Introduction
Anyone who has made a jump into the development of HANA native objects will come across graphical Calculation Views (CV) very soon. On the one hand, they offer easy handling because they work with very few basic elements (projection, union, join, aggregation and ranking). On the other hand, they offer high processing speed because all operations are directly performed on database level. To further increase the processing speed, we can dynamically limit the amount of data to be processed using input parameters (IP). In this article we will deal with the five different types of input parameters:
Scenario
I will use the small data model dealing with flights provided by SAP, because it’s available in all systems, it is very small and only very few tables are involved:
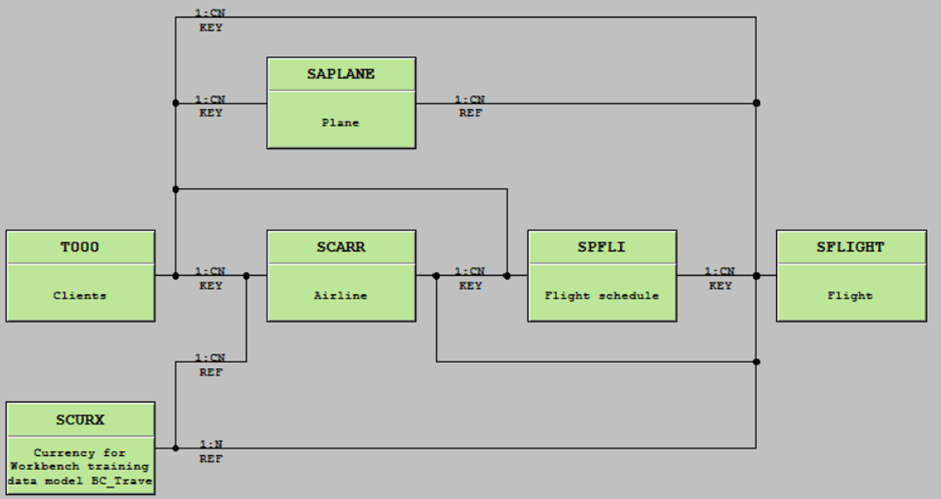
The target calculation view will present some flights based on several selection criteria implemented via input parameter.
The general procedure follows these steps:
- Create input parameter with settings required
- Apply filter to column using input parameter or use it within calculated columns
Step 1: open the dialog to create a new input parameter:
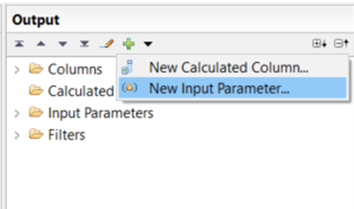
and select the parameter type you need:
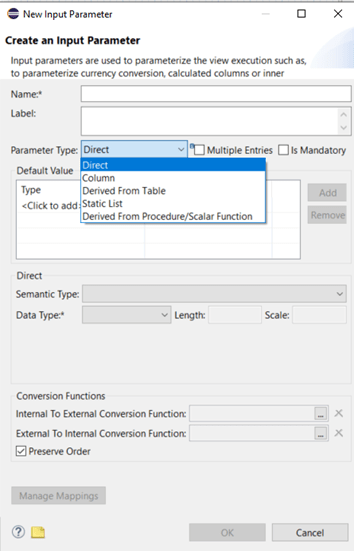
Usually you can decide whether a parameter is mandatory or not (default setting) and you can allow multiple entries. The default value is optional, too, but will be used, in case the calculation view is executed within a situation where no user interaction is possible (like a transformation). You can either enter a fix default value or use a small subset of system values and functions to calculate it dynamically. All these aspects are not important when we discuss the different parameter types, so I will not come back to them.
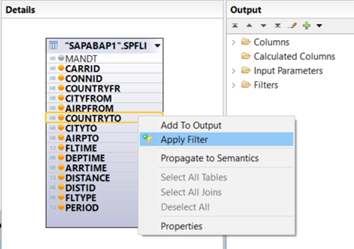
Once you made all your settings to the new input parameter (IP), you can use the IP by applying a filter to a column of your CV or use it within a calculated column:
Type: Direct
With this direct type you only define the semantic and data type of an IP. There is no option to control or verify the value a user has entered.
