High Availability for SAP HANA
High Availability is of the utmost importance mostly for production environments. In the case of a potential failure it will ensure that the systems remain accessible and the operations will continue while the issue is being resolved. If an outage occurs, there must be a robust system in place allowing a seamless failover to different hosts that will ensure the continuity of the service without the users, SAP jobs, etc., perceiving any disruption.
Automated failover of SAP HANA System Replication
The SAP HANA System Replication feature ensures that a HANA database is replicated in real-time to a different host (or a different group of hosts in a Scale-Out configuration), however, the failover process to the secondary host(s) is not automatic and needs manual intervention. If we want to automate this failover process so that the SAP Basis administrator can sleep at ease without fearing to be woken up in the middle of the night because the database is not available, we need to add a new layer on top of the SAP HANA System Replication. In this blog, we will see how to achieve this with the Red Hat Enterprise Linux High Availability Add-On that allows the creation of Pacemaker clusters for both the database and the application tiers. We will automate this cluster creation with Ansible.
Red Hat Enterprise Linux High Availability Add-On is accessible with the Red Hat Enterprise Linux for SAP Solutions subscription. The following scenarios are currently supported:
For SAP HANA Scale-Up implementations:
- Performance optimized. The database in the secondary node is an exact replica of the one in the primary node. The replication modes can be synchronous (if the secondary system has not acknowledged the persistent of the logs to disk after 30 seconds, the primary will resume its transactions), synchronous full sync (if the secondary system does not send an acknowledgement to the primary, this will not resume any transaction), synchronous in-memory (once the data is loaded in memory in the secondary node the primary resumes transactions without waiting till it is persisted to disk) and asynchronous.
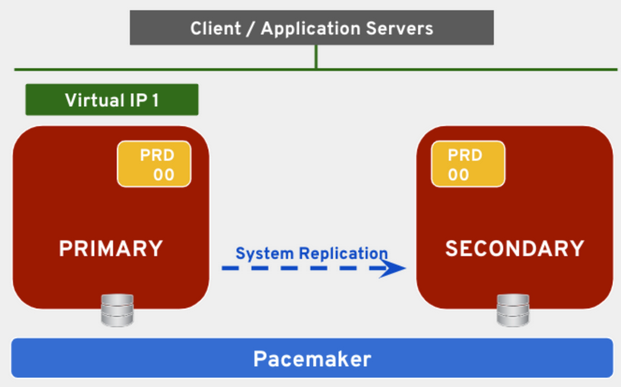
- Cost-optimized. In this scenario, the SAP HANA installation on the secondary node has a quality DB apart from the replica of the primary node’s production DB. This quality DB can be accessed while the replication of the production one takes place. In order to achieve this, 2 new IPs are needed, one for the production DB in the primary node and one for the quality DB in the secondary. In this case, the replication mode cannot be in-memory (since the resources are allocated to the quality DB) and will go directly to disk instead. In the case of fail-over, the quality DB has to be stopped first to allocate the resources to the production DB.
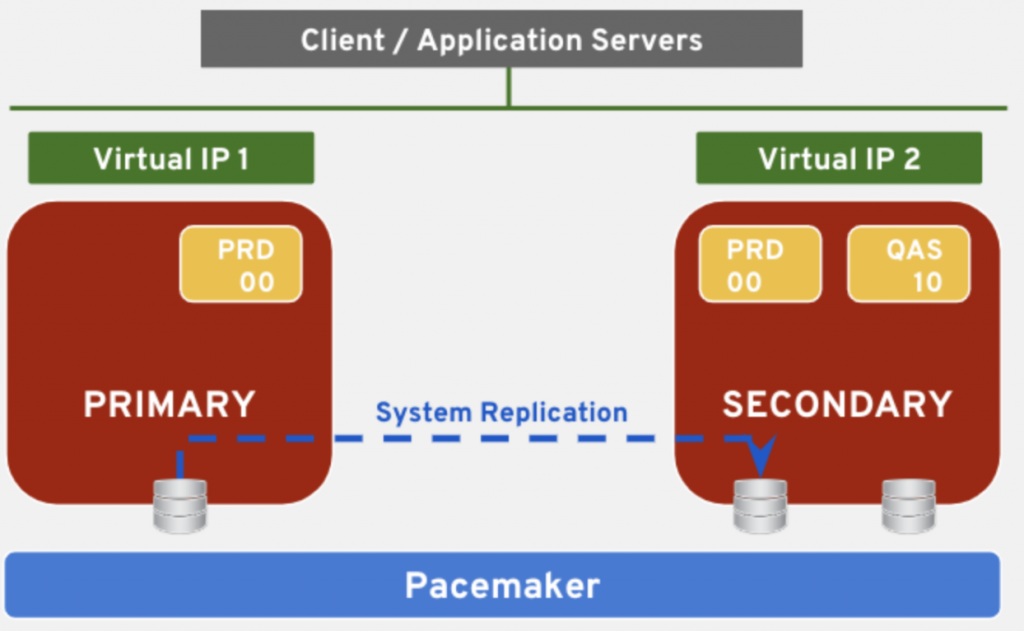
- Active-Active. One of the features introduced by SAP HANA 2.0 is the possibility of having a System Replication scenario where the DB in the secondary node can serve requests. In this case, also 2 new IPs are needed for each of the DBs.
