we use OpenAI’s embedding model, but any freely available model from Hugging Face or similar sources works.
What is a vector database? why do i need it? how does it differ from a real database?
Vector databases store data as mathematical representations called embeddings. Imagine visiting an ice cream shop you’ve been to a hundred times. On your 101st visit, a super-intelligent shopkeeper could instantly guess your preferred flavor based on your previous questions. That’s similar to how a vector database works.
Each piece of data is stored as an embedding, and when you ask a question, it’s converted into an embedding as well. The database then finds the part of your data that is most similar to your query. For example, if your question is meant to return the number 6, and the 12th paragraph of the 200th PDF is embedded as 5.8989898, the database will return it because it’s the closest match.
It’s crucial to embed information carefully. Using inaccurate data or poor embedding methods can result in irrelevant or excessive information being retrieved.
What are embeddings?
An embedding is a vector representation of data generated by an embedding model. In our setup, the model creates embeddings for your data, which are then stored in the HANA vector database. When you ask a question, it is also converted into an embedding, and the database compares it against the stored embeddings to find the most relevant matches.
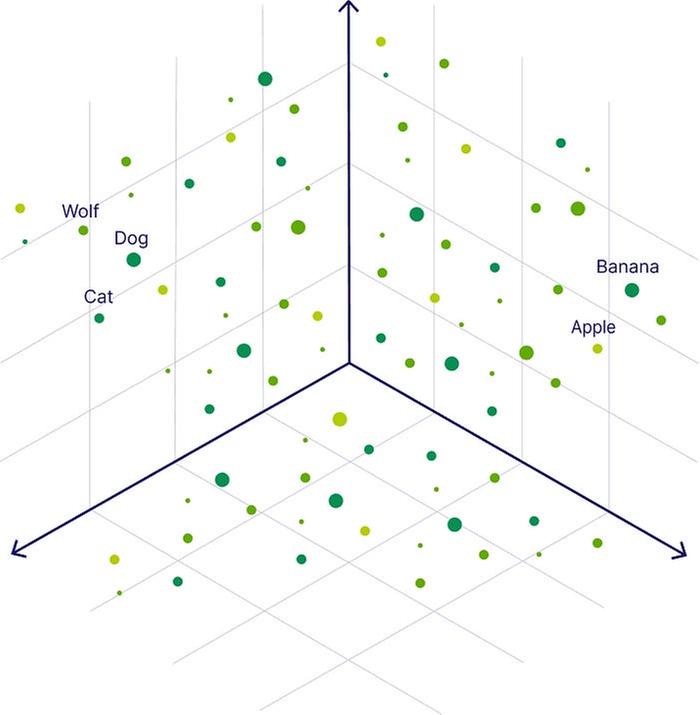
What vector embeddings looks like

start:
For my data i used this . It is a long 2000 page pdf on aws lambda.
First install these dependencies in your terminal
python-dotenv==1.0.1 # For reading environment variables stored in .env file
langchain==0.2.2
langchain-community==0.2.3
unstructured==0.14.4 # Document loading
# onnxruntime==1.17.1 # chromadb dependency: on Mac use `conda install onnxruntime -c conda-forge`
# For Windows users, install Microsoft Visual C++ Build Tools first
# install onnxruntime before installing `chromadb`Then import the following before proceeding
Step 1: Document Loading
At this point we have our database ready and we have set up our aicore model appropriately; now we can import our document.