In order to create one, set a technical name and label for your new input parameter, select type “Direct” and define a helpful default value:
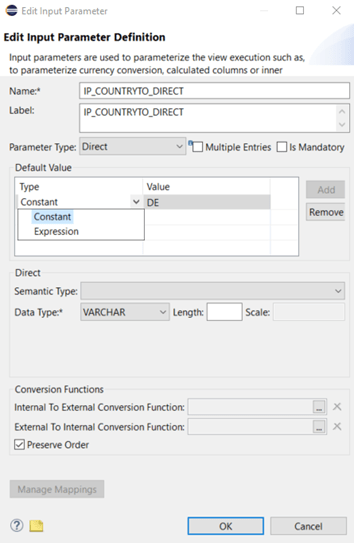
In this example there is no semantic type like currency or date:
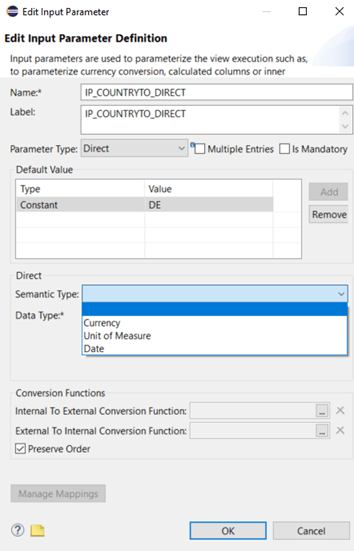
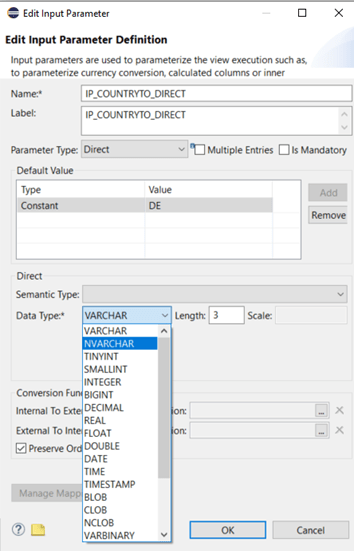
Finally we have to select a data type and length. Here we should use the same type and length, the corresponding column we want to restrict, has. In this way we avoid any negative impact through casting or conversion overhead.
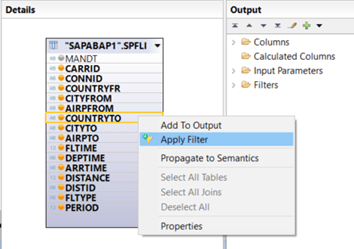
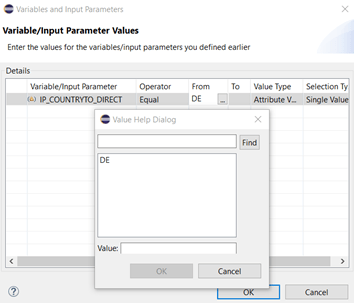
Great, we created our input parameter IP_COUNTRYTO_DIRECT with parameter type “Direct” and now we want to use it with column COUNTRYTO in order to select data. We select the node based on table SPFLI and apply a filter to column COUNTRYTO:
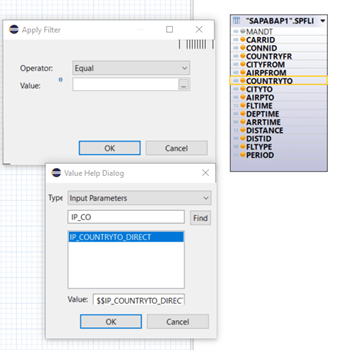
Using the value help dialog we switch from fixed values to input parameters and select our IP we just created. Check out the strange looking syntax: there are “$$”-signs at the beginning and end of the technical name.