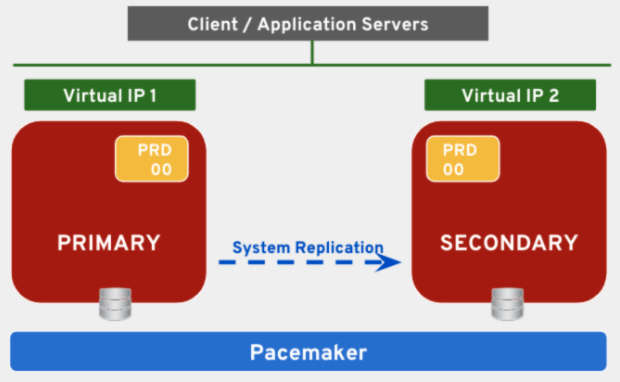
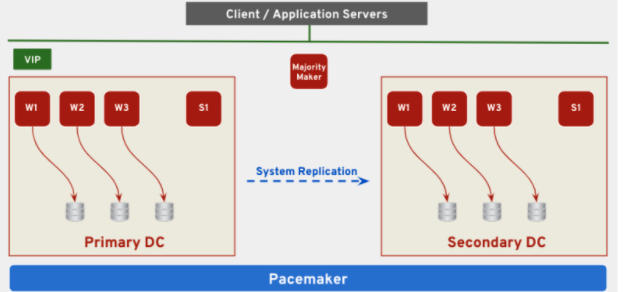
In SAP HANA Scale-Out implementations the cost-optimized scenario is supported with up to 32 nodes.
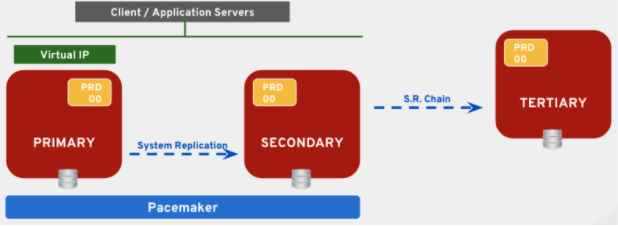
Replication chains are also supported by the Red Hat High Availability Add-On:
- Multi-tier replication. The DB in the primary node is replicated to the one in the secondary node and this one is also replicating to another DB in a tertiary node. In this case, the tertiary node has to be outside of the Pacemaker cluster. This scenario is supported in both Scale-Up and Scale-Out implementations.
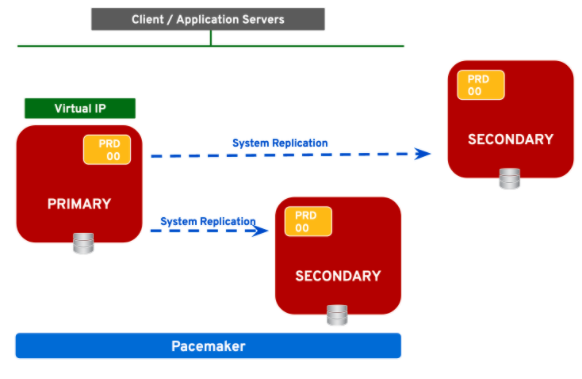
- Multi-target replication. The DB in the primary node is replicated to two different nodes at the same time. Only 2 of the DBs can be in the Pacemaker cluster. This scenario is supported in both Scale-Up and Scale-Out implementations.
