HANA has been the buzz word for quite some time and clients, big and small would eventually move to HANA, tomorrow if not today. So being an ABAPer, we need to be ready to accept the change and the challenges it would bring. With in-memory computing, the traditional do and not to do checklist would become redundant. We need to abreast ourselves with the new checklist. What was not advised in the pre-HANA era, might be the norm now. Technically there is not much change, but still, ABAPers need to make a conscious effort not to program in the traditional mindset. If we are not careful, we might not be able to harness the full power of the speed beast called HANA. Worse, we might even witness the negative speed impact because of the wrong implementation of custom codes in HANA.
Why SAP HANA? What ABAP developers need to understand and learn?
Gone are the days when an ABAP query would take a long time to execute in SAP due to a great volume of data and ABAP developers would require to extract these huge volumes of data from the database into the application layer and the then process this data and do data manipulation through coding. Developers were given instructions to avoid multiple tables joins from the database, concentrate on Key fields while data selection and avoid data calculations especially during select. All data calculations would be done at the application level in the program after data selection. Sometimes all data could not be selected due to limit on the volume of data during select and developer would require cursor statement to break the data volume into different data packages, update the internal table for output display and then select and process the next volume/package. Also, performance tuning of the data was a major activity required to minimize the execution time where large data volume of data was involved.
Now with the change of Traditional SAP Database to SAP HANA, one needs to understand how the previous ABAP development standards would take a U-turn and many checks followed previously would be irrelevant now. For this, one needs to understand the basic SAP HANA architecture for better coding practices.
SAP HANA is an in-memory data platform that can be deployed on premise or on demand and SAP HANA can make full use of the capabilities of current hardware to increase application performance, reduce the cost of ownership, and enable new scenarios and applications that were not previously possible.
So what is the key feature of this HANA Database that brought a change in the coding paradigm?
It’s the columnar database structure and in-memory processing that have changed the mindset of the basic ABAP coding concept. So now some of the earlier used data selection standards get changed and some existing becomes more pronounced.
Some of the basic standards to be followed are:
- SELECT * should be replaced with select with specific field names ->this was however applicable earlier for performance tuning, but now with the column based structure, this becomes more apparent.
- The SELECT statement with ‘CHECK’ should be avoided -> this was, however, applicable earlier, but now more apparent.
- While selecting data, maximum filtering of data should be done in the where clause. Earlier NE (inequality) was avoided, but now NE filtering is also advised. With the columnar database, all the columns act as an index, hence no secondary index creation is required to minimize execution time. Cursor statement is also not required. Delete after select also becomes redundant since almost all types of filtering can be done at one go.
- Apply all functions like sum, count, average etc in the SELECT itself and group them using ‘group by’.
- Instead of sorting after data selection like earlier, use ‘order by’ the fields required for sorting.
- Condition statements like ‘If’, ‘While’, Case’ etc can be applied directly during SELECT.
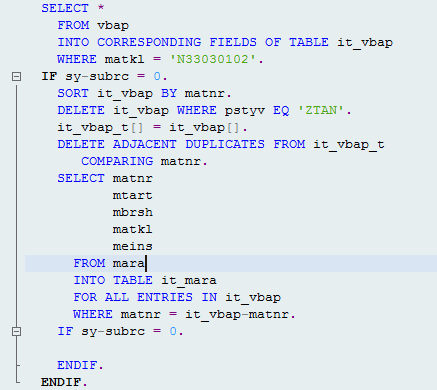
- Proper joining between tables are required to avoid unnecessary SELECTs and then ‘Loop’ and ‘Read table’ statements.
So basically what the above points imply that maximum selection and calculations can be done in one go during single SELECT itself instead of ‘SELECT’, ‘SELECT *** for all entries’, ‘Loop’, calculations like summation, condition like ‘If’ or ‘Case’ and ‘Append’ to internal table for final display. So now the lines of coding get reduced, but ABAP developers need to be more vigilant since more ABAP commands are being clubbed into one SELECT. Earlier each ABAP statement could be debugged to understand the issues or solve the defects. But now one needs to be more conscious of the commands being used and understand their implication.
Some more points which are also applicable, maybe to some specific requirement are as below.
- Since now its in-memory database, hence table buffering is not required, implying ‘BYPASSING BUFFER’ is irrelevant now.
- Database HINTs are to be avoided.
- Cluster table is not applicable now. So all previous cluster table like BSEG, MSEG usage should be avoided and treated as transparent tables.
- S/4 HANA brings in new tables and replaces some of the previous tables and made the tables in each functional area more structured like ACDOCA table in the finance area. This type of knowledge needs to percolate to the development layer.
Now, when any database moves to a HANA one, one must be curious as to what needs to be done and checked to HANATIZE the code?
Basically, if the above points are followed and statements changed accordingly, the previous ABAP coding can be converted to a HANA one.
Some more points which the new technology offers:
- SAP introduced new open-SQL statements with the top-down approach. ABAP developer should learn these practices and implement them during coding with HANA DB.
- Where common logic is applicable in the project deliverables, CDS views and AMDP procedures should be created instead of the earlier creation of subroutines in common includes.
Some examples of code changes for HANA database or HANATIZATION:
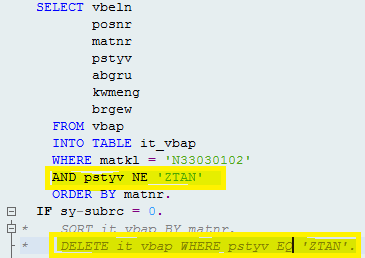
i. SELECT *:
Before:

After:
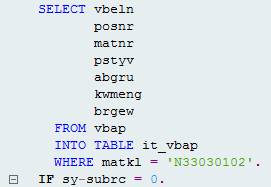
ii. SORT:
Before:
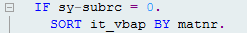
After:
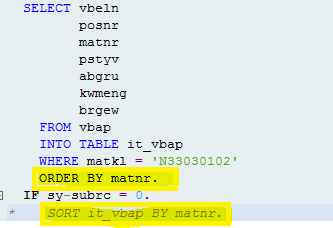
iii. DELETE:
Before:

After:
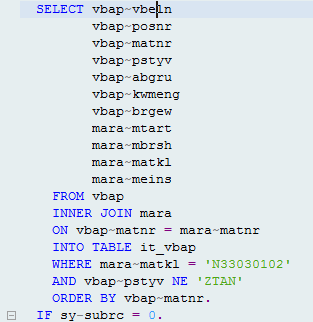
iv. JOIN:
Before:
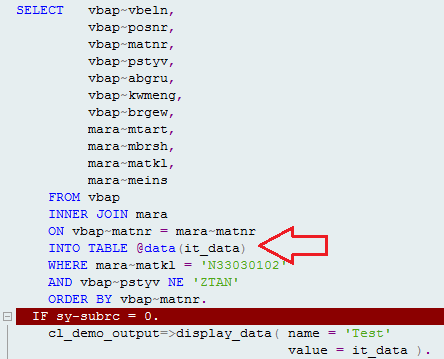
After:
v. New open-SQL(No data declaration is required): Inline data declaration is so convenient.
These are some of the points which would be used in each and every project. These are like alphabets of any language. We need to build complex sentences using these alphabets. But this is not the exhaustive list. Gradually in coming articles, we would try to put forth more points and checks which we might need to take care. We would also introduce the new tables which replace the clusters/pool tables in S/4 HANA.