Starting the data preview of our CV will lead to the expected result: now that we use an input parameter, a data entry screen is shown and we see the default value of our input parameter but no additional values in the value help dialog:
Type: Column
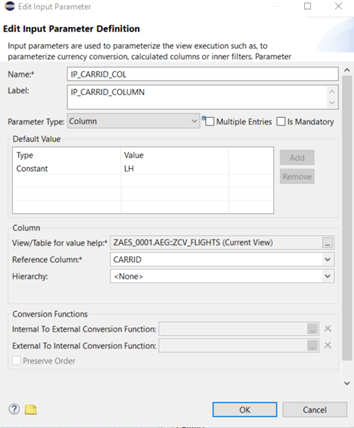
With this column type we can use a view or database table for the value help of our input parameter. It is possible to use the calculation view we are just working with like a “myself” connection! But in this case we get an empty list for the value help. Not a good idea, but there are no values, because we did not execute the CV in the moment we ask the user to fill out our IP.
Once we selected the reference column of the view or table we are ready to go. There is no need to define the datatype and length manually:
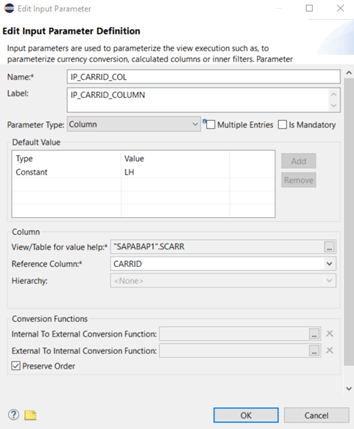
Instead of using the current (“myself”) view, we can switch to any other view or table! This setting is very similar to the parameter type “Derived from table”, we will see in the next chapter:
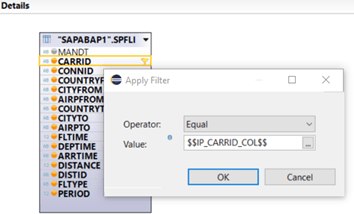
We have to assign the input parameter IP_CARRID_COL to the column CARRID of our projection node, so that users can enter their selection and system is using the filter criteria:
Starting the data preview of our CV will lead to the expected result: a data entry screen is shown and we see the default value of our IP but no additional values in the value help dialog, because the calculation view has not yet been executed:
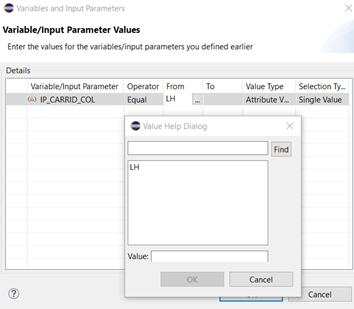
This type of parameter allows us to use multiple entries, so let’s find out, what is happing to the default value section and filter assignment.
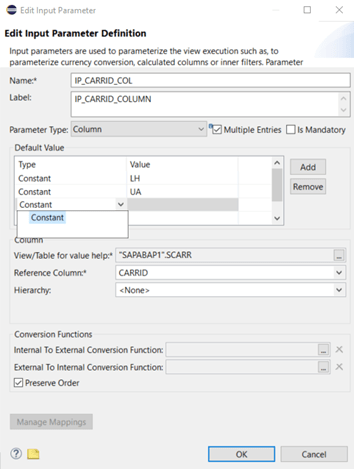
Once we select the “Multiple Entries” flag, we get the option to add additional default values. As you can see in Figure 17: multiples entries and default values, we cannot mix defaults based on “Constant” and “Expression”.
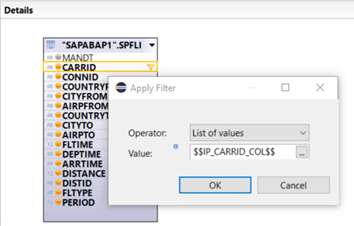
Having an input parameter that allows multiple entries, we have to double check the filter settings. The operator “Equal”, we are using right now, is valid for single values, only. We have to edit the filter definition and select the operator “List of Values”:
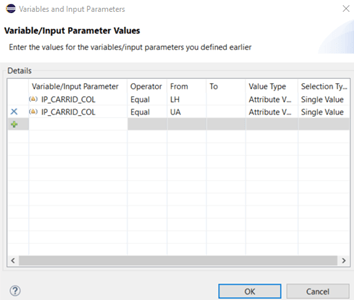
Starting the data preview again, will lead to a modified selection screen, where we can add or remove default values:
Type: Derived from table
With this parameter type we can use a database table for the value help of our input parameter. If we set our IP to input enabled, a user can select his value out of a list of valid records. This is the difference compared to parameter type column: here we can define filter criteria in order to restrict the number of valid records within our reference table! The second difference is the option to use multiple entries: here we can only work with single values, means we have less flexibility in this point of view.