Step 2: Splitting the documents
This is a crucial stage because how you split and chunk your documents directly affects the quality of results. Dividing documents into manageable segments allows the system to efficiently create accurate embeddings. When queried, these embeddings produce more precise responses.
Each chunk can also be enriched with metadata, such as page numbers or chapter titles. This helps locate the source if a deeper look is needed. Chunking must be done thoughtfully by headings, topics, or other logical divisions to ensure the system captures the content effectively.
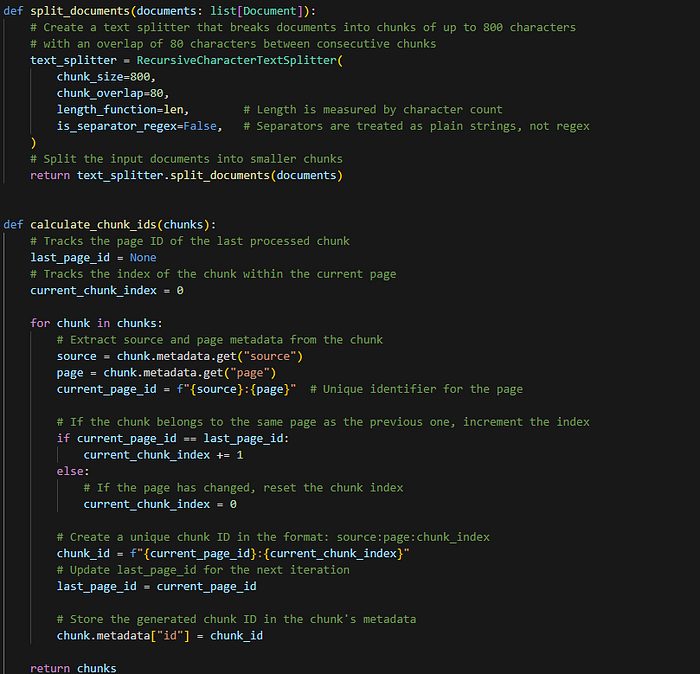
Step 3: Connect to database:
At this stage, we are ready to generate the embeddings and connect them to our HANA database or any other vector database we choose to use.
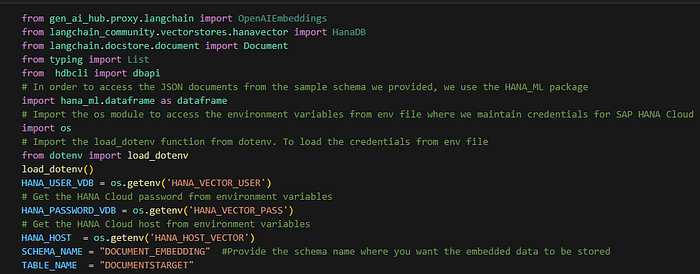
There are many resources on how to connect to hana, so for now i will leave this here.
Step 4: Access Embedding Model:

As explained earlier, an embedding model transforms complex, high-dimensional data into numerical values that machines can easily understand. This makes the data easier to process and allows ML models to identify patterns and relationships.
A vector is a one-dimensional representation of data containing multiple values. For example, a weather vector might be [2, 32, 1000], representing rain (2 = yes), temperature (32°F), and location (1000 = a specific county). Vectors capture relevant information depending on the type of data being represented.
Since this is a text embedding model, it can only create embeddings for textual data. This is important if you want to embed image files etc.
Step 5: Adding Data into HANA.
First, create the schema. You can do this by running a SQL query with the desired schema. This schema will hold the table where all your embeddings are stored.
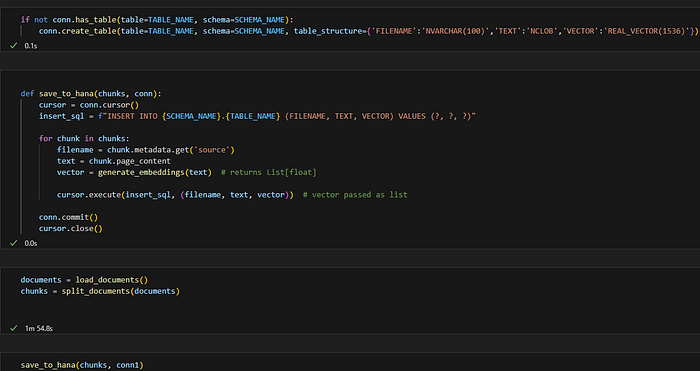
This code will create the table in your database, load your document, split it into chunks, and generate embeddings for each chunk.
When querying the data, your query is first transformed into an embedding and placed in the vector space. The vector database then returns the document chunks that are most similar to your query. This is why chunking is important: it ensures that the system can match your prompt accurately, typically using cosine similarity to find the closest matches.
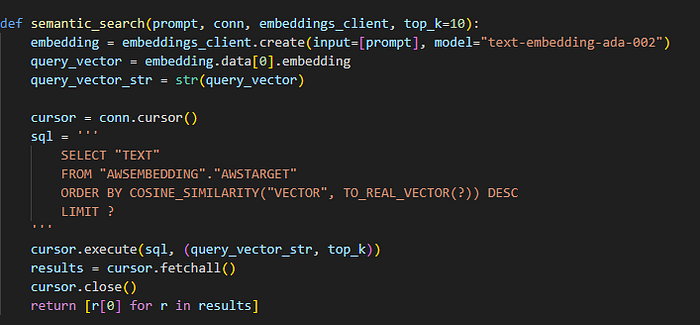
After integrating everything into a clean Streamlit UI, here is the final result.