On the application layer, the scenarios below are supported:
- For SAP S/4HANA 1809 or newer and SAP Netweaver 7.5 or newer the ENSA2 (Stand Alone Enqueue Server 2) is supported in both multi-node or 2 node clusters
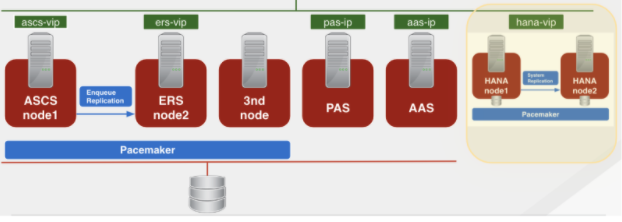
- For SAP S/4HANA 1709 and SAP Netweaver versions older than 7.5 the ENSA1 (Stand Alone Enqueue Server 1) is supported in 2 node clusters. Also, the ABAP/Java dual-stack is supported in Master/Slave configurations
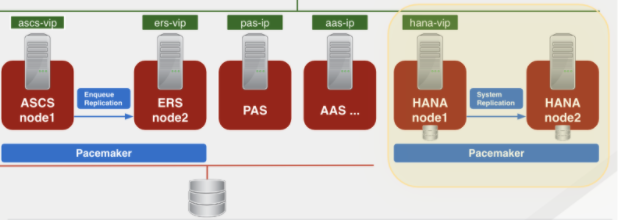
- Multi SID clusters. A single Pacemaker cluster can include up to 5 different SAP S/4HANA or SAP Netweaver installations

All the above scenarios are supported on-premise, as well as on private, public and hybrid clouds. Here are all the details about the support policies for the Red Hat High Availability Add-On
Using Ansible to deploy HA clusters for SAP HANA
We saw how we can automate the deployment of SAP HANA and SAP S/4HANA using Ansible. We will take it as starting point and we will add the automatic configuration of SAP HANA System Replication considering that we have deployed an SAP HANA Scale-Up scenario in two different hosts with the same SID and then we will also automate the creation of a 2 node Pacemaker cluster.
As a best practice, we will use a network for the communication of the two nodes of the cluster different from the network used for the SAP HANA System Replication (and from the one used to connect the SAP application tier if it exists with SAP HANA).
In our Ansible inventory, we will have the 2 hosts where we have deployed SAP HANA
$ cat hosts
[hana]
hana1
hana2In the group variable file (variables that are common to every host in the specific group) <ansible_base_directory> /group_vars/hana.yml we will include:
# Variables required for 'sap_hana_hsr' role
sap_hana_hsr_hana_sid: <HANA_SID>
sap_hana_hsr_hana_instance_number: "<HANA_instance>"
sap_hana_hsr_hana_db_system_password: "<SYSTEM_user_password>"
sap_hana_hsr_hana_primary_hostname: <primary_node_replication_name>
# Variables required for 'sap_hana_ha_pacemaker' role
sap_hana_ha_pacemaker_hana_sid: <HANA_SID>
sap_hana_ha_pacemaker_hana_instance_number: "<HANA_instance>"
sap_hana_ha_pacemaker_vip: <hana_resource_virtual_ip>
sap_hana_ha_pacemaker_hacluster_password: "<cluster_password>"And in the variable files particular to each host (<ansible_base_directory>/host_vars/hana1.yml and <ansible_base_directory>/host_vars/hana2.yml) we will include:
In <ansible_base_directory>/host_vars/hana1.yml# Variables required for 'sap_hana_hsr' role
sap_hana_hsr_role: "primary"
sap_hana_hsr_alias: "<node_alias_for_replication>" # for example DC1
# Variables required for 'sap_hana_ha_pacemaker' role
sap_hana_ha_pacemaker_node1_fqdn: <hana1_fqdn>
sap_hana_ha_pacemaker_node1_ip: <hana1_pacemaker_network_ip>And in <ansible_base_directory> /host_vars/hana2.yml
# Variables required for 'sap_hana_hsr' role
sap_hana_hsr_role: "secondary"
sap_hana_hsr_alias: "<node_alias_for_replication>" # for example DC2
# Variables required for 'sap_hana_ha_pacemaker' role
sap_hana_ha_pacemaker_node2_fqdn: <hana2_fqdn>
sap_hana_ha_pacemaker_node2_ip: <hana2_pacemaker_network_ip>The playbook for the whole E2E deployment of the two nodes SAP HANA Scale-Up with HANA System Replication and creation of the Pacemaker cluster will look like this:
cat plays/sap-hana-ha-deploy.yml
---
- hosts: hana
roles:
- { role: redhat_sap.sap_rhsm }
- { role: storage }
- { role: redhat_sap.sap_hostagent }
- { role: sap-preconfigure }
- { role: sap-hana-preconfigure }
- { role: redhat_sap.sap_hana_deployment }
- { role: redhat_sap.sap-hana-hsr }
- { role: redhat_sap.sap-hana-ha-pacemaker } In order for the Pacemaker cluster to be supported by Red Hat, a fencing resource needs to be created to avoid split-brain situations. Red Hat Enterprise Linux High Availability Add-On includes fencing resources for all the major hardware vendors, virtualization providers and hyperscalers. Depending on the infrastructure where our cluster will be created we will need to use a particular fencing resource and in the case of hyperscalers we will need to add additional steps to be able to use the SaaS fencing of the hyperscaler (e.g. creating a Service Principal on Azure and granting it the right role). This can be added as a new task file to the sap-hana-ha-pacemaker role (we would create it as a .yml file in the tasks directory of the role). For example, we create cluster-fencing.yml
---
- name: Install fencing agents
yum:
name: fence-agents-vmware-soap
state: present
- name: Set quorum votes
command: pcs quorum expected-votes 2
- name: Allow concurrent fencing
command: pcs property set concurrent-fencing=true
- name: Set fencing timeout
command: pcs property set stonith-timeout=900
- name: Create fencing device
command: >-
pcs stonith create {{ sap_hana_ha_pacemaker_fencing_device_name }}
fence_vmware_soap login={{ sap_hana_ha_pacemaker_fencing_username }} \
ipaddr={{ sap_hana_ha_pacemaker_fencing_ip }} \
passwd={{ sap_hana_ha_pacemaker_fencing_password }} \
pcmk_host_map=”{{ sap_hana_ha_pacemaker_node1_ip }}: \
{{ sap_hana_ha_pacemaker_node1_vm }};{{ sap_hana_ha_pacemaker_node2_ip }}: \
{{ sap_hana_ha_pacemaker_node1_vm }}” \
power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 \
pcmk_monitor_retries=4 pcmk_action_limit=3 \
op monitor interval=3600
- name: Enable fencing device
command: pcs property set stonith-enabled=trueAnd we will need to add this new task file to the main.yml file:
---
- import_tasks: eval-arch.yml
- import_tasks: enable-repos.yml
- import_tasks: software-setup.yml
- import_tasks: cluster-config.yml
- import_tasks: cluster-resources.yml
- import_tasks: cluster-fencing.ymlFinally we would add the value of the fencing variables to the group variables file ( <ansible_base_directory> /group_vars/hana.yml):
sap_hana_ha_pacemaker_fencing_device_name: <fencing_device>
sap_hana_ha_pacemaker_fencing_ip: <vCenter_IP>
sap_hana_ha_pacemaker_fencing_username: <fencing_device_username>
sap_hana_ha_pacemaker_fencing_password: <fencing_device_password>And to the server variable files <ansible_base_directory> /host_vars/hana1.yml :
sap_hana_ha_pacemaker_node1_vm: <hana1_vm_name>And <ansible_base_directory> /host_vars/hana2.yml :
sap_hana_ha_pacemaker_node2_vm: <hana2_vm_name>
This video shows how easily an end to end provisioning of a Pacemaker cluster for SAP HANA can be implemented with just one click using Red Hat Ansible Tower.