We can use one or more columns out of the reference table that are different, related to the result column: the example should select all plane types out of the table SAPLANE where the producer of the plane is “A”:
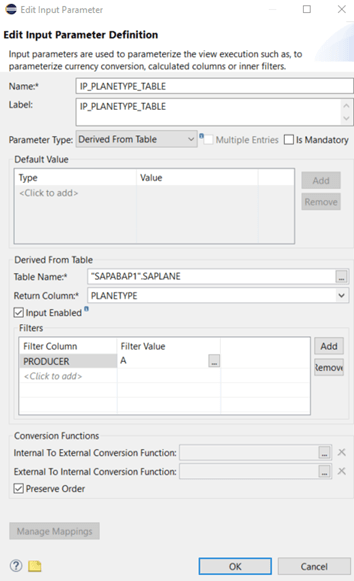
Starting the data preview of our CV will lead to a calculated default value for PLANETYPE of “A310-200”. This is indeed the correct value, because we have the following list of planes from producer A:
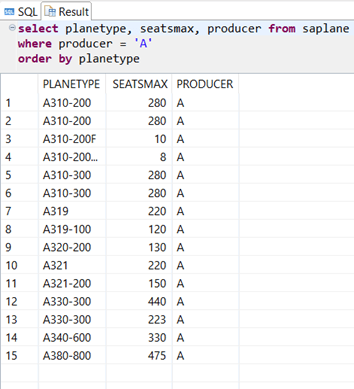
When we use the value help for our input parameter the result list is no longer restricted to our filter, we can select all values available in table SAPLANE!
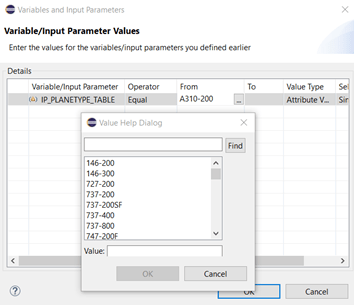
Now let’s try to get a different default value by enhancing the filter restriction in our IP: we want to find a plane with a specific number of seats available. One solution is to add the filter column SEATSMAX and a value of 220. But we can also use an input parameter to define the filter value! In this very simple example I created an IP with parameter type DIRECT and data type INTEGER. I set the default value to 220 and use the special syntax to define my filter value:
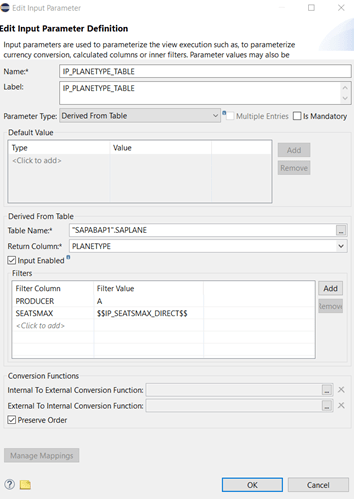
When we start a data preview, we get a different default value for our input parameter IP_PLANETYPE_TABLE: “A319”. But the value help is still offering all values in table SAPLANE:
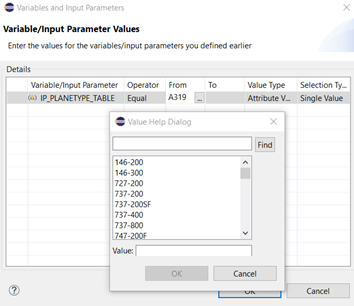
Type: Static List
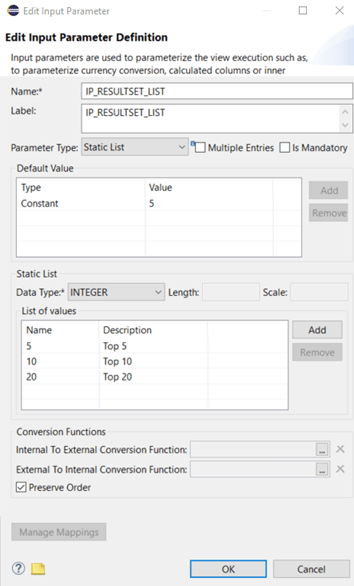
With this column type we define the list of valid values on our own. We simply put all valid values into a list. Here I created an example where the IP can be used with a ranking node in order to select the top x records and user only has a very short list of valid values.
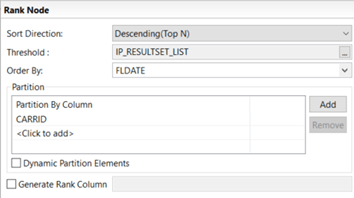
Now we can use the IP within the details of a ranking node where we set the threshold:
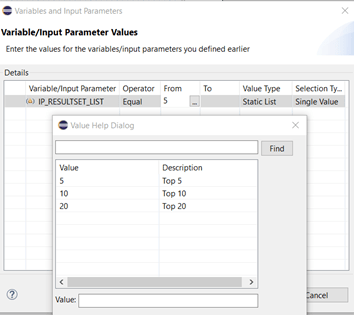
Starting the data preview of our CV will give us the chosen default and the defined value help:
Type: Derived from procedure
This parameter type is giving us the greatest flexibility to calculate our default value. Using a database procedure allows us to select data from all database tables we have permissions to read from. We have to specify the database procedure name but no datatype and length. This information is coming from the procedure declaration:
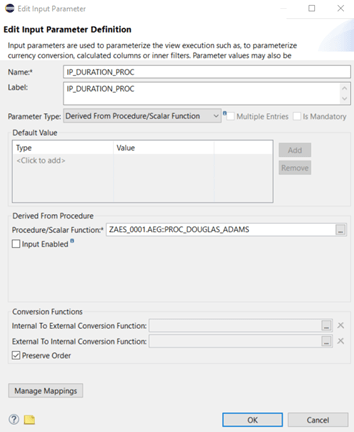
In order to write a database procedure we have to switch to a new perspective: SAP HANA Development. Before we go ahead, we have to set the correct codepage used for the text files that store our coding lines in Eclipse. We reach out to the preference settings from the “Window”-menu and maintain the workspace settings as shown below:
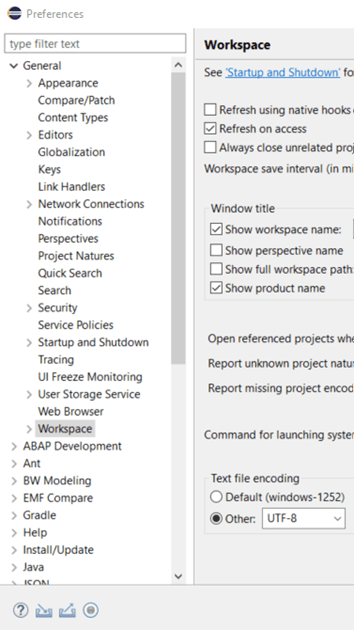
I have to select “UTF-8” in order to avoid any complications when writing lines of code within the editor.
Within the “Repositories”-Tab we select the target package and open a database procedure template out the group “Other…”:
The wizard offers a lot of templates but we search for a procedure template:
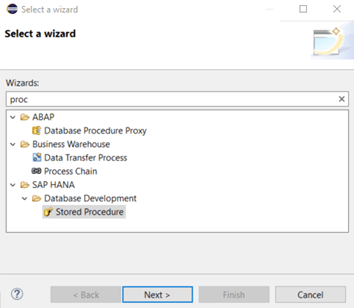
Now we define the file name and database schema of our new procedure:
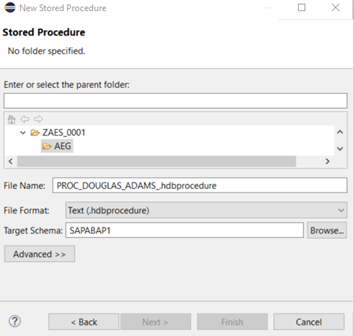
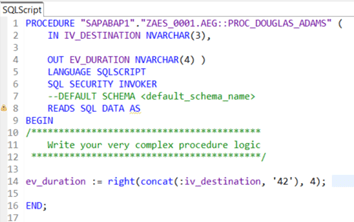
The new procedure is opened in the editor and we see some coding generated by the template we selected. We have the technical name of our procedure and see the schema it will be created in, once we activate our coding. The language definition is set to SQLSCRIPT so that we can start to define the input and output variables of our procedure. By setting the datatype and length of the output variable, we define the data type and length of the input parameter. In this example we add an input variable as well in order to point out a specific detail of parameter handling in a calculation view.
As I mentioned before, we now can write the most complex coding, using hundreds of tables we select data from in order to calculate our result value. In this example I reduced that complexity down to one single line of code giving a result of the most famous value 42.
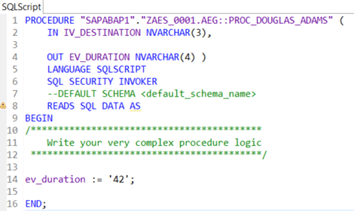
Once we activated our new database procedure we go back to our calculation view and create a calculated column “CC_ADAMS” in the top aggregation node, that will use our input parameter. The datatype and length of the calculated column should match the type and length of the output variable we defined within the database procedure.
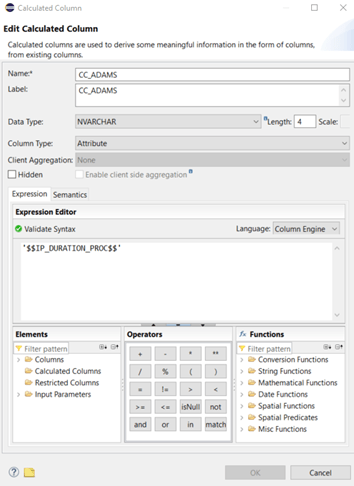
Because we defined an input variable in our procedure we have to find a way to feed this variable out of our calculation view! The place to do this is on the semantic node in the “Parameters/Variables”-tab:
Here we can manage the mapping between input parameters of our calculation view and the input variables of the database procedure:
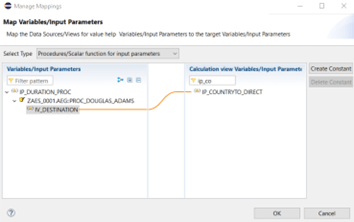
Finally we activate our calculation view having a calculated column “CC_ADAMS” that gets data from an input parameter getting data from a database procedure:
Did you notice that we defined an input variable and map it within the calculation view but we do not work with that input variable within our database procedure! So let’s enhance our complex coding in a way that is combining procedures input variable IV_DESTINATION with the magic constant value:
Please be aware, that we do not have to change our calculation view. We can change the result of the CV just by changing the logic in our procedure.
The second enhancement to our calculation view is the definition of another input parameter IP_DURATION_SF: here we use a scalar function without any input variables.
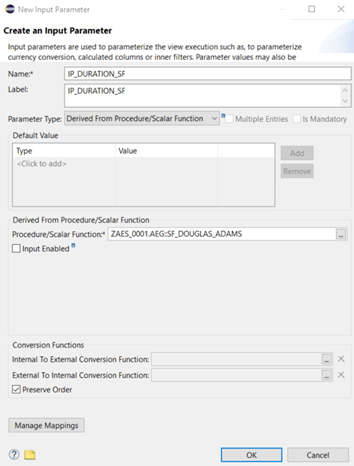
The scalar function we need has a very complex logic, too: whatever we do, the result is always 42.
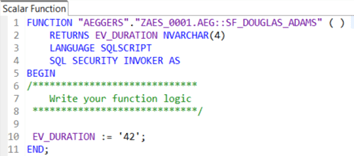
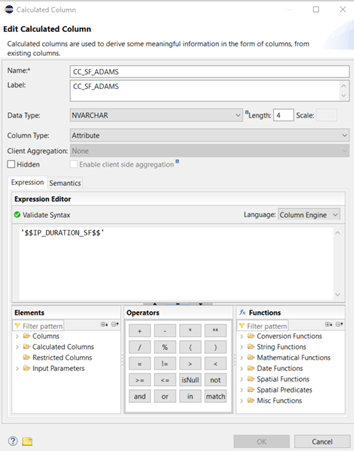
In the aggregation node of the calculation view we add a new calculated column “CC_SF_ADAMS” that gets information from the new IP IP_DURATION_SF. Datatype and length should match with the definition of the return value of the scalar function:
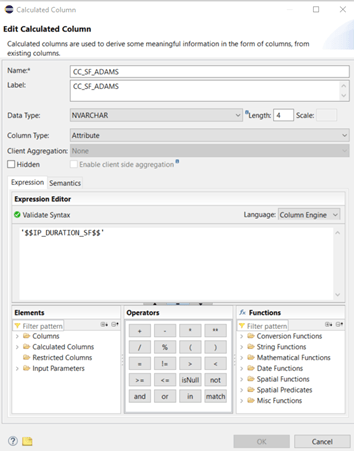
Finally we check the mapping of our input parameters again but there are no changes, because the new IP does not have any input variables:
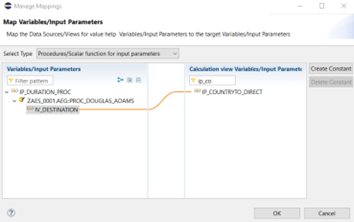
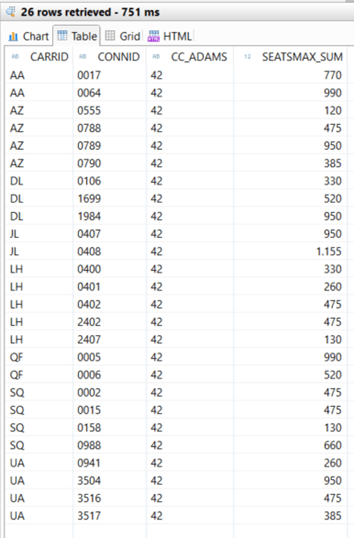
In the end we activate the calculation view, check the data preview and focus on both calculated columns. “CC_ADAMS” now shows the concatenated values of the selected country and ‘42’, whereas “CC_SF_ADAMS” shows ‘42’, only:
Summary
Ok, these are the five shades of parameter types. We saw a wide range of complexity and effort, required to create them. “Static List” and “Direct” are very easy to create and complexity is very low. Type “Column” and “Derived from table” increase complexity and give access to all database tables and views, but are still very easy to create. On top of complexity and effort, we find parameter type “Derived From Procedure/Scalar Function”. It is hard to find a limit when thinking about the effort and complexity to create such an input parameter.
Finally I want to give you some more ideas, where to use input parameter, but of cause, there are so much more:
| Scenario | Parameter type |
|---|---|
| Select time dependent data records, valid on a specific date | “Direct”, use a dynamic default value to calculate current date / last day of last month / first day next year / … |
| Select data, younger than last closed period | “Column” or “Derived from Table” where you maintain a customer individual parameter table to store such information |
| Simulate amounts or quantities based on user input of scaling factors | “Direct”, use numeric input parameter in calculated columns |
| Select business partner or products of a certain category | “Static List”, list of valid categories |
| Calculate amounts or quantities of a peer group | “Derived From Procedure/Scalar Function”, select relevant data of peer group and calculate reference value |
| So much more … |
Table 1: Where to use input parameter
Now that you know the technical part and see some use cases, it is up to you to enhance your calculation views with input parameters.